







 博主利用Transformer进行销售量预测并记录过程。自己捏造销售数据,详细给出代码框架,包括Transformer模型代码、Utils文件夹各文件代码及功能,还介绍了.env文件和main.py内容。最后展示训练结果,虽有一定效果但还需更新优化。
博主利用Transformer进行销售量预测并记录过程。自己捏造销售数据,详细给出代码框架,包括Transformer模型代码、Utils文件夹各文件代码及功能,还介绍了.env文件和main.py内容。最后展示训练结果,虽有一定效果但还需更新优化。
🤖 专栏《人工智能》
📖 博客说明: 本专栏记录我个人学习和实践人工智能相关算法的心得与内容,一同探索人工智能的奇妙世界吧! 🚀
零、说明
心血来潮,想利用Transformer做一个销售量预测的内容,特此记录。
一、代码框架
transformers_sales_predict_project/
│
├── data/
│ └── data.csv
│
├── models/
│ └── transformer_model.py
│
├── utils/
│ ├── data_processing.py
│ ├── visualization.py
│ ├── train.py
│ └── evaluate.py
│
├── graphs/
│ ├── graph_one_step/
│ └── graph_multi_step/
│
├── .env
├── main.py
各个文件内容如下:
data/: 包含项目数据的文件夹,其中data.csv是用于训练和测试的原始数据文件。
models/: 存放模型的文件夹,其中transformer_model.py包含了用于时间序列预测的Transformer模型。
utils/: 包含各种工具和功能的文件夹,包括:
data_processing.py: 数据预处理的工具函数。
visualization.py: 绘制图表和可视化结果的工具函数。
train.py: 训练模型的工具函数。
evaluate.py: 评估模型性能的工具函数。
graphs/: 包含绘制图表的子文件夹,其中graph_one_step/和graph_multi_step/可能是存放训练过程中生成的图表的地方。
.env: 包含项目的环境变量配置文件,其中定义了一些超参数和路径等项目配置。
main.py: 包含主要的执行脚本,负责加载数据、训练模型、绘制图表等任务。
二、数据
自己捏造了一些销售量数据,看Transformer能不能成功预测,数据长这样:
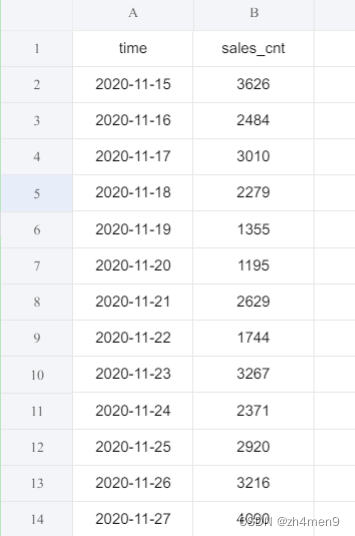
从2020-11-15到2023-12-12,一共1094条数据,第一列为日期,第二列为销售量。
三、Transformer模型代码
完整代码如下:
# models/transformer_model.py
import torch
import torch.nn as nn
import math
class PositionalEncoding(nn.Module):
def __init__(self, hidden_size, max_len=5000):
"""
Transformer模型的位置编码模块。
参数:
- hidden_size (int): 隐藏状态的维度。
- max_len (int): 输入序列的最大长度。
"""
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_len, hidden_size)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, hidden_size, 2).float() * (-math.log(10000.0) / hidden_size))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe)
def forward(self, x):
"""
位置编码模块的前向传播。
参数:
- x (torch.Tensor): 输入张量。
返回:
- torch.Tensor: 添加位置编码后的输出张量。
"""
return x + self.pe[:x.size(0), :]
class TransformerModel(nn.Module):
def __init__(self, feature_size=250, num_layers=1, dropout=0.1):
"""
带有位置编码的Transformer模型。
参数:
- feature_size (int): 特征空间的维度。
- num_layers (int): Transformer层的数量。
- dropout (float): Dropout概率。
"""
super(TransformerModel, self).__init__()
self.model_type = 'Transformer'
self.src_mask = None
self.pos_encoding = PositionalEncoding(feature_size)
self.encoder_layer = nn.TransformerEncoderLayer(d_model=feature_size, nhead=10, dropout=dropout)
self.transformer_encoder = nn.TransformerEncoder(self.encoder_layer, num_layers=num_layers)
self.decoder = nn.Linear(feature_size, 1)
self.initialize_weights()
def initialize_weights(self):
"""
初始化线性解码层的权重。
"""
init_range = 0.1
self.decoder.bias.data.zero_()
self.decoder.weight.data.uniform_(-init_range, init_range)
def forward(self, src):
"""
Transformer模型的前向传播。
参数:
- src (torch.Tensor): 输入序列张量。
返回:
- torch.Tensor: 通过Transformer后的输出张量。
"""
if self.src_mask is None or self.src_mask.size(0) != len(src):
device = src.device
mask = self._generate_square_subsequent_mask(len(src)).to(device)
self.src_mask = mask
src = self.pos_encoding(src)
output = self.transformer_encoder(src, self.src_mask)
output = self.decoder(output)
return output
def _generate_square_subsequent_mask(self, seq_len):
"""
生成Transformer自注意力机制的掩码。
参数:
- seq_len (int): 输入序列的长度。
返回:
- torch.Tensor: 掩码张量。
"""
mask = (torch.triu(torch.ones(seq_len, seq_len)) == 1).transpose(0, 1)
mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))
return mask
详细解析下这个代码:
3.1 PositionalEncoding 类
__init__(self, hidden_size, max_len=5000)
hidden_size: 隐藏状态的维度。
max_len: 输入序列的最大长度,默认为5000。
该类用于定义 Transformer 模型的位置编码模块。在 Transformer 中,由于不使用循环结构,需要一种方式来表示输入序列中不同位置的信息。这里使用了位置编码,通过在输入中添加不同位置的特定编码来表示位置信息。
pe: 位置编码矩阵,维度为 (max_len, hidden_size),表示位置信息。
forward(self, x): 前向传播函数,将位置编码添加到输入张量 x 中,返回添加位置编码后的输出张量。
3.2 TransformerModel 类
__init__(self, feature_size=250, num_layers=1, dropout=0.1)
feature_size: 特征空间的维度,默认为250。
num_layers: Transformer 模型的层数,默认为1。
dropout: Dropout 概率,默认为0.1。
该类定义了一个带有位置编码的 Transformer 模型。
model_type: 模型类型,设置为 'Transformer'。
src_mask: 输入序列的掩码,用于屏蔽未来信息。
