






前言
prompt更像是和大模型直接交流的语言,prompt写的好坏,可能直接影响LLM的输出,在产品中,为了输出的格式,或者其他的约束,在输入的prompt中添加一些话术也是必不可少的,现在对于prompt提示工程也有很多paper的研究工作,这次主要记录自己学习llm初期,关于prompt的一些知识,整体偏简约,不会写的太冗余
通过为 AI 分配一个角色,我们给它提供了一些上下文。这个上下文有助于 AI 更好地理解问题。通过更好地理解问题,AI 往往可以给出更好的答案。
一、基础
主要包含以下几个部分
角色(role):给 AI 定义一个和任务最相关的角色,比如:「你是一位算法工程师」,先定义角色,其实就是在prompt的开头将问题域缩小,问答更具垂直性
指示(instruction):对任务大体要完成的方向进行描述, 比如写小说
知识(knowledge):和用户提的问题相关的私有化知识或者持续更新的外部知识
历史记录(history):可能需要,在一个输入的prompt中添加之前的有选择的history对话(user/assist对话对)
上下文(context):给出与输入的任务相关的其它上下文(背景)信息,其实就是提供可能和这个输入或者任务有关系的一些信息,作为辅助信息,让回答更准确
例子(example):给出任务的实际例子,其实就是few-shot learning
输入(input):输入信息
输出(output schema):输出格式描述,主要是为了后续解析,将想要的结果拿出来,做其他集成,用得最多的主要就是json了
