








http://blog.ezyang.com/2019/05/pytorch-internals/
1.Tensor
tensor 是pytorch基本的数据格式。你或许已经知道tensor是什么:n维数据结构,包含一些标量的数据类型,比如floats,ints,其他。
我们知道tensor是一些数据的组成,还有一写元数据用来表示tensor的大小,tensor中数据的类型,tensor存储位置(cpu还是gpu)

这里有一些元数据你可能不太熟悉,stride。stride是pytorch的特色

tensor是数学概念,但是怎么保存到计算机中,我们应该定义一些物理的表示规则。
最常见的把tensor中每个元素连续的保存在内存中,在内存中写下每一行元素。
在上面的例子中我规定了tensor包含的是32位的int元素,所以每个整数包含在一个物理地址,每个地址偏移4个字节。为了记住tensor实际的维度,我们需要使用size记录,那么strided有啥用
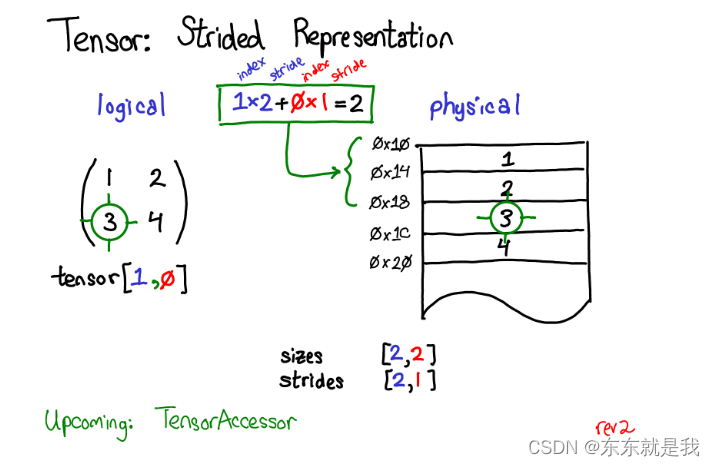
假设我们想访问tensor中位置为【0,1】的元素,那么我们怎么把【0,1】的逻辑位置转为物理地址内存的位置?
stride告诉我们要这么做:把逻辑位置和strided相乘再相加。比如上图3这个元素的位置为【0,1】乘以stride【2,1】再相加=2。index从0开始。所以3就在开始数据位置下的第2个位置。
后面会介绍一个tensoraccessor类,这个类为了方便位置计算。
所以stride是pytorch的基础,例如我想提取第二行的tensor数据

使用高级的index支持,tensor【1,:】表示一行数据。重要的事,当我这么做的时候,我没有创建新的tensor,相反,我仅仅返回一个和原本的tensor不同视图的tensor,这意味这如果我修改了tensorf【1,:】,那么原始的tensor也会改变。
3,4存在连续内存中,我们只要记录这个数据和原来数据下面偏移2个位置 offset=2,每一个tensor记录一个offset,但是大部分offset=0,所以我们的图表中忽略这个offset
q:如果我从原始tensor得到一个新的view, 我怎么释放原始的tensor的内存
a: 你要copy这个view,然后断开与原来的tensor物理内存。没有其他的办法了
如果我想获取一列