pos_encoding: 位置编码模块的实例。
encoder_layer: Transformer 编码器层的实例。
transformer_encoder: Transformer 编码器的实例。
decoder: 线性解码层,将 Transformer 输出映射到最终输出。
initialize_weights(self): 初始化线性解码层的权重。
forward(self, src): Transformer 模型的前向传播函数,接收输入序列 src,返回通过 Transformer 后的输出张量。
_generate_square_subsequent_mask(self, seq_len): 生成 Transformer 自注意力机制的掩码,用于屏蔽未来信息。返回掩码张量。
initialize_weights(self)
该函数用于初始化线性解码层的权重,将偏置初始化为零,权重采用均匀分布在一个小范围内。
forward(self, src)
该函数是 Transformer 模型的前向传播。首先对输入序列进行位置编码,然后通过 Transformer 编码器,最后通过线性解码层映射到最终输出。
_generate_square_subsequent_mask(self, seq_len)
生成一个方形的 Transformer 自注意力机制的掩码。通过将上三角矩阵设为 1,下三角矩阵设为负无穷,从而实现掩盖未来信息的效果。返回的掩码张量被用于 Transformer 的自注意力机制中。
四、Utils文件夹
4.1 data_processing.py
data_processing.py完整代码如下:
# utils/data_processing.py
import torch
from sklearn.preprocessing import MinMaxScaler
import pandas as pd
import numpy as np
def preprocess_data(data_path, input_window, output_window, predict_day, train_data_ratio=1, test_data_num=80, device='cpu'):
"""
数据预处理函数
参数:
- data_path (str): 数据文件路径
- input_window (int): 输入窗口大小
- output_window (int): 输出窗口大小
- predict_day (int): 预测天数
- train_data_ratio (float): 训练数据比例,默认为1
- test_data_num (int): 测试数据数量,默认为80
返回:
- torch.Tensor: 训练数据
- torch.Tensor: 测试数据
- MinMaxScaler: 数据标准化器
- pd.Series: 数据序列
"""
torch.manual_seed(0)
np.random.seed(0)
# 从CSV文件中读取数据
series = pd.read_csv(data_path, usecols=['sales_cnt'])
# 使用MinMaxScaler对数据进行标准化
scaler = MinMaxScaler(feature_range=(0, 1))
series_normalized = scaler.fit_transform(series.values.reshape(-1, 1)).reshape(-1)
# 训练数据包括所有数据,除去预测天数
train_data = series_normalized[:-predict_day]
# 测试数据包括最后的测试数据数量个数据
test_data = series_normalized[-test_data_num:]
# 创建训练数据的输入输出序列
train_sequence = create_input_output_sequences(train_data, input_window, output_window)
train_sequence = train_sequence[:-output_window]
# 创建测试数据的输入输出序列
test_sequence = create_input_output_sequences(test_data, input_window, output_window)
test_sequence = test_sequence[:-output_window]
return train_sequence.to(device), test_sequence.to(device), scaler, series
def create_input_output_sequences(input_data, input_window, output_window):
"""
创建输入输出序列
参数:
- input_data (torch.Tensor): 输入数据
- input_window (int): 输入窗口大小
- output_window (int): 输出窗口大小
返回:
- torch.Tensor: 输入输出序列
"""
sequences = []
L = len(input_data)
for i in range(L - input_window - output_window):
input_seq = input_data[i:i + input_window]
target_seq = input_data[i + output_window:i + input_window + output_window]
sequences.append((input_seq, target_seq))
return torch.FloatTensor(sequences)
def reverse_normalize_data(data, data_max, data_min):
"""
反标准化数据
参数:
- data (torch.Tensor): 标准化后的数据
- data_max (float): 数据最大值
- data_min (float): 数据最小值
返回:
- torch.Tensor: 反标准化后的数据
"""
return data * (data_max - data_min) + data_min
def get_batch(source, i, batch_size, input_window):
"""
获取批次数据
参数:
- source (torch.Tensor): 输入输出序列
- i (int): 批次索引
- batch_size (int): 批次大小
返回:
- torch.Tensor: 输入数据
- torch.Tensor: 目标数据
"""
seq_len = min(batch_size, len(source) - 1 - i)
data = source[i:i + seq_len]
input_data = torch.stack(torch.stack([item[0] for item in data]).chunk(input_window, 1))
target_data = torch.stack(torch.stack([item[1] for item in data]).chunk(input_window, 1))
return input_data, target_data
详细解释如下:
4.1.1 preprocess_data 函数
数据预处理函数,从指定的 CSV 文件中读取销售数据,并进行标准化和序列化处理。
参数:
data_path(str):数据文件路径。input_window(int):输入窗口大小。output_window(int):输出窗口大小。predict_day(int):预测天数。train_data_ratio(float):训练数据比例,默认为1。test_data_num(int):测试数据数量,默认为80。device(str):设备类型,默认为’cpu’。
返回:
torch.Tensor:训练数据。torch.Tensor:测试数据。MinMaxScaler:数据标准化器。pd.Series:原始数据序列。
4.1.2 create_input_output_sequences 函数
创建输入输出序列的函数。
参数:
input_data(torch.Tensor):输入数据。input_window(int):输入窗口大小。output_window(int):输出窗口大小。
返回:
torch.Tensor:输入输出序列。
4.1.3 reverse_normalize_data 函数
反标准化数据的函数。
参数:
data(torch.Tensor):标准化后的数据。data_max(float):数据最大值。data_min(float):数据最小值。
返回:
torch.Tensor:反标准化后的数据。
4.1.4 get_batch 函数
获取批次数据的函数。
参数:
source(torch.Tensor):输入输出序列。i(int):批次索引。batch_size(int):批次大小。input_window(int):输入窗口大小。
返回:
torch.Tensor:输入数据。torch.Tensor:目标数据。
4.2 train.py
完整代码:
# train.py
import time
import torch
from torch.nn.utils import clip_grad_norm_
from .data_processing import get_batch
def train_model(model, train_data, criterion, optimizer, scheduler, batch_size, epochs, input_window, logger, device=torch.device("cuda" if torch.cuda.is_available() else "cpu")):
"""
训练模型
Parameters:
model (nn.Module): 待训练的模型
train_data (Tensor): 训练数据
criterion (nn.Module): 损失函数
optimizer (torch.optim.Optimizer): 优化器
scheduler (torch.optim.lr_scheduler._LRScheduler): 学习率调度器
batch_size (int): 批处理大小
epochs (int): 训练轮数
Returns:
None
"""
for epoch in range(1, epochs + 1):
epoch_start_time = time.time()
model.train()
for batch_index, i in enumerate(range(0, len(train_data) - 1, batch_size)):
start_time = time.time()
total_loss = 0
data, targets = get_batch(train_data, i, batch_size, input_window)
data = data.to(device)
targets = targets.to(device)
optimizer.zero_grad()
output = model(data)
loss = torch.sqrt(criterion(output, targets))
loss.backward()
clip_grad_norm_(model.parameters(), 0.7)
optimizer.step()
total_loss += loss.item()
log_interval = int(len(train_data) / batch_size / 5)
if batch_index % log_interval == 0 and batch_index > 0:
cur_loss = total_loss / log_interval
elapsed = time.time() - start_time
logger.info('| epoch {:3d} | {:5d}/{:5d} batches | lr {:02.6f} | {:5.2f} ms | loss {:5.5f} | ppl {:8.2f}'
.format(epoch, batch_index, len(train_data) // batch_size, scheduler.get_lr()[0], elapsed * 1000 / log_interval, cur_loss, cur_loss))
4.2.1 train_model 函数
训练模型的函数,使用给定的模型、训练数据、损失函数、优化器、学习率调度器等参数进行训练。
参数:
model(nn.Module):待训练的模型。train_data(Tensor):训练数据。criterion(nn.Module):损失函数。optimizer(torch.optim.Optimizer):优化器。scheduler(torch.optim.lr_scheduler._LRScheduler):学习率调度器。batch_size(int):批处理大小。epochs(int):训练轮数。input_window(int):输入窗口大小。logger(Logger):日志记录器。device(torch.device):设备类型,默认为cuda(如果可用),否则为cpu。
返回:
- 无
4.2.2 训练过程解析
- 遍历每个 epoch:
- 设置模型为训练模式。
- 遍历训练数据的每个 batch:
- 获取当前批次的输入数据和目标数据。
- 将数据移动到指定的设备。
- 清空梯度,进行前向传播,计算损失,反向传播,梯度裁剪,更新参数。
- 记录损失并定期输出日志。
4.3 evaluate.py
完整代码:
# evaluate.py
import torch
from .data_processing import get_batch
def evaluate_model(model, eval_data, criterion, eval_batch_size):
"""
评估模型
Parameters:
model (nn.Module): 待评估的模型
eval_data (Tensor): 评估数据
criterion (nn.Module): 损失函数
eval_batch_size (int): 评估时的批处理大小
Returns:
float: 评估损失
"""
model.eval()
total_loss = 0
with torch.no_grad():
for i in range(0, len(eval_data) - 1, eval_batch_size):
data, targets = get_batch(eval_data, i, eval_batch_size)
output = model(data)
total_loss += len(data[0]) * criterion(output, targets).cpu().item()
return total_loss / len(eval_data)
4.3.1 evaluate_model 函数
评估模型的函数,使用给定的模型、评估数据、损失函数等参数进行评估。
参数:
model(nn.Module):待评估的模型。eval_data(Tensor):评估数据。criterion(nn.Module):损失函数。eval_batch_size(int):评估时的批处理大小。
返回:
- float: 评估损失
4.3.2 评估过程解析
- 将模型设置为评估模式。
- 遍历评估数据的每个 batch:
- 获取当前批次的输入数据和目标数据。
- 进行前向传播,计算损失。
- 累加损失。
4.3.3 注意
- 梯度计算被禁用,因为在评估阶段不需要进行参数更新。
- 返回的评估损失为总损失除以评估数据总长度的平均值。
4.4 visualization.py
完整代码:
# utils/visualization.py
import torch
import matplotlib.pyplot as plt
import os
from .data_processing import get_batch, reverse_normalize_data
def plot_and_loss_origin_data(eval_model, origin_data_time, epoch, scaler, series, input_window, predict_day, origin_draw_start=0, origin_draw_end=40, predict_draw_start=None, predict_draw_end=None, weather_origin_draw_standard=False, weather_predict_draw_standard=False, weather_mark_origin_point=True, weather_mark_predict_point=True, mark_origin_or_standard='origin',
device=torch.device("cuda" if torch.cuda.is_available() else "cpu")):
"""
绘制原始数据与预测数据的图表,并保存为图片
参数:
- eval_model (nn.Module): 训练好的模型
- origin_data_time (torch.Tensor): 原始数据的对应的时间数据
- epoch (int): 当前轮次
- scaler (MinMaxScaler): 数据标准化器
- series (pd.Series): 数据序列
- input_window (int): 输入窗口大小
- predict_day (int): 预测天数
- origin_draw_start (int): 原始数据画图起始位置,默认为0
- origin_draw_end (int): 原始数据画图结束位置,默认为40
