






一、引言
长短期记忆网络(LSTM,Long Short-Term Memory)是一种时间循环神经网络,是为了解决一般的RNN(循环神经网络)存在的长期依赖问题而专门设计出来的。长短期记忆网络论文首次发表于1997年。由于独特的设计结构,LSTM适合于处理和预测时间序列中间隔和延迟非常长的重要事件。LSTM的表现通常比时间递归神经网络及隐马尔科夫模型(HMM)更好,比如用在不分段连续手写识别上。2009年,用LSTM构建的人工神经网络模型赢得过ICDAR手写识别比赛冠军。LSTM还普遍用于自主语音识别,2013年运用TIMIT自然演讲数据库达成17.7%错误率的纪录。作为非线性模型,LSTM可作为复杂的非线性单元用于构造更大型深度神经网络。[百度百科]
二、LSTM的基本原理
请参考以下博客:
https://blog.csdn.net/qq_51467258/article/details/136597769
三、LSTM在特定任务中的应用实例
(1)时间序列预测
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM
# 加载数据
df = pd.read_excel('1.xlsx') # 确保你有一个包含时间序列数据的1.csv文件
data = df['value'].values # 假设数据在名为'value'的列中
data = data.reshape(-1, 1)
# 归一化数据
scaler = MinMaxScaler(feature_range=(0, 1))
scaled_data = scaler.fit_transform(data)
# 分割训练和测试数据
train_size = int(len(scaled_data) * 0.8)
train_data, test_data = scaled_data[:train_size], scaled_data[train_size:]
# 创建数据集函数
def create_dataset(dataset, time_step=1):
X, y = [], []
for i in range(len(dataset) - time_step - 1):
X.append(dataset[i:(i + time_step), 0])
y.append(dataset[i + time_step, 0])
return np.array(X), np.array(y)
time_step = 10
X_train, y_train = create_dataset(train_data, time_step)
X_test, y_test = create_dataset(test_data, time_step)
# 调整输入数据的形状
X_train = X_train.reshape(X_train.shape[0], X_train.shape[1], 1)
X_test = X_test.reshape(X_test.shape[0], X_test.shape[1], 1)
# 构建LSTM模型
model = Sequential()
model.add(LSTM(50, return_sequences=True, input_shape=(time_step, 1)))
model.add(LSTM(50, return_sequences=False))
model.add(Dense(25))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mean_squared_error')
# 训练模型
model.fit(X_train, y_train, batch_size=1, epochs=1)
# 进行预测
train_predict = model.predict(X_train)
test_predict = model.predict(X_test)
# 逆归一化预测值
train_predict = scaler.inverse_transform(train_predict)
test_predict = scaler.inverse_transform(test_predict)
# 逆归一化实际值
y_train = scaler.inverse_transform([y_train])
y_test = scaler.inverse_transform([y_test])
# 计算均方误差(MSE)
import math
from sklearn.metrics import mean_squared_error
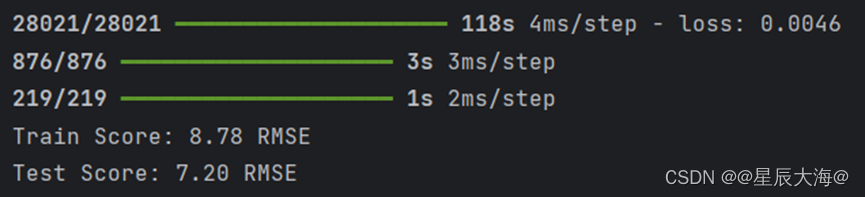
train_score = math.sqrt(mean_squared_error(y_train[0], train_predict[:, 0]))
print(f'Train Score: {train_score:.2f} RMSE')
