







 本文介绍了Gauss-Seidel和Jacobi迭代法用于求解线性方程组的原理,包括矩阵形式和非矩阵形式的公式推导,并提供了稀疏矩阵下的Python代码示例。同时,讨论了两种方法的收敛性条件,指出当迭代矩阵的所有特征值的绝对值小于1时,迭代法收敛。
本文介绍了Gauss-Seidel和Jacobi迭代法用于求解线性方程组的原理,包括矩阵形式和非矩阵形式的公式推导,并提供了稀疏矩阵下的Python代码示例。同时,讨论了两种方法的收敛性条件,指出当迭代矩阵的所有特征值的绝对值小于1时,迭代法收敛。
GaussSeidel迭代 Jacobi迭代 收敛性
迭代法求解线性方程组
目的是对于一个可逆矩阵 A A A,利用迭代法求解
A x = b . Ax=b. Ax=b.
G a u s s S e i d e l Gauss Seidel GaussSeidel 和 J a c o b i Jacobi Jacobi 都是将 A A A 矩阵分成 D + L + U D+L+U D+L+U 矩阵的形式,构造出 x = G x + d x=Gx+d x=Gx+d的迭代矩阵,来迭代求解出 x x x,理想情况下当 x = = G x + d x==Gx+d x==Gx+d 时算法收敛,且此时 x = A − 1 b x= \def\foo{A^{-1}} \foo b x=A−1b。其中 D L U D L U DLU 分别为 A A A 矩阵的对角线矩阵,下三角矩阵和上三角矩阵。
在上述中介绍到两种方法都是通过定义迭代矩阵 x = G x + d x=Gx+d x=Gx+d 来求解 x x x 的。因此接下来分别介绍,GaussSeidel 和Jacobi分别时怎样定义迭代矩阵的。
G a u s s S e i d e l GaussSeidel GaussSeidel
公式推导
矩阵形式
A
=
D
+
L
+
U
A = D + L + U
A=D+L+U
A
x
=
b
Ax=b
Ax=b
(
D
+
L
+
U
)
x
=
b
(D+L+U)x=b
(D+L+U)x=b
(
D
+
L
)
x
=
−
U
x
+
b
(D+L)x = -Ux+b
(D+L)x=−Ux+b
x
=
−
(
D
+
L
)
−
1
U
x
+
(
D
+
L
)
−
1
b
x = -\def\foo{{(D+L)}^{-1}}\foo Ux + \def\foo{{(D+L)}^{-1}}\foo b
x=−(D+L)−1Ux+(D+L)−1b
⟹
x
=
G
x
+
d
\implies x = Gx +d
⟹x=Gx+d
由上述推导可知,在
G
a
u
s
s
S
e
i
d
e
l
GaussSeidel
GaussSeidel中
G
=
−
(
D
+
L
)
−
1
U
G=-\def\foo{{(D+L)}^{-1}}\foo U
G=−(D+L)−1U,
d
=
(
D
+
L
)
−
1
b
d= \def\foo{{(D+L)}^{-1}}\foo b
d=(D+L)−1b
非矩阵形式
x
i
k
=
1
a
i
i
(
b
−
∑
0
<
j
<
i
a
i
j
x
j
k
−
∑
j
>
i
a
i
j
x
j
k
−
1
)
)
x_{i}^{k} = \frac{1}{a_{ii}} (b- \sum_{0<j<i} {a_{ij} x_{j}^{k}}-\sum_{j>i} {a_{ij} x_{j}^{k-1}}) )
xik=aii1(b−0<j<i∑aijxjk−j>i∑aijxjk−1))
其中
x
i
k
x_{i}^{k}
xik 代表
x
x
x 的第
i
i
i个分量在第
k
k
k次迭代中的结果
代码示例
使用非矩阵形式实现在稀疏矩阵csr_matrix下实现的 G a u s s S e i d e l GaussSeidel GaussSeidel。
# A csr_matrix
import sys
import copy
import numpy as np
import networkx as nx
from scipy.sparse import spdiags, tril, triu, coo_matrix, csr_matrix
def gauss_seidel(A, b, x0 = None, maxiter=20):
# x0 = spsolve(A, b)
if x0 is None:
x0 = np.array( [0.0]*A.shape[0] )
for _ in range(maxiter):
n, _, indptr, indices, data = A.shape[0], A.nnz, A.indptr, A.indices, A.data
for row in range(n):