- predict_draw_start (int): 预测数据画图起始位置,默认为origin_draw_end - predict_day
- predict_draw_end (int): 预测数据画图结束位置,默认为origin_draw_end
- weather_origin_draw_standard (bool): 是否使用标准化数据画图,默认为False
- weather_predict_draw_standard (bool): 是否使用标准化数据画图,默认为False
- weather_mark_origin_point (bool): 是否标注原始数据点,默认为True
- weather_mark_predict_point (bool): 是否标注预测数据点,默认为True
- mark_origin_or_standard (str): 标注点使用原始数据还是标准化数据,默认为'origin'
返回:
- None
"""
plt.figure(figsize=(12, 8))
DATA_MAX = scaler.fit(series.values.reshape(-1, 1)).data_max_
DATA_MIN = scaler.fit(series.values.reshape(-1, 1)).data_min_
os.makedirs('./graphs/graph_multi_step', exist_ok=True)
eval_model.eval()
test_result = torch.Tensor(0)
series_normalized = scaler.fit_transform(series.values.reshape(-1, 1)).reshape(-1)
with torch.no_grad():
last_20_days_data = torch.FloatTensor(series_normalized[-input_window-predict_day:-predict_day]).view(-1, 1, 1).to(device)
for i in range(predict_day):
output = eval_model(last_20_days_data)
test_result = torch.cat((test_result, output[-1].view(-1).cpu()), 0)
last_20_days_data = torch.cat((last_20_days_data[:, -(input_window-1):], output[-1].view(1, -1, 1)))
predicted_days_range = range(predict_draw_start or origin_draw_end - predict_day, predict_draw_end or origin_draw_end)
if weather_origin_draw_standard:
plt.plot(range(origin_draw_start, origin_draw_end), series_normalized[-origin_draw_end:].reshape(-1, 1)[origin_draw_start:origin_draw_end], color='green', label='True Date', marker='o')
else:
plt.plot(range(origin_draw_start, origin_draw_end), series[-origin_draw_end:].values.reshape(-1, 1), color='green', label='True Date', marker='o')
if weather_predict_draw_standard:
last_7_days = test_result.view(-1, 1).numpy()
else:
last_7_days = reverse_normalize_data(test_result.view(-1, 1).numpy(), DATA_MAX, DATA_MIN)
plt.plot(predicted_days_range, last_7_days, color='orange', label='Predict Data', marker='o')
plt.legend()
if weather_mark_origin_point:
if weather_origin_draw_standard:
draw_value = series_normalized[-origin_draw_end:].reshape(-1, 1)[origin_draw_start:origin_draw_end]
else:
draw_value = series[-origin_draw_end:].values.reshape(-1, 1)[origin_draw_start:origin_draw_end]
if mark_origin_or_standard == 'origin':
for x in range(origin_draw_start, origin_draw_end):
y = draw_value[x - origin_draw_start]
value = series['sales_cnt'].values[-origin_draw_end + x]
plt.text(x, y, f'{value.item():.0f}', color='black', fontsize=6, ha='center', va='bottom', rotation=50)
elif mark_origin_or_standard == 'standard':
for x in range(origin_draw_start, origin_draw_end):
y = draw_value[x - origin_draw_start]
value = series_normalized[-origin_draw_end + x]
plt.text(x, y, f'{value.item():.2f}', color='black', fontsize=6, ha='center', va='bottom', rotation=50)
if weather_mark_predict_point:
for x in range(predicted_days_range.start, predicted_days_range.stop):
if mark_origin_or_standard == 'origin':
y = last_7_days[x - predicted_days_range.start]
draw_value = reverse_normalize_data(test_result.view(-1, 1).numpy(), DATA_MAX, DATA_MIN)
value = draw_value[x - predicted_days_range.start].item()
plt.text(x, y, f'{value:.0f}', color='r', fontsize=6, ha='center', va='bottom', rotation=50)
else:
y = last_7_days[x - predicted_days_range.start]
draw_value = test_result.view(-1, 1).numpy()
value = draw_value[x - predicted_days_range.start].item()
plt.text(x, y, f'{value:.2f}', color='r', fontsize=6, ha='center', va='bottom', rotation=50)
ticks = origin_data_time['time'].values[-origin_draw_end:].reshape(-1, 1)[origin_draw_start:origin_draw_end].flatten()
plt.xticks(range(origin_draw_start, origin_draw_end), ticks, rotation=30)
plt.savefig('./graphs/graph_multi_step/transformer-epoch%d.png' % epoch)
plt.close()
def plot_and_loss(eval_model, data_source, epoch, input_window, criterion, device):
"""
绘制损失图表并保存为图片
参数:
- eval_model (nn.Module): 训练好的模型
- data_source (torch.Tensor): 数据源
- epoch (int): 当前轮次
返回:
- float: 损失值
"""
eval_model.eval()
total_loss = 0.