test_score = math.sqrt(mean_squared_error(y_test[0], test_predict[:, 0]))
print(f'Test Score: {test_score:.2f} RMSE')
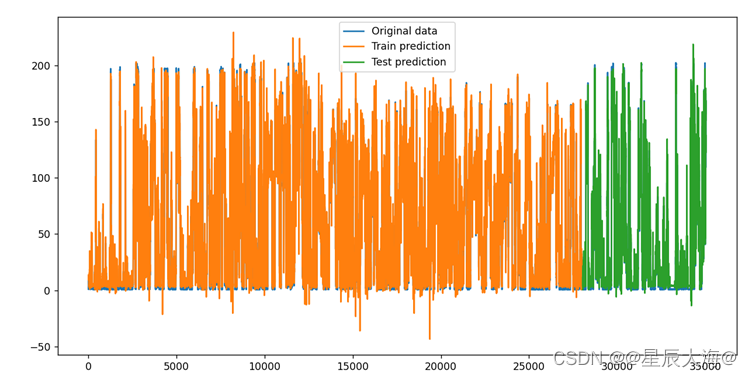
# 可视化结果
train_predict_plot = np.empty_like(data)
train_predict_plot[:, :] = np.nan
train_predict_plot[time_step:len(train_predict) + time_step, :] = train_predict
test_predict_plot = np.empty_like(data)
test_predict_plot[:, :] = np.nan
test_predict_plot[len(train_predict) + (time_step * 2) + 1:len(data) - 1, :] = test_predict
plt.figure(figsize=(12, 6))
plt.plot(scaler.inverse_transform(scaled_data), label='Original data')
plt.plot(train_predict_plot, label='Train prediction')
plt.plot(test_predict_plot, label='Test prediction')
plt.legend()
plt.show()
结果如下图所示
(2)分类
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import LabelEncoder, MinMaxScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, classification_report
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM
from tensorflow.keras.utils import to_categorical
# 加载数据
df = pd.read_excel('1.xlsx') # 确保你有一个包含时间序列数据的1.xlsx文件
# 假设特征列为feature1, feature2,...,featureN,目标列为target
features = df[['feature1', 'feature2', 'feature3']] # 根据实际列名修改
target = df['target']
# 归一化特征数据
scaler = MinMaxScaler(feature_range=(0, 1))
scaled_features = scaler.fit_transform(features)
# 标签编码
encoder = LabelEncoder()
encoded_target = encoder.fit_transform(target)
categorical_target = to_categorical(encoded_target)
# 分割训练和测试数据
X_train, X_test, y_train, y_test = train_test_split(scaled_features, categorical_target, test_size=0.2, random_state=42)
# 调整输入数据的形状
time_step = 10 # 设定时间步长
def create_dataset(X, y, time_step=1):
Xs, ys = [], []
for i in range(len(X) - time_step):
v = X[i:(i + time_step)]
Xs.append(v)
ys.append(y[i + time_step])
return np.array(Xs), np.array(ys)
X_train, y_train = create_dataset(X_train, y_train, time_step)
X_test, y_test = create_dataset(X_test, y_test, time_step)
# 构建LSTM模型
model = Sequential()
model.add(LSTM(50, return_sequences=True, input_shape=(time_step, X_train.shape[2])))
model.add(LSTM(50))
model.add(Dense(25, activation='relu'))
model.add(Dense(y_train.shape[1], activation='softmax')) # 输出层根据分类数设置激活函数