aii, sumi = 0.0, 0.0
for j in range(indptr[row], indptr[row+1]):
if row == indices[j]:
aii = 1.0/data[j]
else:
sumi += data[j] * x0[ indices[j] ]
x0[row] = (aii * (b[row] - sumi) )
return x0
if __name__ == '__main__':
A = csr_matrix(([10,-2,-1, -2,10,-1, -1,-2,5], ([0,0,0,1,1,1,2,2,2], [0,1,2,0,1,2,0,1,2]) ) , shape=(3,3), dtype=np.float32)
x = np.ones(A.shape[0])
b = A.dot(x)
xk = gauss_seidel(A, b)
print(x)
print(xk)
输出如下
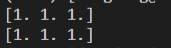
J a c o b i Jacobi Jacobi
公式推导
矩阵形式
A
=
D
+
L
+
U
A = D + L + U
A=D+L+U
A
x
=
b
Ax=b
Ax=b
(
D
+
L
+
U
)
x
=
b
(D+L+U)x=b
(D+L+U)x=b
D
x
=
−
(
L
+
U
)
x
+
b
Dx = -(L+U)x+b
Dx=−(L+U)x+b
x
=
−
D
−
1
(
L
+
U
)
x
+
D
−
1
b
x = -\def\foo{D^{-1}}\foo (L+U)x + \def\foo{D^{-1}}\foo b
x=−D−1(L+U)x+D−1b
⟹
x
=
G
x
+
d
\implies x = Gx +d
⟹x=Gx+d
由上述推导可知,在Jacobi中
G
=
−
D
−
1
(
L
+
U
)
G=-\def\foo{D^{-1}}\foo (L+U)
G=−D−1(L+U),
d
=
D
−
1
b
d= \def\foo{D^{-1}}\foo b
d=D−1b
非矩阵形式
x i k = 1 a i i ( b − ∑ j ! = i a i j x j k − 1 ) x_{i}^{k}= \frac{1}{a_{ii}}(b-\sum_{j!=i} {a_{ij} x_{j}^{k-1}}) xik=aii1(b−j!=i∑aijxjk−1)
代码示例
使用矩阵形式实现在稀疏矩阵csr_matrix下实现的 J a c o b i Jacobi Jacobi。
# A csr_matrix
import sys
import copy
import numpy as np
from scipy.sparse import spdiags, tril, triu, coo_matrix, csr_matrix
def jacobi(A, b, x0 = None, maxiter=20):
if x0 is None:
x0 = np.array( [0.0]*A.shape[0] )
D = spdiags(A.diagonal(), np.array([0]), A.shape[0], A.shape[1]) # default with <class 'scipy.sparse.dia.dia_matrix'>
L = tril(A) - D
U = triu(A) - D
dia = generate_dia_inv(D)
B = -( dia ).dot(L+U)
f = ( dia ).dot(b)
for _ in range(maxiter):
x0 = B.dot(x0) + f
return x0
def generate_dia_inv(mat):
res_dia = mat.diagonal()
res_dia = 1.0/res_dia
res_mat = csr_matrix((res_dia.shape[0], res_dia.shape[0]))
res_mat.setdiag(res_dia)
return res_mat
if __name__ == '__main__':
A = csr_matrix(([10,-2,-1, -2,10,-1, -1,-2,5], ([0,0,0,1,1,1,2,2,2], [0,1,2,0,1,2,0,1,2]) ) , shape=(3,3), dtype=np.float32)
x = np.ones(A.shape[0])
b = A.dot(x)
xk = jacobi(A, b)
print(x)
print(xk)
输出如下

收敛性
因为两种方法的根本思想是一致的,都是通过迭代公式
x
=
G
x
+
d
x = Gx +d
x=Gx+d 来求解