在使用过程中,如果prompt足够长,这些prompt提示词本身放的前后顺序要比想象中的大,大模型通常对 prompt 开头和结尾的内容更敏感。
二、进阶技巧
2.1 少样本提示(few shot prompt)
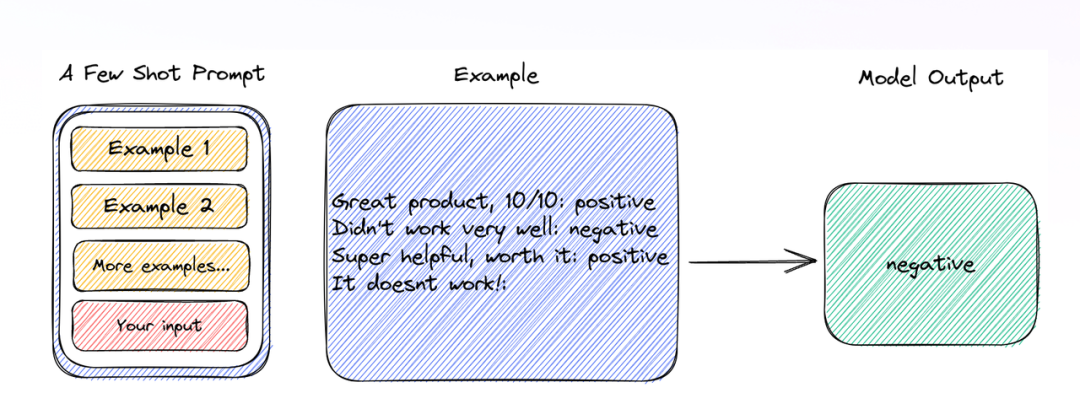
类似于给一至多个实例,来让大模型泛化
2.2 思维链(Chain of Thoughts, CoT)
出自于华人nips2022的paper,短短不到两年,引用已经快3000了:Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Paper link:https://proceedings.neurips.cc/paper_files/paper/2022/file/9d5609613524ecf4f15af0f7b31abca4-Paper-Conference.pdf
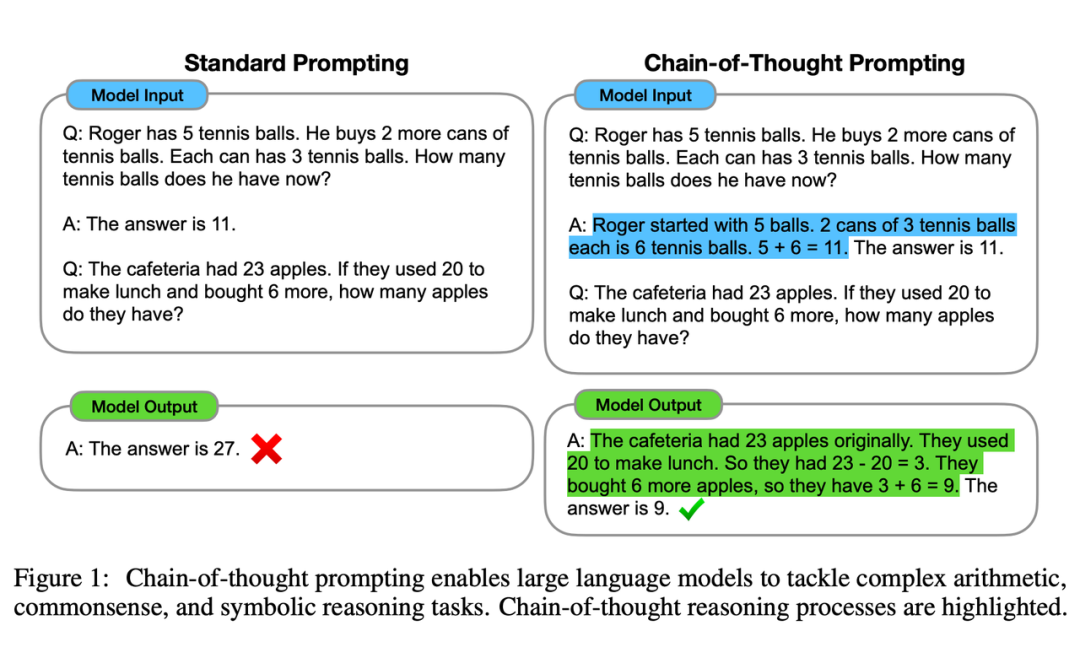
具体看原文,这里直接说结果了。这种能力类似于,告诉llm和人一样,把一个大的task分成很多个小的task,每一步想明白,最后的结果更不容易出错,这个论文中最早发现llm的这一特性,但还是需要把思维链的prompt详细的写出来一次,类似于Few-shot,所以这种Cot被称为Few-shot-CoT
后来根据东京大学的学者发表的论文:Large Language Models are Zero-Shot Reasoners