我们发现竖着的数据在内存中不是连续的,每个元素有一个间隔。stride 从1变成2 ,说明每个元素隔着一个,你需要跳过2个 字节,
我们必须要把tensor和物理内存解耦
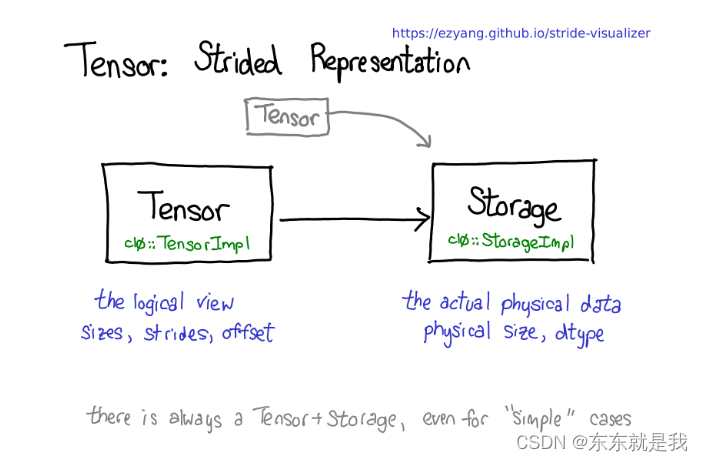
多个tensor使用相同的内存,每个storage定义了tensor的物理内存大小和类型,每个tensor记录size,strides和offset。
tensor-strorge至少一对出现,即使在简单的情况下,你不需要storage,例如你仅仅使用 torch.zeros(2,2)
tensort的运算也值得介绍,比如你使用torch.mm的时候,2个部分发生了
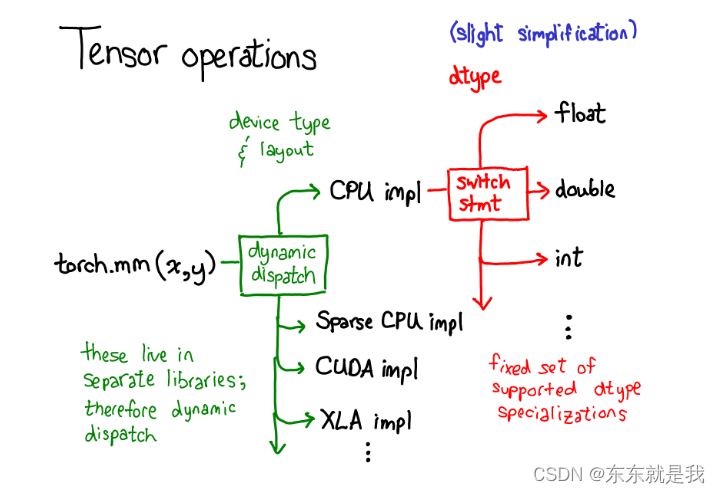
首先一个部分依赖device 类型和tensor的布局,是否是cup存储还是gpu存储,是strided tensor 还是 稀疏的。这是一个动态的部分,这是一个虚拟的函数,判断使用cpu 矩阵乘法还是cuda矩阵乘法,他们的动态库也不同,例如libcaffe2.so 或者libcaffe2_gpu.so 。
第二个部分,依赖dtype,这个只是简单的switch 选择对应type支持的内核,比如floats的内核和int的内核不一样的。

讲一下tensor的扩展,除了cpu float tensor 还有其他的扩展 比如XLA tensor quantized tensor 或者 MKL-DNN tensors
那么tensor 库怎么适应这些扩张
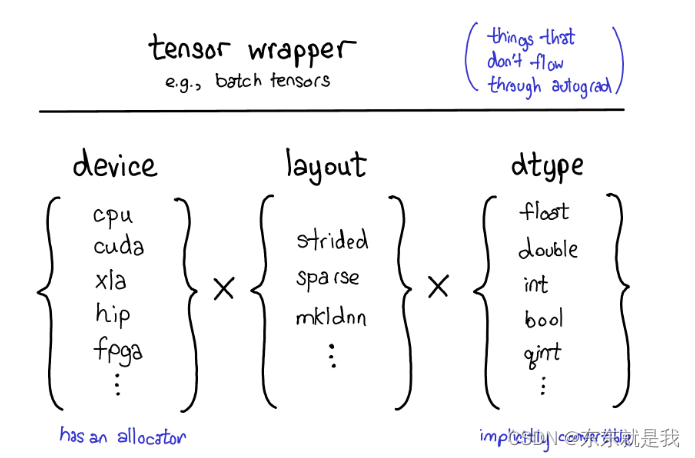
我们目前tensor扩展支持4个扩展点,首先它是3位一体的参数,它表明了tensor是啥
第一个 device ,它表明tensor的物理内存 ,例如cpu 或者 nvidia gpu (cuda) 或者amd gpu(hip) 或者tpu(xla)
第二个layout,它表明了我们怎么解释这些物理内存,比如使用strided ,但是稀疏tensor 有不同的布局,或者mkl-dnn tensor 也有其他的布局。
第三个dtype,它表明了内存中存储的tensor中每个元素的是什么。
2 自动求导

