







概述
决策树、随机森林是常用的机器学习方法,其中树模型作为现在主流框架xgboost与lightgdb的基本组成,有着非常重要的地位,本人通过学习七月在线小阳老师的课程以及查阅相关资料,将学习笔记和感悟记录下来。
从LR到决策树
这里小阳老师举了一个非常形象的例子,是否去相亲,并对比LR与决策树的不同方法:
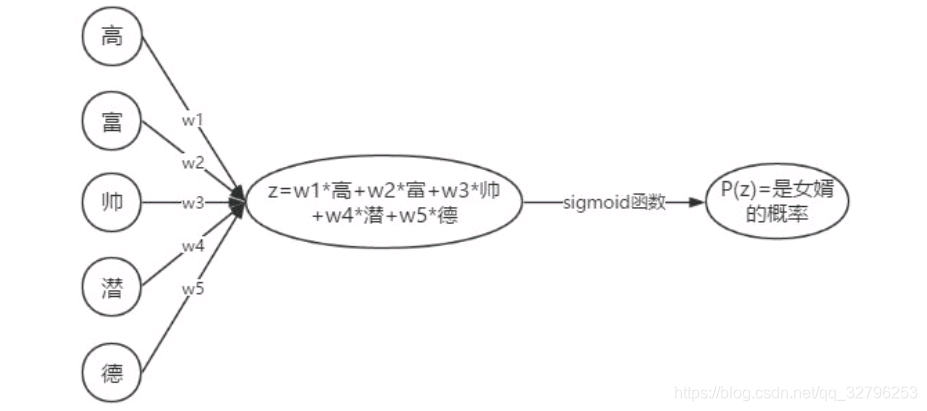
上图是LR的思考方法,计算出Z的值,计算每一类的概率,并设定阈值来进行分类.考虑全局的特征共同的结果

而决策树是一种贪心算法,更加偏向局部分析,同时更接近我们平时的思维方式,具体区别推荐这篇博客作为补充阅读。
决策树的学习过程:通过队训练样本的分析来确定“划分属性”;
决策树的预测过程:将测试实例从根结点开始,沿着划分属性所构成的“判定测试序列”下行,直到叶节点;
决策树
决策树的总体流程
决策树的学习目的:产生一棵泛化能力强的决策树,基本流程如下图的伪代码所示:

很显然,决策树的生成是一种递归过程,这个过程中有三种递归返回:
- 当前节点包含的样本全部属于同一类别,无需划分;
- 当前属性集为空,或者是所有样本在所有属性上取值相同,无法划分;
- 当前节点包含的样本集合为空,不能划分;
划分选择
有上述流程可知,从A中选择最优划分属性 a ∗ a_* a∗是决策树算法的核心,那么如何划分就成了关键,根据划分的规则,我们可以将决策树分为三类,ID3、C4.5以及CART;
信息增益(ID3)
信息熵(entropy)是度量样本集合“纯度”的指标,定义如下:
E
n
t
(
D
)
=
−
∑
k
=
1
∣
y
∣
p
k
.
l
o
g
2
p
k
Ent(D)=-\sum_{k=1}^{|y|} p_k.log_2p_k
Ent(D)=−k=1∑∣y∣pk.log2pk
其中
E
n
t
(
D
)
Ent(D)
Ent(D)越小,D的纯度越高
而信息增益就是数据集划分前的信息熵与与划分后的信息熵:
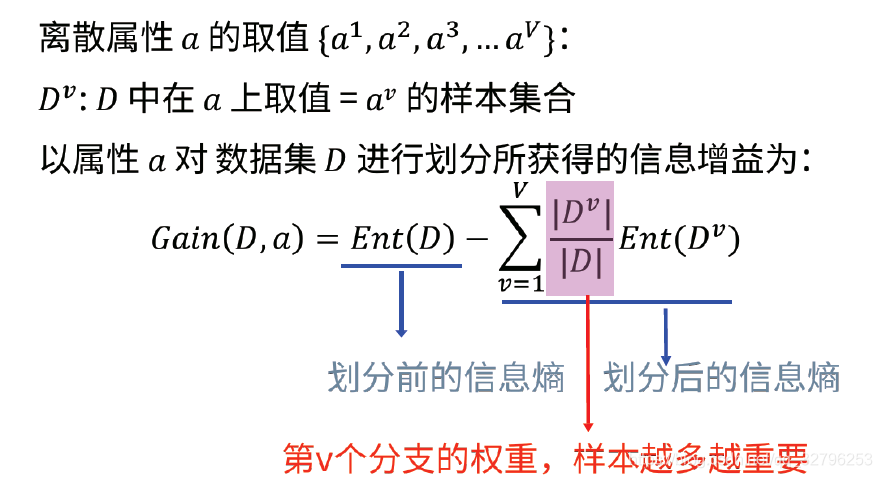
信息增益的计算与举例子可以见西瓜书,决策树每次划分属性都会遍历整个属性空间,然后选出信息增益最大的那个作为划分依据
信息增率(C4.5)
信息增益有个很大的弊端,就是对可取值数目较多的属性有所偏好比如班上有45同学,决策树如果按学号分叉,模型将毫无作用;为了避免这样的问题,我们引入了信息增益率
G
a
i
n
r
a
t
i
o
(
D
,
a
)
=
G
a
i
n
(
D
,
a
)
I
V
(
a
)
Gain_ratio(D,a)=\frac{Gain(D,a)}{IV(a)}
Gainratio(D,a)=IV(a)Gain(D,a)
其中
I
V
(
a
)
=
−
∑
v
=
1
V
∣
D
v
∣
∣
D
∣
log
2
∣
D
v
∣
∣
D
∣
IV(a)=-\sum_{v=1}^V\frac{|D^v|}{|D|}\log_2 \frac{|D^v|}{|D|}
IV(a)=−∑v=1V∣D∣∣Dv∣log2∣D∣∣Dv∣,且属性a的可能取值数目越多(即V越大),则
I
V
(
a
)
IV(a)
IV(a)越大
基尼指数(CART)
CART 是一种二叉树
G
i
n
i
(
D
)
=
∑
k
=
1
∣
y
∣
∑
k
′
≠
k
p
k
p
k
′
=
1
−
∑
k
=
1
∣
y
∣
p
k
2
Gini(D)=\sum_{k=1}^{|y|}\sum_{k^{'}\ne k}p_kp_k{'} \\ \quad \quad \quad =1-\sum_{k=1}^{|y|}p^2_k