Paper link:https://arxiv.org/pdf/2205.11916.pdf
想简单的采用思维链,只需要在prompt加入Let's think step by step 等等话术,就可以得到相同的效果, 相当于一句话实现zero-shot
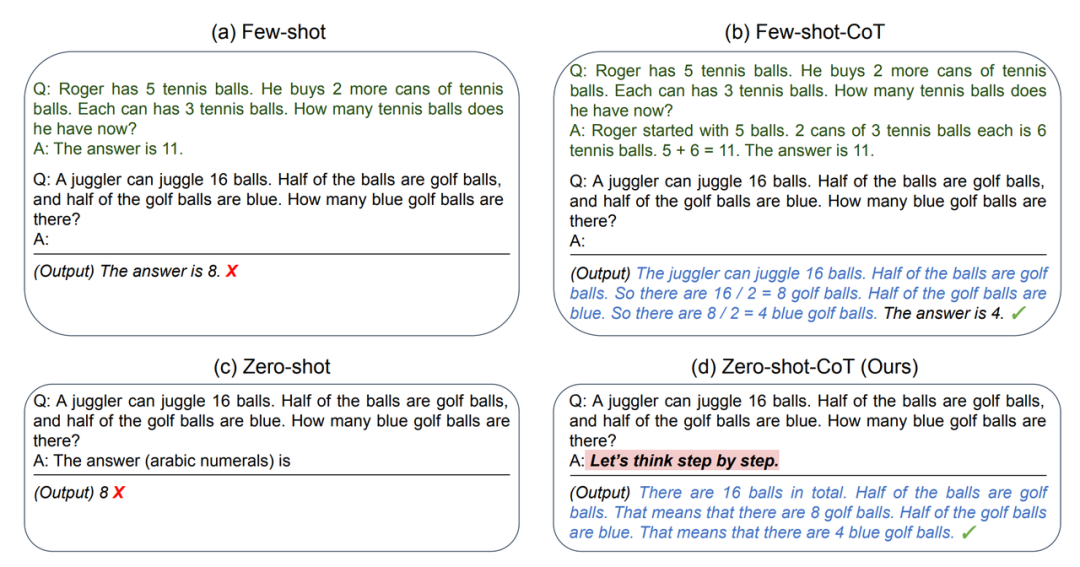
2.3 自洽性(Self-Consistency)
来自于ICLR 2023的一篇论文:Self-Consistency Improves Chain of Thought Reasoning in Language Models
Paper link:https://openreview.net/forum?id=1PL1NIMMrw
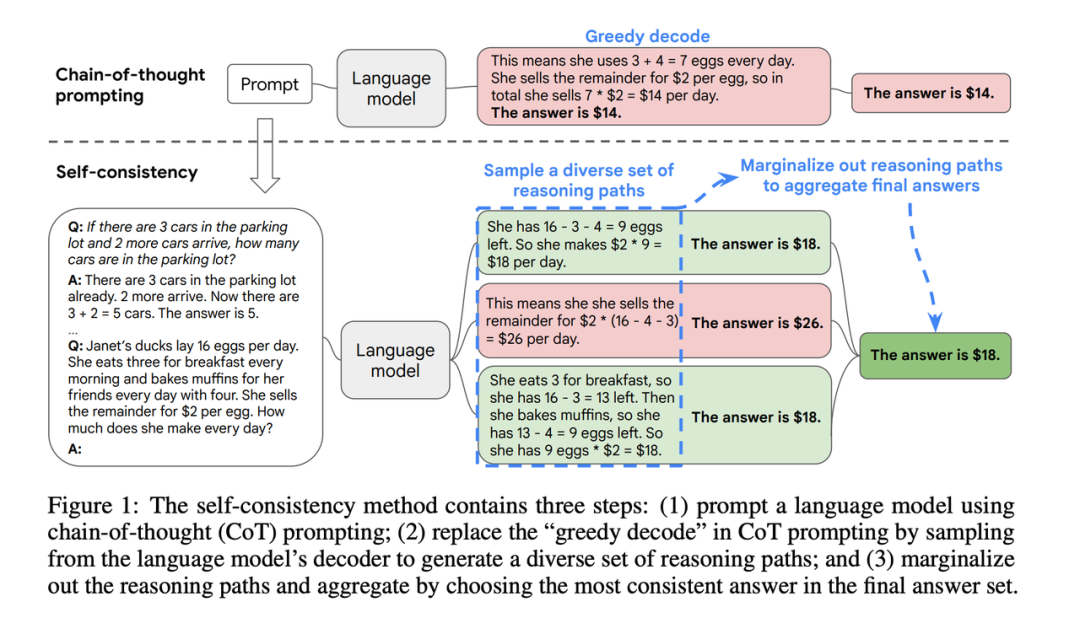
类似于 machine learning中的 vote的 embedding的玩法
执行很多次模型的推理
根据投票最多选择输出的结果 而Self-Consistency的思路是
都是通过CoT来引导LLM
对语言模型进行多次采样, 生成多个推理路径的结果
对不同推理路径生成结果基于投票策略选择最一致的答案进行输出
2.4 最少到最多提示过程(Least-To-Most)
论文来自ICLR2023:Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
Paper link:https://openreview.net/forum?id=WZH7099tgfM