test_result = torch.Tensor(0)
truth = torch.Tensor(0)
with torch.no_grad():
for i in range(0, len(data_source) - 1):
data, target = get_batch(data_source, i, 1, input_window)
data = data.to(device)
target = target.to(device)
output = eval_model(data)
total_loss += criterion(output, target).item()
test_result = torch.cat((test_result, output[-1].view(-1).cpu()), 0)
truth = torch.cat((truth, target[-1].view(-1).cpu()), 0)
plt.plot(test_result, color="red")
plt.plot(truth, color="blue")
plt.grid(True, which='both')
plt.axhline(y=0, color='k')
os.makedirs('./graphs/graph_one_step', exist_ok=True)
plt.savefig('./graphs/graph_one_step/transformer-epoch%d.png' % epoch)
plt.close()
return total_loss / i
4.4.1 plot_and_loss_origin_data 函数
绘制原始数据与预测数据的图表,并保存为图片。
参数:
eval_model(nn.Module):训练好的模型。origin_data_time(torch.Tensor):原始数据的对应的时间数据。epoch(int):当前轮次。scaler(MinMaxScaler):数据标准化器。series(pd.Series):数据序列。input_window(int):输入窗口大小。predict_day(int):预测天数。origin_draw_start(int):原始数据画图起始位置,默认为0。origin_draw_end(int):原始数据画图结束位置,默认为40。predict_draw_start(int):预测数据画图起始位置,默认为origin_draw_end - predict_day。predict_draw_end(int):预测数据画图结束位置,默认为origin_draw_end。weather_origin_draw_standard(bool):是否使用标准化数据画图,默认为False。weather_predict_draw_standard(bool):是否使用标准化数据画图,默认为False。weather_mark_origin_point(bool):是否标注原始数据点,默认为True。weather_mark_predict_point(bool):是否标注预测数据点,默认为True。mark_origin_or_standard(str):标注点使用原始数据还是标准化数据,默认为’origin’。device(torch.device):指定设备,默认为cuda(如果可用),否则为cpu。
返回:
- None
4.4.2 plot_and_loss 函数
绘制损失图表并保存为图片。
参数:
eval_model(nn.Module):训练好的模型。data_source(torch.Tensor):数据源。epoch(int):当前轮次。input_window(int):输入窗口大小。criterion(nn.Module):损失函数。device(torch.device):指定设备,默认为cuda(如果可用),否则为cpu。
返回:
- float: 损失值
4.4.3 注意
- 保存的图片会在"./graphs/graph_multi_step"或"./graphs/graph_one_step"目录下,文件名为"transformer-epoch%d.png",其中%d为当前轮次。