Gini(D)=k=1∑∣y∣k′̸=k∑pkpk′=1−k=1∑∣y∣pk2
例如箱子里有黑白两种小球,你连续摸两次都是一样的小球概率越高代表数据纯度越高;而基尼指数正好表示随机两个样例,其类别标记不一致的概率;Gini(D)越小,数据集D的纯度越高。在候选属性集中,选取让基尼指数最小的属性
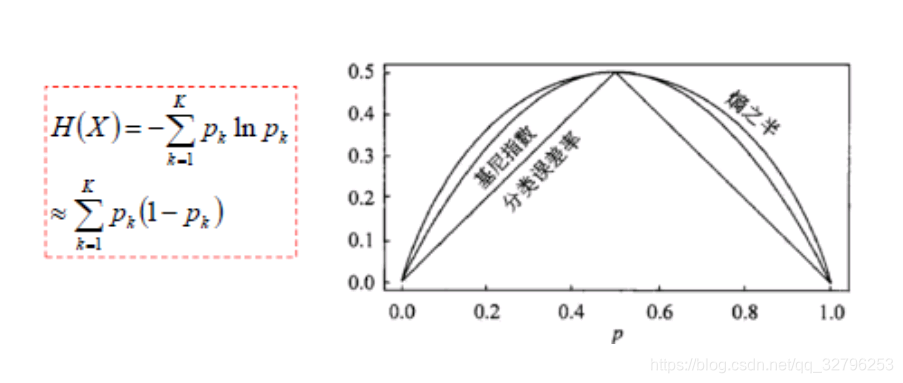
三者对比
信息熵泰勒展开就是基尼指数
从决策树到随机森林
模型的集成方法有很多种,而随机森林作为树的集成,用的是Bagging方法
Bagging
Bagging是bootstrap aggregating(自主采样法)的缩写,Bagging降低了过拟合风险,提高了泛化能力。
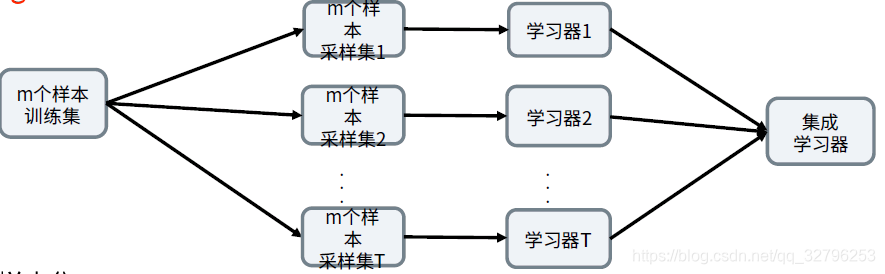
对样本集D进行t次随机采样,每次得到包含m个样本的数据集
D
m
D_m
Dm,并用t个
D
m
D_m
Dm去训练t个学习器。而且
对于分类场景,t个学习器投出最多的票数的类别作为最终类别。回归场景,T个学习器得到的回归结果进行算术平均得到的值为最终的模型输出。
正式这样的随机采样,可以避免噪音的干扰并进行有效的学习。
决策树
与上述不同的是在构建树模型的过程中,样本不仅要随机采,样本的特征也会选取一部分。
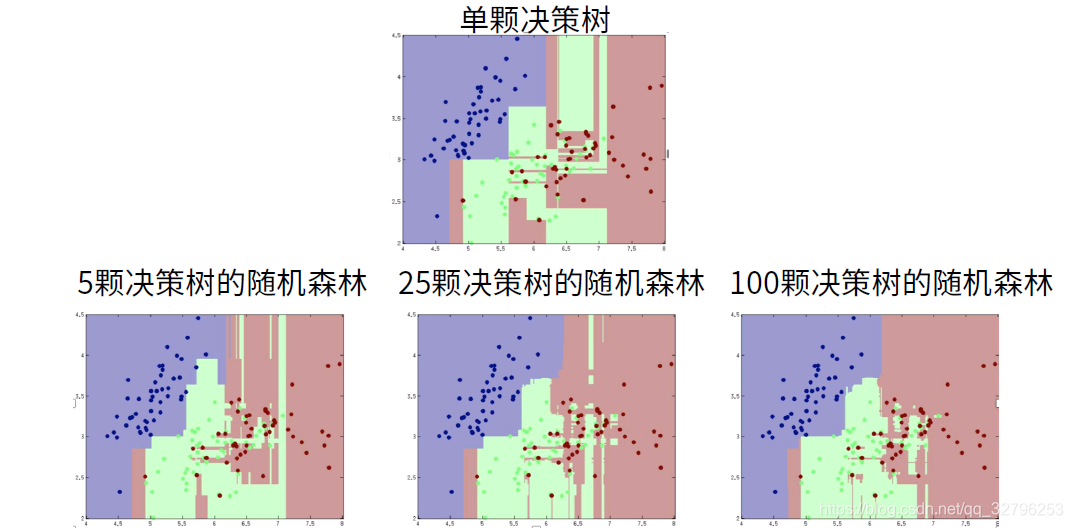
我们发现随机森林所包含的决策树种类越多,划分的越平滑,容错率最低。
项目
总结一下使用决策树的用法
#初始化一个决策树分类器
clf = tree.DecisionTreeClassifier(criterion='entropy', max_depth=4)
#用决策树分类器拟合数据
clf = clf.fit(features.values, label.values)
#预测
clf.predict(features.values)
#可视化
import pydotplus
from IPython.display import display, Image
dot_data = tree.export_graphviz(clf,
out_file=None,
feature_names=features.columns,
class_names = ['<=50k', '>50k'],
filled = True,
rounded =True
)














 152
152











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









