







Warning内容
Warning: grad and param do not obey the gradient layout contract. This is not an error, but may impair performance.
grad.sizes() = [512, 256, 1, 1], strides() = [256, 1, 1, 1]
param.sizes() = [512, 256, 1, 1], strides() = [256, 1, 256, 256] (function operator())
首先,这个 warning 不解决对程序执行下去没有影响,但强迫症们必须解决!!
Warning 环境:单机多卡训练代码时,仅在第二个 epoch 会抛出该 warning,其余 epoch 均正常。当使用一张卡训练时,不会抛出该 Warning。经过 debug 调试,发现在第二个 epoch 的 loss.backward() 语句执行时会抛出该警告。
Warning 原因:在 model 推理过程中,tensor 不连续。
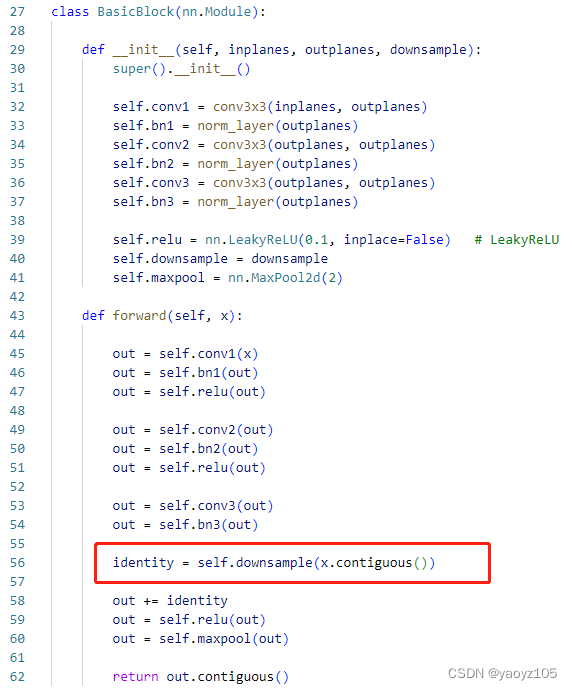
Debug 过程:笨办法,看 model 的 forward 函数里哪个步骤可能会导致 tensor 不连续,最终定位到我的 backbone 网络(ResNet)中的 残差连接下采样,也就是下面代码的 identity = self.downsample(x),给输入 x 加上 .contiguous() 变成 identity = self.downsample(x.contiguous()) 后,Warning 消失啦!
其他解决方案
在 这个讨论 下还找到了一些潜在的解决方案,第一个方法尝试过之后对我的情况无效,但可以作为大家的备选方案!
方法一:给网络模型中的 ReLU() 加上 inpalce=Flase。

方法二:如果是自己初始化网络参数的,需要注意下面这个人说的情况。

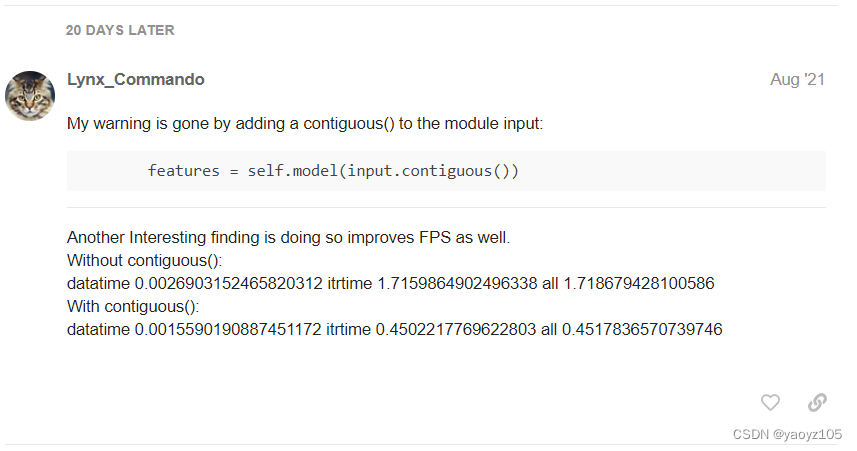
方法三:这里提供的方法解决了我的 Warning,但他是给 model 的 input 使用 .contiguous,并不适合每个人,需要根据自己情况找到抛 warning 的地方。就如 2022 年高考作文题目,红楼梦第十七回 大观园试才题对额 的情景,众人给匾额题名,或直接移用,或借鉴化用,或根据情境独创,产生了不同的艺术(debug)效果😃。


















 2850
2850

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