x
x
x。所以直接通过此迭代公式来看两种方法收敛的条件。
令误差向量
e
i
=
x
i
−
x
\def\foo{e^{i}}\foo = \def\foo{x^{i}}\foo-x
ei=xi−x,其中
x
x
x 是
A
x
=
b
Ax=b
Ax=b的精确解,
e
i
\def\foo{e^{i}}\foo
ei是
G
a
u
s
s
S
e
i
d
e
l
GaussSeidel
GaussSeidel或者
J
a
c
o
c
i
Jacoci
Jacoci第
i
i
i次迭代所求解。
| 收敛性证明 |
|---|
| 由于 x i = G x i − 1 + d \def\foo{x^{i}}\foo = G\def\foo{x^{i-1}}\foo+d xi=Gxi−1+d |
| 且 x = G x + d x = Gx+d x=Gx+d |
| 所以有, e i = G e i − 1 \def\foo{e^{i}}\foo = G\def\foo{e^{i-1}}\foo ei=Gei−1 |
| 且 e i − 1 = G e i − 2 \def\foo{e^{i-1}}\foo = G\def\foo{e^{i-2}}\foo ei−1=Gei−2 |
| . . . ... ... |
| 因此, e i = G i e 0 \def\foo{e^{i}}\foo = \def\foo{G^{i}}\foo\def\foo{e^{0}}\foo ei=Gie0 |
| 当迭代法收敛时,就意味着 lim i → ∞ e i → 0 \lim\limits_{i\rarr\infin}\def\foo{e^{i}}\foo\rarr0 i→∞limei→0 |
| 由特征值和特征向量的定义可知 G ζ i = λ i ζ i G\zeta_i=\lambda_i\zeta_i Gζi=λiζi,且特征向量之间线性无关 |
| 因此 e 0 = Σ δ k ζ k \def\foo{e^{0}}\foo=\Sigma\delta_k\zeta_k e0=Σδkζk, 可以这样表示,且 δ k \delta_k δk是定值 |
| 则 e 1 = G e 0 = G ∑ δ k ζ k = ∑ δ k G ζ k = ∑ δ k λ k ζ k \def\foo{e^{1}}\foo = \def\foo{G}\foo\def\foo{e^{0}}\foo = G \sum\delta_k\zeta_k = \sum\delta_kG \zeta_k = \sum\delta_k \lambda_k \zeta_k e1=Ge0=G∑δkζk=∑δkGζk=∑δkλkζk,由 G ζ i = λ i ζ i G\zeta_i=\lambda_i\zeta_i Gζi=λiζi得。 |
| 则 e 2 = ∑ δ k λ k 2 ζ k \def\foo{e^{2}}\foo= \sum\delta_k \lambda_k^{2} \zeta_k e2=∑δkλk2ζk , e 3 = ∑ δ k λ k 3 ζ k \def\foo{e^{3}}\foo= \sum\delta_k \lambda_k^{3} \zeta_k e3=∑δkλk3ζk … |
| 那么 lim i → ∞ e i = lim i → ∞ ∑ λ k i δ k ζ k \lim\limits_{i\rarr\infin}\def\foo{e^{i}}\foo =\lim\limits_{i\rarr\infin} \sum \lambda_k^{i} \delta_k\zeta_k i→∞limei=i→∞lim∑λkiδkζk |
| 其中 δ k ζ k \delta_k\zeta_k δkζk是定值 |
| 则当 a b s ( λ k ) > 1 ⟹ lim i → ∞ e i → ∞ abs(\lambda_k) > 1 \implies\lim\limits_{i\rarr\infin}\def\foo{e^{i}}\foo\rarr\infin abs(λk)>1⟹i→∞limei→∞ |
| 当 a b s ( λ k ) < 1 ⟹ lim i → ∞ e i → 0 abs(\lambda_k) < 1 \implies\lim\limits_{i\rarr\infin}\def\foo{e^{i}}\foo\rarr0 abs(λk)<1⟹i→∞limei→0 |
| 综上,当迭代矩阵 G G G的所有特征值 a b s ( λ k ) < 1 abs(\lambda_k) < 1 abs(λk)<1时, 该迭代方法收敛。 |

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









