






好文章出处:https://blog.csdn.net/weixin_38664232/article/details/89948373
对推荐系统面试经常问到的一些基础问题进行总结,方便自己记忆。
1、模型产生过拟合的原因及解决方案
什么是过拟合:
模型在训练集上效果较好,在测试集上表现较差。
产生过拟合原因:
- 参数太多,模型复杂度高
- 样本中噪音数据较大,模型学习到了噪音中的特征
- 对于决策树模型。对决策树的生长没有合理的限制和修建
- 对于神经网络模型。权值学习迭代次数足够多(overtraining),拟合了训练数据中的噪声和训练样例中没有代表性的特征。
解决方案:
- 降低模型复杂度
- 增大训练集,训练集增加之后就能学习到更多具有代表性的特征
- 增加正则项,减少参数,进一步降低模型复杂度
- 对于神经网络,采用dropout
- 对于决策树,采用earlystopping,模型对训练数据集迭代收敛之前停止,防止过拟合
- 采用ensemble。集成学习可以有效的减轻过拟合。bagging通过平均多个模型的结果,来降低模型的方差。boosting不仅可以减小偏差,还可以减小方差。
2、Logistic回归的损失函数,为什么要用sigmoid函数?sigmoid函数有何优缺点?
目标函数:
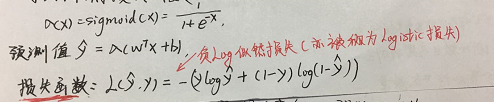
sigmoid优缺点:
logistic是基于Bernoulli分布的假设,也就是y|x~Bernoulli分布,而Bernoulli分布的指数族的形式就是1/(1+exp(-z))。
优点:
- 数据压缩能力,将数据规约在[0,1]之间
- 导数计算方便
缺点:
- 存在梯度消失问题,当x稍大的情况就接近于一条水平线
- zigzag问题,非0中心化,在神经网络算法等情况下,造成反向传播时权重的全正全负的情况。
3、Logistic回归为什么用交叉熵而不用欧式距离做损失函数?
欧式距离不是凸函数;交叉熵是凸函数;凸函数问题求解方便。
4、Logistic回归是生成模型还是判别模型?
判别模型,直接输出类后验概率p(y|x),没有对类条件概率p(x|y)或联合概率p(x,y)建模。
5、为什么L1正则会把feature压缩到0而L2正则做不到?
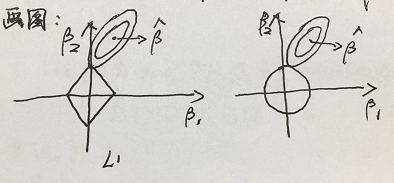
- L1正则只要不是特殊情况下与正方形的边相切,一定是与某个定点优先相交,那么必然存在横纵坐标中的一个系数为0,起到对变量筛选的作用。
- L2正则在圆的限制下,点可以是圆上的任意一点,对岭回归来说,是起不到压缩变量作用的。
6、分类模型如何选择?如何判别效果?如何计算auc?描述一个集成分类模型?
整体上:
数据量越大,神经网络越好;维度越多,bagging算法越优越;训练数量不多不少的情况下,SVM效果最好。
常用判断:
accuracy,recall,ROC,auc,ks,f1值
auc的计算方法:roc曲线下的面积,FP(假阳率)、TP(真阳率)
一个集成分类模型:randomforest
- rf是由若干cart树构成的,每棵树尽情生长不剪枝,最后采用加权投票或者取均值的方式确定输出值
- 每棵树的数据采用bagging方式随机抽取特征及样本数目(决策树生长和随机性,这是RF的两个特性),每棵树之间的数据可能重复。
- 一般先以sqrt(feature_number)作为每次输入的特征数,采取grid_search的方法观察tree的数量(0-500),oob的变化(out-of-bag,袋外误差,每次抽取到的数据进行训练,没有被抽到的数据作为校验样本,校验样本的误差就是oob)
- 根据实际要求的精度后期可以进行调整:每次输入的特征个数、每棵树的最大深度、每个节点的分裂方式 (信息增益率/Gini指数)
7、信息增益、信息增益率、Gini指数

