







摘要
Wide & Deep Learning for Recommender Systems
包含非线性特征变换的广义线性模型广泛应用在有稀疏输入的大规模回归和分类问题。通过特征之间的交叉的特征交互的记忆力机制是有效且可解释的,然而模型泛化需要大量的特征工程工作。深度神经网络可以在较少的特征工程条件下,通过对稀疏特征的低维稠密表征,在不看到特征组合下, 达到较好的泛化效果。然而,当用户-物品交互数据较稀疏且高秩下,深度神经网络可能过拟合,并推荐一些不相关的物品。这篇研究中,我们提出wide & deep 模型,联合训练wide线性模型和深度神经网络,对于推荐系统来说,相当于结合了其记忆性和泛化性的优点。我们在Google play上应用并评估了这套模型,实验结果表明,wide & deep 可以显著增加app的下载量,对比wide and deep 单模型来说。代码已经用TF 开源。
引言
论文主要贡献:
- 提出wide & deep学习框架,联合学习基于表征的前馈神经网络和基于特征变换的线性模型,适用于带有稀疏输入的一般推荐系统;
- 将wide&deep的推荐系统应用在Google play中;
- 将带有高阶API的代码开源。
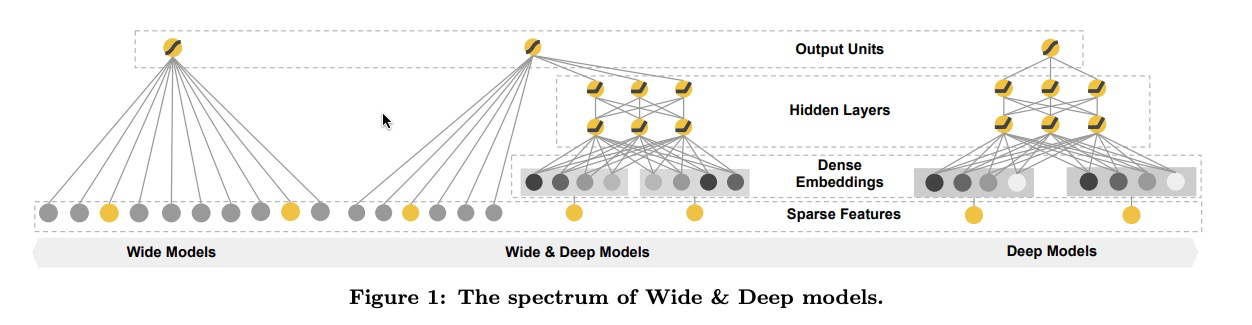
推荐系统综述
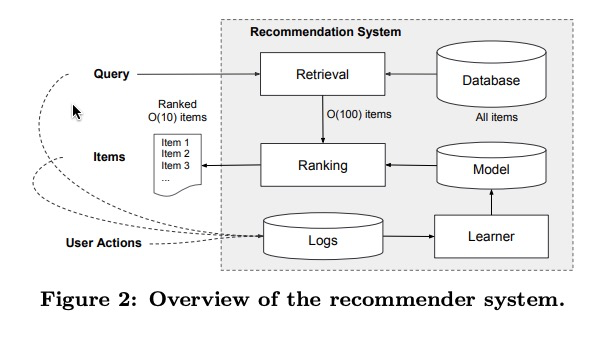
因为数据库里存有上百万的app,针对每次查询,想在实时要求下(通常是10ms以内)计算每一个app的score是非常困难的。
因此,第一步通常是建立在查询基础上的召回。召回系统基于各种信号特征,通常是模型和规制的组合,返回一个和当前查询最匹配的短app列表。在对候选池缩减后,精排系统对每一个候选项进行评分。利用给定的特征
x
x
x,包括用户特征(国家、语言、画像特征等)、上下文特征(设备、小时、星期几)和曝光特征(app页面,历史统计特征等),输出每个label
y
y
y的概率值
P
(
y
∣
x
)
P(y|x)
P(y∣x).
这篇论文,我们着重介绍精排部分,基于wide&deep模型框架。
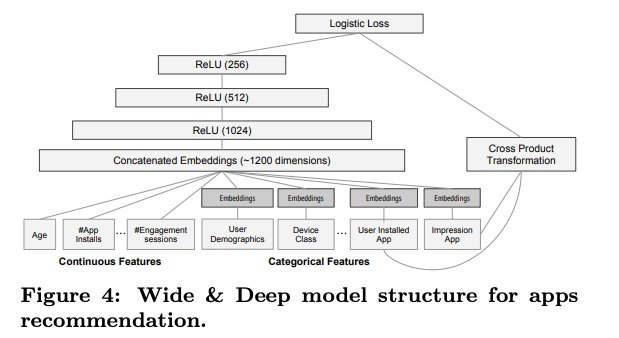
Wide&Deep learning
Wide Component