花点时间研究一下上图,
1.首先,我们看到红色和蓝色的变量。pytorh实现了反向自动求导的功能,这意味着我们关注正向计算,反向计算使用了梯度
我们计算loss ,首先是计算grad_loss,然后因为loss是从next_h2计算得来的,所以继续计算grad_next_h2,事实上这些grad_的变量不是真的梯度,它们只是一个雅可比矩阵左乘一个向量。但是pytorch中我们称他们是梯度。
2.如果代码保持一样的结构体,他们的行为却不同,forwards每一行都被替换为不同的计算,这表示反向传播。
例如tanh操作转为tanh_backwad,前向和反向的输入输出是相互交换的,如果前向产生了next_h2,那么反向操作就是把grad_next_h2作为输入
下图描述了自动梯度,就是所有点的计算,但是不包含源头
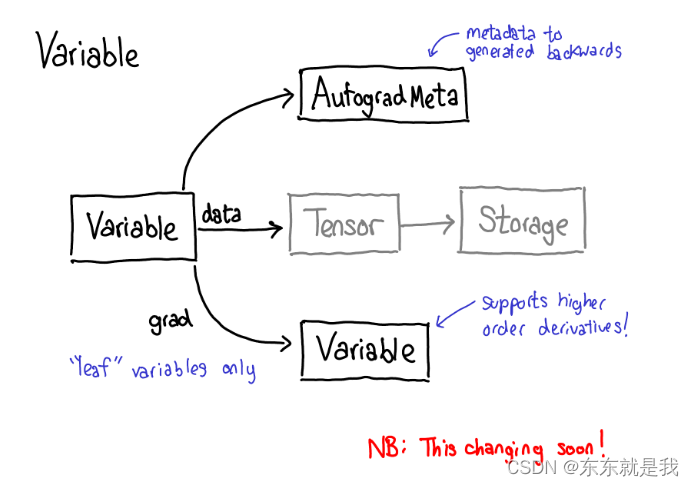
当我们对tensor运算的时候需要存储一些元数据,让我们调整我们的图片关于tensor数据的结构体,现在不是一个tensor需要存储,我们现在有包含这个tensor的变量,也能存储更多信息,当用户使用loss。backward()需要更多信息
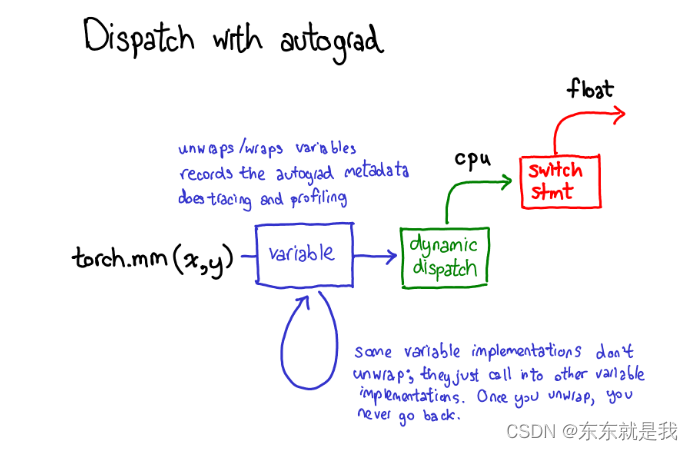
当我们送去cpu或cuda的时候,还有一些额外的部分在变量上,那个负责展开变量,底层实现 (绿色部分),重新包装变量和记录需要自动梯度的元数据为了反向传播
一些实现不能展开,他们只是调用了其他变量的实现。
3.代码
pytorc很多文件夹,真正需要了解的只有4个文件夹
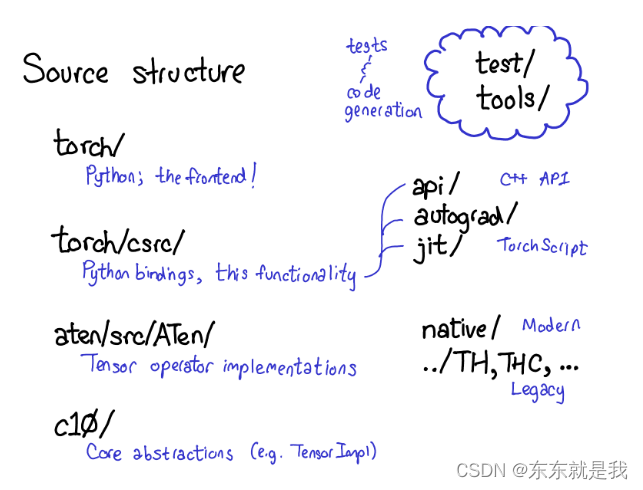
1.torch/ 包含你们熟悉的,python模型 。这是python代码,容易修改,但是很多深层的都隐藏了
2.torch/csrc c++代码 pytorch底层代码,它实现了c++到python的转换代码,还有一些非常重要的,例如自动梯度 JIT编译器
3.aten/ tensor库的简称,C++库 实现tensor的操作,如果你寻找哪里有内核代码,就在这。aten分为2个部分,一是native,它是C+++实现的,另一个legacy ,这个遗留下的c实现的,这个部分太糟糕,不值得浪费时间
4.c10/ tensor 的实现和结构话数据存储
我们看看在实际怎么做代码分离的
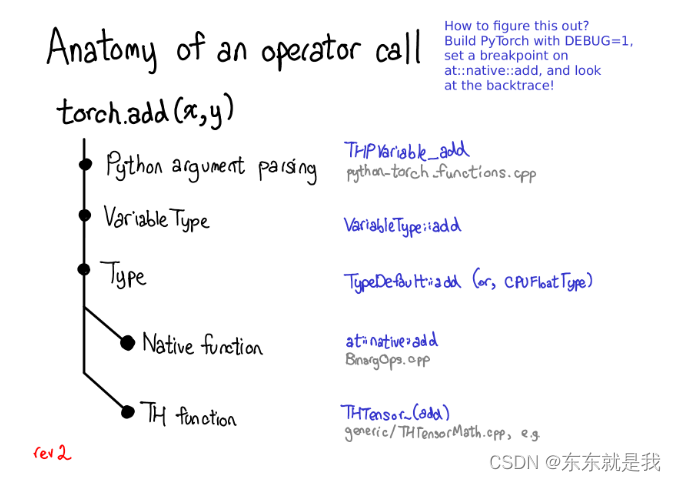
例如torch.add ,实际上发生了什么。
- 从python转为C++ (python argumen parsing)
- 处理变量的部分(variabletype-type)这部分和编程语言无关,只是一个分发任务的小工具
- 处理 device type、layout 的部分 (type) 不就上文的处理tensor的那个步骤
- 这样我们就拿到了内核操作,要不是native 要不就是legacy的(th function)
每一步都对应一些代码,让我们看看把