Gini指数:

8、LightGBM细节技术
1.直方图优化(Histogram算法)
先把连续的浮点特征值离散化成k个整数,同时构造一个宽度为k的直方图。遍历数据时,根据离散化后的值作为索引在直方图中累积统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优分割点。
2.带深度限制的Leaf-wise的叶子生长策略
Level-wise过一次数据可以同时分裂同一层的叶子,容易进行多线程优化,也好控制模型复杂度,不容易过拟合。但实际上Level-wise是一种低效算法,因为它不加区分的对待同一层叶子,带来了很多没必要的开销,因为实际上很多叶子的分裂增益较低,没有必要进行搜索和分裂。
Leaf-wise则是一种更为高效的策略:每次从当前所有叶子中,找到分裂增益最大的一个叶子,然后分裂,如此循环。因此同Level-wise相比,在分裂次数相同的情况下,Leaf-wise可以降低更多的误差,得到更好的精度。
Leaf-wise的缺点:
可能会生长出较深的决策树,产生过拟合。因此LightGBM在Leaf-wise之上增加了一个最大深度限制,在保证高效率的同时防止过拟合。
3.直方图做差
直方图做差可以达到两倍的加速,可以观察到一个叶子节点上的直方图,可以由它的父节点直方图减去它兄弟节点的直方图来得到。根据这一点,可以构造出数据量较小的叶子节点上的直方图,然后用直方图做差得到数据量较大的叶子节点上的直方图,从而达到加速的效果。
4.存储记忆优化
当我们使用数据的bin描述特征的时候带来的变化:首先它不是像与排序算法那样去存储每一个排序后数据的序列;一般bin会控制在一个比较小的范围,所以我们可以用更小的内存来存储。
5.支持类别型特征
传统的机器学习一般不能直接输入类别特征,需要先转化为多维的0-1特征,这样无论在空间上海市时间上效率都不高。LightGBM通过更改决策树算法的决策规则,直接原生支持类别特征,不需要转化,提高了近8倍的速度。
如图所示:

6.支持并行学习
搜索计算每个叶子的分裂增益时,可以并行计算;但是基学习器之间是串行计算。
9、XGBoost原理

10、one-hot为什么会导致维度爆炸?
用法示例:
-
enc=OneHotEncoder() -
enc_fe=enc.fit_transform(df['feature']).toArray() -
result=pd.concat([df,enc_fe],axis=1)
独热码,在英文文献中称作one-hot,又称独热编码,一位有效编码,直观来说有多少个状态就有多少比特,而且只有一个比特为1,其他都为0的一种码制。特征取值较多的时候,映射到欧式空间表现为维度特别高。某一维中只有一位为1,其他位都是0.
使用独热编码,将离散特征的取值扩展到了欧式空间,离散特征的某个取值就对应欧式空间的某个点。将离散特征使用one-hot编码,会让特征之间的距离计算更加合理。
11、为什么随机森林能降低方差?
随机森林的预测输出值是多棵决策树的均值,如果有n个独立同分布的随机变量xi,它们的方差都为sigma^2,则它们的均值为:
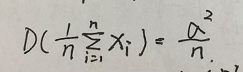
,取多个模型输出结果的均值的方差降低为原来的n分之一。
12、GBDT的核心思想?
用加法模拟,更准确的说,是多棵决策树来拟合一个目标函数。每一棵决策树拟合的是之前迭代得到的模型的残差。求解时,对目标函数使用一阶泰勒展开,用梯度下降法训练决策树。
13、XGBoost的核心思想?
在GBDT的基础上,目标函数增加了正则化项,并且在求解时做了二阶泰勒展开。
14、PCA(主成分分析)优化的目标是什么?
最小化重构误差/最大化投影后的方差















 1141
1141











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