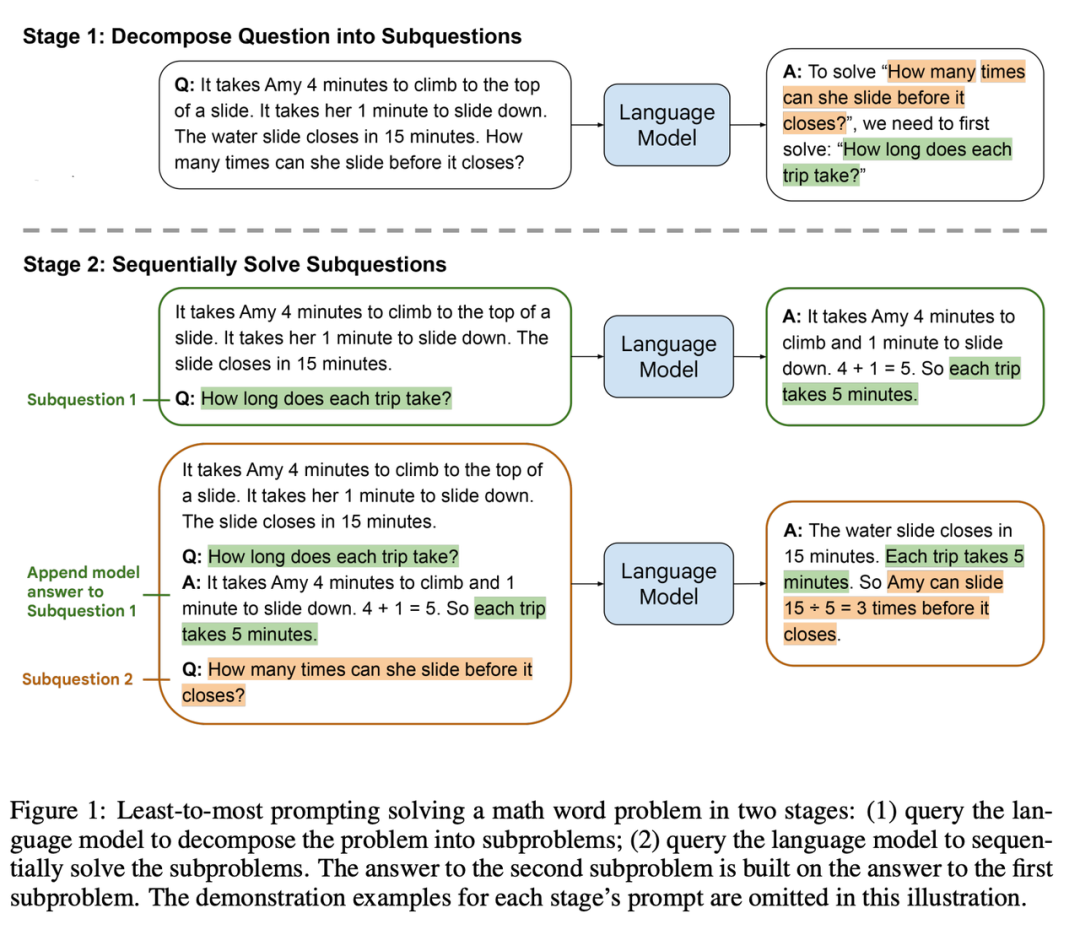
主要的思想就是 首先将问题分解为子问题,然后逐个解决,但是这里值得注意的是每个子问题的问答history信息都要放在下一次子问题的prompt中。论文图中已经特别详细给出了使用的方式,具体不赘述了
2.5 思维树(Tree-of-thought, ToT)
论文来源NIPS2023:Tree of Thoughts: Deliberate Problem Solving with Large Language Models
Paper link:https://arxiv.org/pdf/2305.10601.pdf
代码:https://github.com/princeton-nlp/tree-of-thought-llm
属于一个框架,不像前面说的实现上那么简单,轻便。主要引入BFS深度搜索的思想。
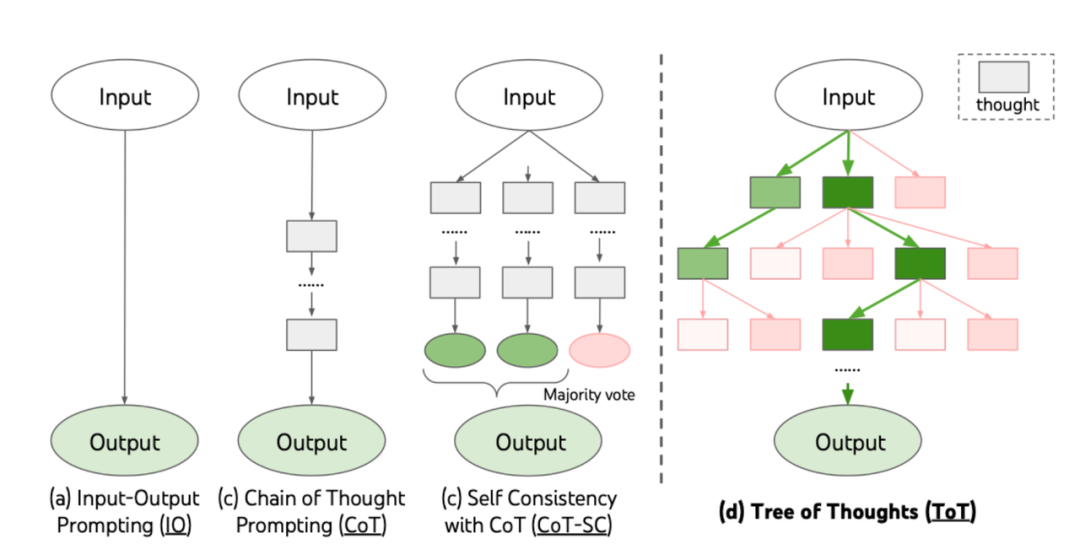
prompt位置:https://github.com/princeton-nlp/tree-of-thought-llm/blob/master/src/tot/prompts/text.py
bfs逻辑:https://github.com/princeton-nlp/tree-of-thought-llm/blob/master/src/tot/methods/bfs.py