开始的c++代码里用c实现python函数,像python暴露的接口是这种torch._C.VariableFunctions.add.THPVariable_add
这段代码是自动生成的,如果你在github搜索,你找不到这个,你必须build pytorch才能看到,你也没必要深入的理解这个代码在干嘛,我们只用大概浏览一下,弄懂他的意思。上面蓝色标注是重要的信息,你能看到PythonArgParser这个类从c++中提取python的参数。然后调用dispatch_add函数(我用红色);这会释放全局解释器锁,然后调用c++张量self.add的一个普通的旧方法。返回的过程把tensor包装成pyobject

当我们调用tensor类的add方法时,还没有发生vaiable部分 就是(上面的第二步)。相反,我们有一个内联方法,它在“Type”对象上调用一个方法。(也就是第三步)这个方法是实际的方法,这个方法的实现在TypeDefault,这个方法在任何设备都以一样。
如果在不同设备实现不一样,名称就不同,比如CPUFloatType::add.
这有点曲折,所以一旦你对将要发生的事情有了一些基本的了解,我建议直接跳到核心部分。
4. writing kernels

1.首先,我们编写了一些关于内核的元数据,这些元数据支持代码生成,并让您无需编写任何代码就可以获得对Python的所有绑定
2.然后,你获得这个kernel,你通过了第二步的 device\layout 的步骤。首先你要写下错误检测,确保输入的tensor是正确的尺寸
3.把结果tensor给变成输出结果大小
4.根据dype选择合适的kernel
5.大多数性能内核都需要某种程度的并行化,这样就可以利用多cpu系统。(CUDA内核是“隐式”并行化的,因为它们的编程模型是建立在大规模并行化的基础上的)。
6.最后,您需要访问数据并进行您想要进行的计算
写不下去了! 后面有用到再看!!!!!!















 731
731











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