- 可以通过参数设置绘图的各种细节,包括起始位置、是否标准化、是否标注数据点等。
五、.env文件
.env文件完整内容:
# .env
# 窗口大小
INPUT_WINDOW=20
# 输出窗口大小
OUTPUT_WINDOW=1
# 批处理大小
BATCH_SIZE=5
# 预测天数
PREDICT_DAY=7
# 训练数据比例
TRAIN_DATA_RATIO=0.7
# 测试数据个数
TEST_DATA_NUM=80
# 数据路径
DATA_PATH=./data/data.csv
# 画图宽度
PLOT_WIDTH=40
# 原始值画图起始位置
ORIGIN_DRAW_START=0
# 原始值画图结束位置
ORIGIN_DRAW_END=40
# 原始数据画图是否用标准化数据画图
WEATHER_ORIGIN_DRAW_STANDARD=False
# 预测值画图起始位置
PREDICT_DRAW_START=33
# 预测值画图结束位置
PREDICT_DRAW_END=40
# 预测数据画图是否用标准化数据画图
WEATHER_PREDICT_DRAW_STANDARD=False
# 标注原始数据点
WEATHER_MARK_ORIGIN_POINT=True
# 标注预测数据点
WEATHER_MARK_PREDICT_POINT=True
# 标注使用原始数据还是标准化数据
MARK_ORIGIN_OR_STANDARD=origin
# 模型配置
LEARNING_RATE=0.0001
EPOCHS=30
GAMMA=0.95
六、main.py
完整代码:
# main.py
import os
from dotenv import load_dotenv
import torch
import shutil
import time
from loguru import logger
import pandas as pd
from models.transformer_model import TransformerModel
from utils.data_processing import preprocess_data
from utils.train import train_model
from utils.evaluate import evaluate_model
from utils.visualization import plot_and_loss_origin_data, plot_and_loss
# 添加日志文件
logger.add(
f"./logs/{time.strftime('%Y-%m-%d-%H-%M-%S', time.localtime(time.time()))}.log",
rotation="00:00",
retention="7 days",
level="INFO"
)
# 加载环境变量
load_dotenv()
# 设置设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
logger.info(device)
# 文件夹路径设置
if os.path.exists('./graphs/graph_one_step'):
shutil.rmtree('./graphs/graph_one_step')
if os.path.exists('./graphs/graph_multi_step'):
shutil.rmtree('./graphs/graph_multi_step')
# 加载数据和模型
input_window = int(os.getenv("INPUT_WINDOW"))
output_window = int(os.getenv("OUTPUT_WINDOW"))
predict_day = int(os.getenv("PREDICT_DAY"))
train_data_ratio = float(os.getenv("TRAIN_DATA_RATIO"))
test_data_num = int(os.getenv("TEST_DATA_NUM"))
data_path = os.getenv("DATA_PATH")
# 加载数据和模型
train_data, val_data, scaler, series = preprocess_data(