主要的规则是:依旧使用“思想链”方法来提示语言模型,每一个“思想”作为解决问题的中间单元,允许 LLM 通过考虑多种不同的推理路径(BFS)和自我评估选择(类似于剪枝和回溯)来决定下一步行动路径,最终得到深思熟虑的output的效果
2.6检索增强生成(Retrieval Augmented Generation, RAG)
主要为了三点:
数据的保密性、私有性
数据的实时更新,相比于sft,更轻量
为了更好解决幻觉问题
主要的应用情况:
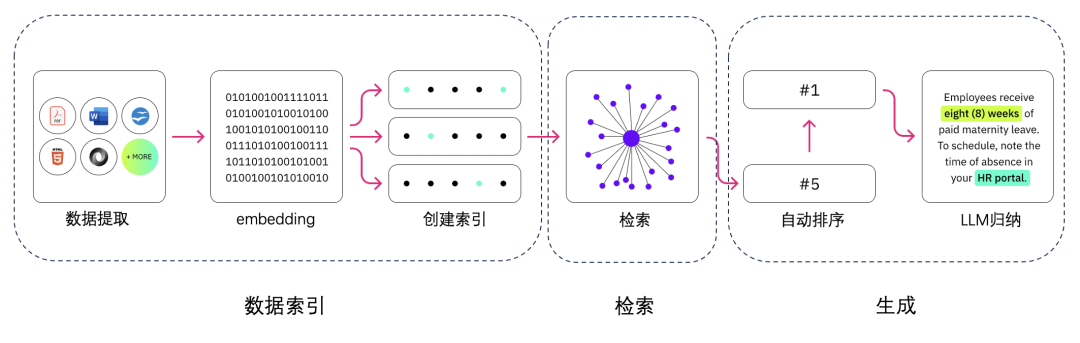
更新数据库的步骤
数据收集
文档切分
embedding得到数据对应的向量
存入向量数据库
LLM推理的过程
User input 向量化
检索数据集
得到topk的信息
再排序(可能存在)
检索结果插入到prompt中,作为knowledge的一部分
和LLM chat 这个领域工作比较多,后面慢慢看
Reference
https://prompt-guide.xiniushu.com/
https://www.promptingguide.ai/zh
推荐阅读:
公众号:AI蜗牛车
保持谦逊、保持自律、保持进步

发送【蜗牛】获取一份《手把手AI项目》(AI蜗牛车著)
发送【1222】获取一份不错的leetcode刷题笔记
发送【AI四大名著】获取四本经典AI电子书

















 339
339

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