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(X_train, y_train, batch_size=32, epochs=10, validation_split=0.2)
# 评估模型
loss, accuracy = model.evaluate(X_test, y_test)
print(f'Test Accuracy: {accuracy:.2f}')
# 进行预测
predictions = model.predict(X_test)
predicted_classes = np.argmax(predictions, axis=1)
true_classes = np.argmax(y_test, axis=1)
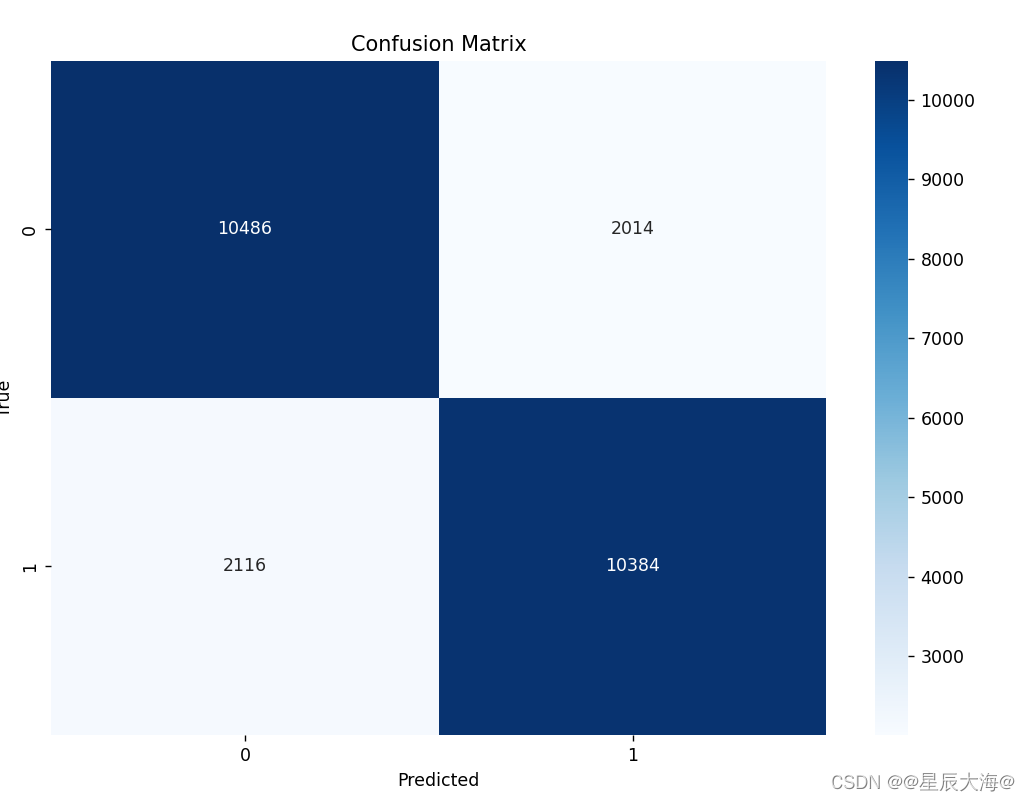
# 混淆矩阵
cm = confusion_matrix(true_classes, predicted_classes)
plt.figure(figsize=(10, 7))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.xlabel('Predicted')
plt.ylabel('True')
plt.title('Confusion Matrix')
plt.show()
# 分类报告
report = classification_report(true_classes, predicted_classes)
print(report)
(3)情感分析
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, classification_report
import seaborn as sns
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM, Embedding, SpatialDropout1D
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.datasets import imdb
# 设置参数
max_features = 20000 # 使用的词汇表的最大数量
max_len = 100 # 每条评论的最大长度
# 加载IMDb数据集
(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words=max_features)
# 填充序列使其具有相同的长度
X_train = pad_sequences(X_train, maxlen=max_len)
X_test = pad_sequences(X_test, maxlen=max_len)
# 构建LSTM模型
model = Sequential()
model.add(Embedding(max_features, 128, input_length=max_len))
model.add(SpatialDropout1D(0.2))
model.add(LSTM(100, dropout=0.2, recurrent_dropout=0.2))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# 训练模型
history = model.fit(X_train, y_train, epochs=5, batch_size=64, validation_split=0.2, verbose=2)
# 评估模型
loss, accuracy = model.evaluate(X_test, y_test)
print(f'Test Accuracy: {accuracy:.2f}')
# 进行预测并生成混淆矩阵和分类报告
y_pred = (model.predict(X_test) > 0.5).astype("int32")
# 混淆矩阵
cm = confusion_matrix(y_test, y_pred)
plt.figure(figsize=(10, 7))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.xlabel('Predicted')
plt.ylabel('True')
plt.title('Confusion Matrix')
plt.show()
# 分类报告
report = classification_report(y_test, y_pred, target_names=['Negative', 'Positive'])
print(report)
四、总结与展望
LSTM模型应用极为广泛,主要应用场所为: 文本生成、机器翻译、语音识别、语音文本转换、情感分类、时间序列预测、视频分析等。















 2931
2931

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









