









| Time Limit: 1000MS | Memory Limit: 65536K | |
| Total Submissions: 8089 | Accepted: 2342 |
Description
RJ Freight, a Japanese railroad company for freight operations has recently constructed exchange lines at Hazawa, Yokohama. The layout of the lines is shown in Figure 1.
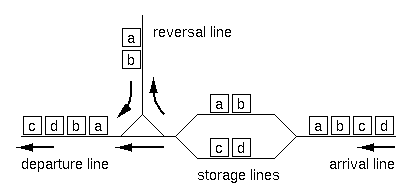
Figure 1: Layout of the exchange lines
A freight train consists of 2 to 72 freight cars. There are 26 types of freight cars, which are denoted by 26 lowercase letters from "a" to "z". The cars of the same type are indistinguishable from each other, and each car's direction doesn't matter either. Thus, a string of lowercase letters of length 2 to 72 is sufficient to completely express the configuration of a train.
Upon arrival at the exchange lines, a train is divided into two sub-trains at an arbitrary position (prior to entering the storage lines). Each of the sub-trains may have its direction reversed (using the reversal line). Finally, the two sub-trains are connected in either order to form the final configuration. Note that the reversal operation is optional for each of the sub-trains.
For example, if the arrival configuration is "abcd", the train is split into two sub-trains of either 3:1, 2:2 or 1:3 cars. For each of the splitting, possible final configurations are as follows ("+" indicates final concatenation position):
[3:1]
abc+d cba+d d+abc d+cba
[2:2]
ab+cd ab+dc ba+cd ba+dc cd+ab cd+ba dc+ab dc+ba
[1:3]
a+bcd a+dcb bcd+a dcb+a
Excluding duplicates, 12 distinct configurations are possible.
Given an arrival configuration, answer the number of distinct configurations which can be constructed using the exchange lines described above.
Input
The entire input looks like the following.
the number of datasets = m
1st dataset
2nd dataset
...
m-th dataset
Each dataset represents an arriving train, and is a string of 2 to 72 lowercase letters in an input line.
Output
For each dataset, output the number of possible train configurations in a line. No other characters should appear in the output.
Sample Input
4 aa abba abcd abcde
Sample Output
1 6 12 18
题意:给你一个串,你可以把这个串分成两部分然后重新拼接,问你最多能拼接出多少个不同的串。
思路:直接暴力枚举拼接出来的串,重点是怎么判重,map这里是超时的,可以考虑哈希,这里我直接用的字典树,很简单。
注意:
1.字典树要用静态的不然会超时。
2.map水不过
3.字典树的节点尽量开大一点
#include <iostream>
#include <cstdio>
#include <cstring>
using namespace std;
struct node
{
int flag;
int next[26];
}nodes[1000000];
int top,l;
char s[100];
char sx[4][100];//分别存放分割好的两个串的正序和倒序
char cs[100];
int x[8]={0,0,2,2,1,1,3,3};//这里用来直接暴力枚举拼接
int y[8]={1,3,1,3,0,2,0,2};
//这部分是字典树的
int newnode()
{
nodes[top].flag=0;
memset(nodes[top].next,-1,sizeof(nodes[top].next));
return top++;
}
bool check(int x,char *s)
{
if(!(*s))
{
if(!nodes[x].flag)
{
nodes[x].flag++;
return 1;
}
else return 0;
}
int t=(*s)-'a';
if(nodes[x].next[t]==-1)nodes[x].next[t]=newnode();
return check(nodes[x].next[t],s+1);
}
//——————————神奇的分割线——————————
void get_in(int k)//得到正序
{
int i;
int cnt=0;
for(i=0;i<=k;++i)sx[0][cnt++]=s[i];
sx[0][cnt]=0;
cnt=0;
for(i=k+1;i<l;++i)sx[1][cnt++]=s[i];
sx[1][cnt]=0;
}
void get_out(int k)//得到逆序
{
int i;
int cnt=0;
for(i=k;i>=0;--i)sx[2][cnt++]=s[i];
sx[2][cnt]=0;
cnt=0;
for(i=l-1;i>k;--i)sx[3][cnt++]=s[i];
sx[3][cnt]=0;
}
void get_sum(char *s1,char *s2)//拼接s1和s2
{
int i;
int cnt=0;
int l1=strlen(s1);
int l2=strlen(s2);
for(i=0;i<l1;++i)cs[cnt++]=s1[i];
for(i=0;i<l2;++i)cs[cnt++]=s2[i];
cs[cnt]=0;
}
int main()
{
int t;
int i,j;
scanf("%d",&t);
while(t--)
{
top=0;
newnode();
scanf("%s",s);
int sum=0;
l=strlen(s);
for(i=0;i<l-1;++i)
{
get_in(i);
get_out(i);
for(j=0;j<8;++j)//枚举拼接
{
get_sum(sx[x[j]],sx[y[j]]);
if(check(0,cs))sum++;
}
}
printf("%d\n",sum);
}
return 0;
}














 85
85











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