Deep Component

Joint Training
通过wide部分和deep部分输出的log odds的加权和进行融合,然后喂给联合训练的对数损失函数。这和ensemble模型有区别,ensemble model中,各个模型分别独立进行训练,彼此看不见,然后在推断阶段,将各部分的结果进行融合。相反,joint training 在训练阶段,将wide部分、deep部分以及它们的加权权重同时考虑在内,同时优化所有参数。在模型大小方面,也有不同:ensemble 模型,因为训练是分开的,每个独立模型通常较大(更多的特征和特征变换)才能在模型集成时取得不错的效果。对比joint model,wide部分仅仅需要通过一小部分的特征交叉对deep部分进行补充即可,而不是利用全量wide模型。
利用mini-batch随机梯度下降法,通过回传损失函数的梯度完成wide&deep模型的联合训练。实验中,我们利用带
L
1
L_1
L1正则的FTRL优化器对wide部分进行优化,利用AdaGrad优化器对deep部分进行优化。
对于一个LR问题,模型输出为:

系统实现
pipelin由三部分组成:数据生成,模型训练,模型部署。
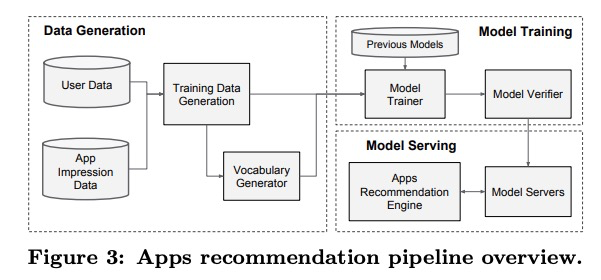
数据生成
通过将特征值 x x x映射到其累计分布函数 P ( X < x ) P(X<x) P(X<x)中,将连续特征进行正则化为[0, 1],连续特征被划分为 n q n_q nq个分位数,第 i i i个分位数的正则值为 i − 1 n q − 1 \frac{i-1}{n_q-1} nq−1i−1。分在数据生成时计算位数边界。
模型训练
wide&deep 在超过5000亿的样本上进行训练,每次有新的数据集进来,模型需要重新训练。然而,从零开始训练成本非常高,且耽误时间。为了解决这个问题,我们设计了一个warm-starting机制,它可以从之前的模型中的embeddings和线性模型权重中,初始化一个新模型。
在模型部署上线之前,我们通常为试运行一下,来确保线上实时预测不会有问题,同时和之前的模型对比效果,确保其合理性。
模型部署
模型被训练和验证之后,我们将其加载到模型服务器中。对于每一次请求,模型服务会从app召回系统和用户特征中接收一个app候选集,并对每一个app进行打分。然而,从预测得分高到低对每个app进行排序,按顺序呈现给用户。评分通过wide&deep的前向推断给出。
为了确保在10ms之内给出每次请求的结果,我们使用了多线程并行的方式,每次并行运行一个小批量的样本,优化系统性能。

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