data_path,
input_window,
output_window,
predict_day,
train_data_ratio,
test_data_num
)
model = TransformerModel().to(device)
# 定义损失函数
criterion = torch.nn.MSELoss(reduction="mean")
# 定义学习率和优化器
lr = float(os.getenv("LEARNING_RATE"))
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1, gamma=float(os.getenv("GAMMA")))
epochs = int(os.getenv("EPOCHS"))
batch_size = int(os.getenv("BATCH_SIZE"))
input_window = int(os.getenv("INPUT_WINDOW"))
# 定义常量
origin_draw_start = int(os.getenv("ORIGIN_DRAW_START"))
origin_draw_end = int(os.getenv("ORIGIN_DRAW_END"))
predict_draw_start = int(os.getenv("PREDICT_DRAW_START"))
predict_draw_end = int(os.getenv("PREDICT_DRAW_END"))
weather_origin_draw_standard = bool(os.getenv("WEATHER_ORIGIN_DRAW_STANDARD"))
weather_predict_draw_standard = bool(os.getenv("WEATHER_PREDICT_DRAW_STANDARD"))
weather_mark_origin_point = bool(os.getenv("WEATHER_MARK_ORIGIN_POINT"))
weather_mark_predict_point = bool(os.getenv("WEATHER_MARK_PREDICT_POINT"))
mark_origin_or_standard = os.getenv("MARK_ORIGIN_OR_STANDARD")
# 读取时间信息
origin_data_time = pd.read_csv(data_path, usecols=['time'])
origin_data_time['time'] = pd.to_datetime(origin_data_time['time']).dt.strftime('%Y/%m/%d')
# 训练模型
for epoch in range(1, epochs + 1):
epoch_start_time = time.time()
train_model(train_data=train_data,
model=model,
criterion=criterion,
optimizer=optimizer,
scheduler=scheduler,
batch_size=batch_size,
epochs=epoch,
input_window=input_window,
logger=logger,
device=device)
if (epoch % 1 == 0):
plot_and_loss_origin_data(
model,
origin_data_time,
epoch,
scaler,
series,
input_window,
predict_day,
origin_draw_start=origin_draw_start,
origin_draw_end=origin_draw_end,
predict_draw_start=predict_draw_start,
predict_draw_end=predict_draw_end,
weather_origin_draw_standard=weather_origin_draw_standard,
weather_predict_draw_standard=weather_predict_draw_standard,
weather_mark_origin_point=weather_mark_origin_point,
weather_mark_predict_point=weather_mark_predict_point,
mark_origin_or_standard=mark_origin_or_standard,
device=device
)
val_loss = plot_and_loss(eval_model=model,
data_source=val_data,
epoch=epoch,
input_window=input_window,
criterion=criterion,
device=device)
else:
val_loss = evaluate_model(model, val_data, criterion)
logger.info('-' * 89)
logger.info(f'| 结束训练周期 {epoch:3d} | 时间: {(time.time() - epoch_start_time):5.2f}s | 验证损失 {val_loss:.5f} |')
logger.info('-' * 89)
scheduler.step()
main.py主要用于训练和评估 Transformer 模型,并绘制损失图表和原始数据与预测数据的图表。
加载模块和设置日志
- 使用
os,dotenv,torch,shutil,time,loguru,pandas等模块。 - 添加日志文件记录训练和评估过程。
加载环境变量
- 使用
load_dotenv()加载环境变量。
设置设备
- 根据是否有可用的 CUDA 设备,选择在 GPU 或 CPU 上运行。
文件夹路径设置
- 在每次运行前,清空之前保存图表的文件夹。
加载数据和模型
- 调用
preprocess_data函数加载并预处理数据。 - 初始化 Transformer 模型。
定义损失函数、学习率和优化器
- 使用均方根误差(
MSELoss)作为损失函数。 - 使用 AdamW 优化器,带有学习率调度器。
定义常量
- 从环境变量中读取训练参数和图表绘制相关的常量。
读取时间信息
- 从数据中读取时间信息。
训练模型
- 使用
train_model函数进行模型训练,同时绘制原始数据与预测数据的图表,保存损失图表。
注意
- 图表保存在"./graphs/graph_multi_step"或"./graphs/graph_one_step"目录下,文件名为"transformer-epoch%d.png",其中%d为当前轮次。
- 可以通过环境变量设置训练和图表绘制的各种参数。
七、训练结果
在现有参数下,loss持续下降,效果还可以。
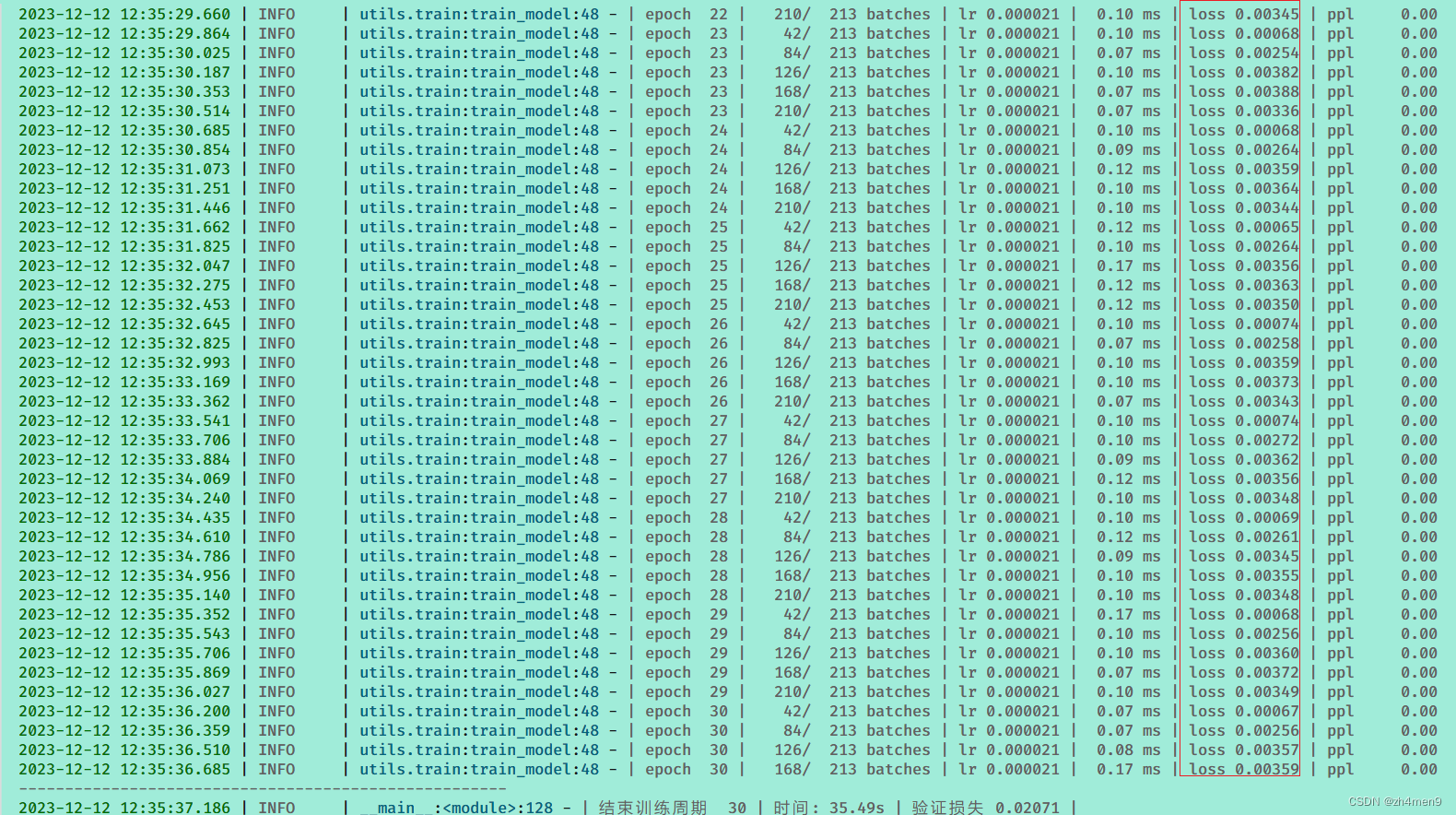
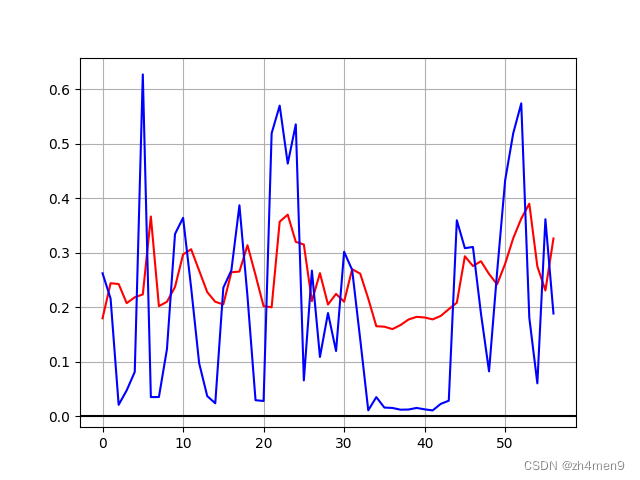
看下一个epoch下的单步预测图,效果明显欠佳:
其对应的多步(7步)预测图,效果还行,趋势学到了:
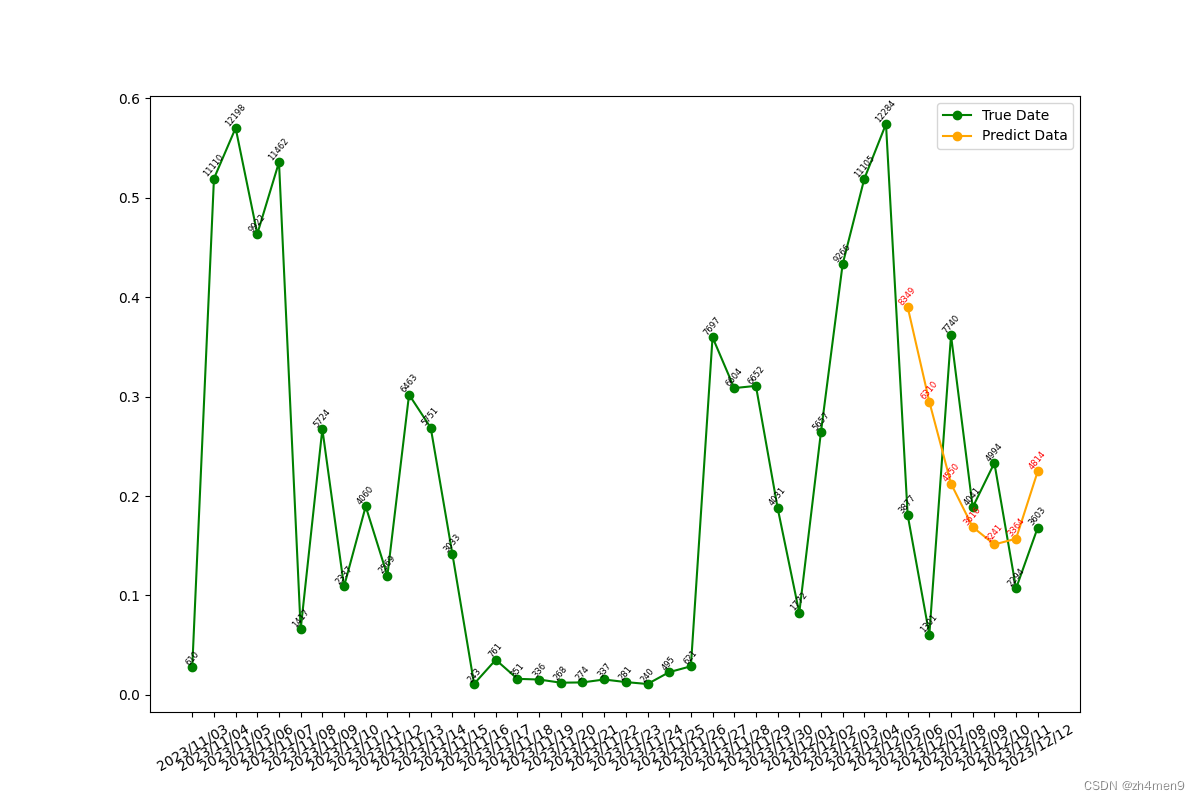
在30个epoch时,单步预测效果就很好了:
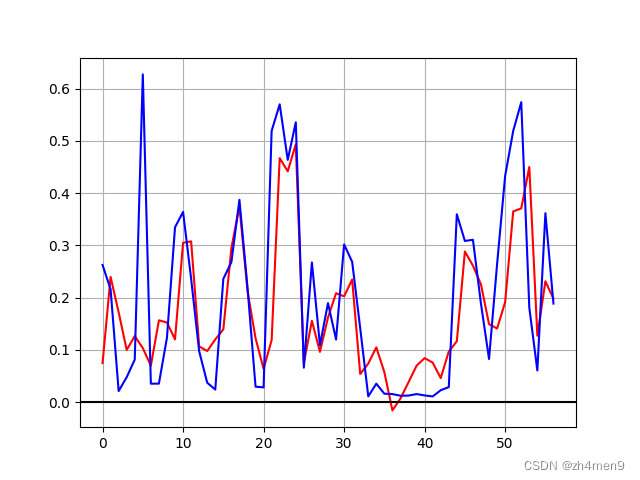
对应的多步预测结果在前几天还可以,后面几天就比较差了:
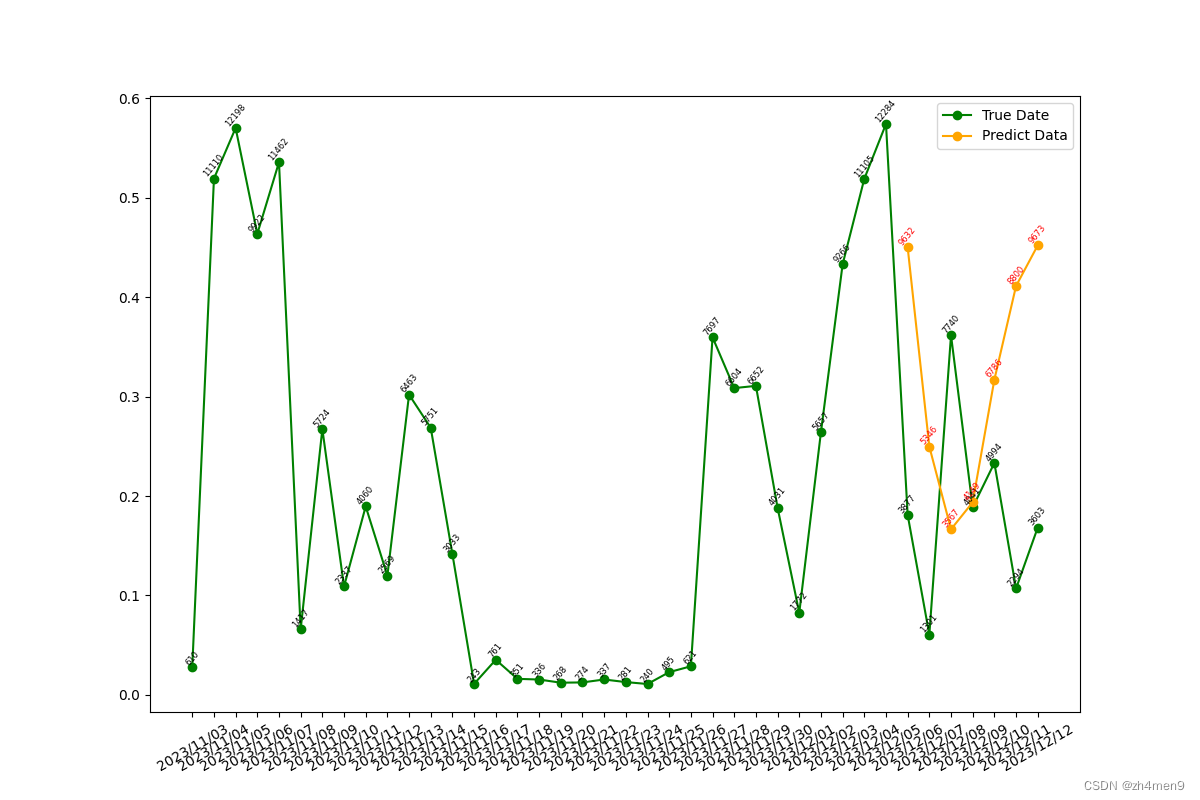
感觉效果还可以,Transformer还是很厉害的。不过这个模型效果实在拿不出手去应用,等有机会更新下~
八、完整代码
九、参考资料
👨💻 关于我:我是zh4men9,一个正在学习人工智能的孩子。如果你对我的学习经验感兴趣,欢迎访问我的CSDN博客:CSDN博客。
📚 更多分享: 你还可以在我的知乎博客上找到我更多的观点和经验分享:知乎博客。
💻 GitHub链接: 如果你对我的项目和代码感兴趣,可以在我的GitHub上找到更多:GitHub链接。


















 92
92

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











