






前言
对于sft数据选择、数据构造、数据过滤等的总结
Instruction Mining: Instruction Data Selection for Tuning Large Language Models
COLM 2024 的paper
LLM 最初针对广泛的能力进行预训练,然后使用遵循指令的数据集进行微调,以提高其与人类交互的性能。尽管微调方面取得了进步,但选择高质量数据集来优化此过程的标准化指南仍然难以捉摸。
在本文中,提出INSTRUCTMINING方法,旨在自动选择优质指令数据集进行微调LLM。具体来说,IM 利用自然语言指标作为数据质量的衡量标准,将其应用于评估未见过的数据集。
在实验过程中,发现大型语言模型微调中存在双下降现象。基于这一观察,进一步利用 BLENDSEARCH 来帮助找到整个数据集中的最佳子集(即 100,000 个中的 2,532 个)。实验结果表明,在两个最流行的基准测试中实现了最先进的性能。
详细解读: https://zhuanlan.zhihu.com/p/714541894
ALPAGASUS: TRAINING A BETTER ALPACA WITH FEWER DATA
ICLR 2024
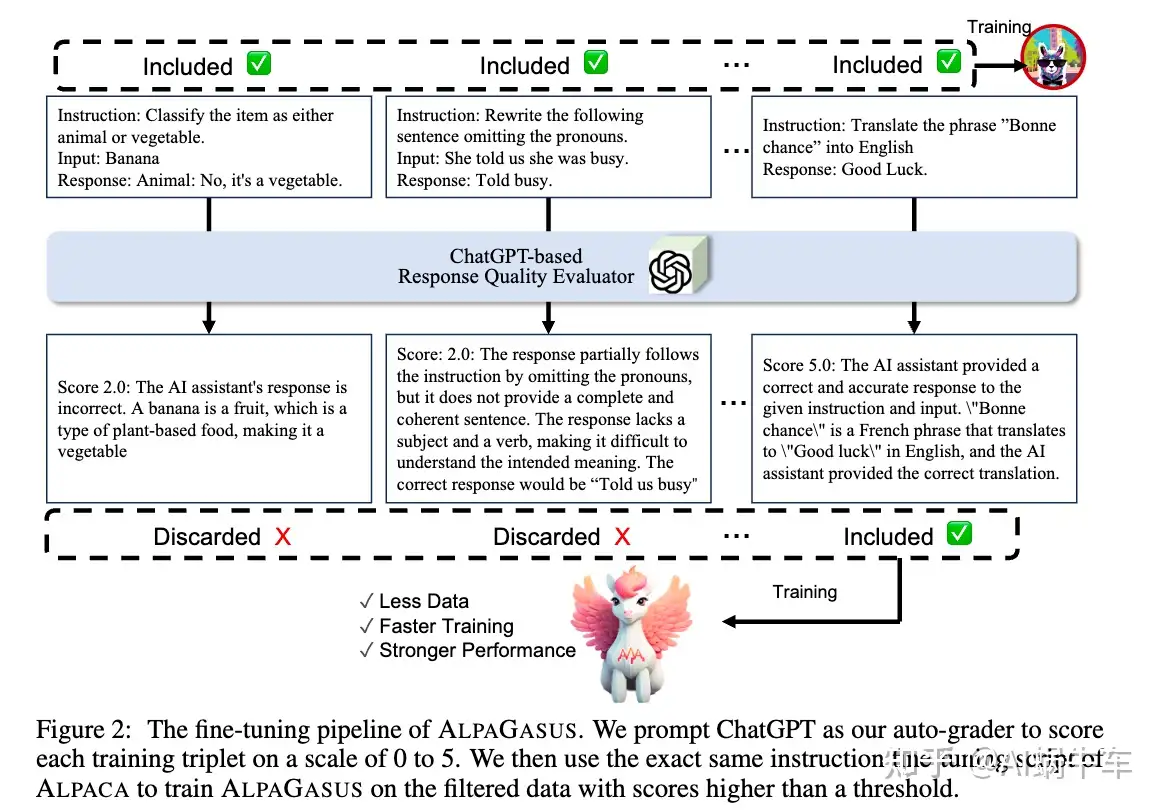
大型语言模型(LLMs )通过sft加强指令遵循能力。然而,广泛使用的数据集(例如 A 的 52k 数据)包含许多具有不正确或不相关响应的低质量样本,这对 微调 具有误导性。
本文 提出了一种简单有效的数据选择策略,该策略使用ChatGPT自动识别和过滤掉低质量数据。引入了: ALPAGASUS,它是仅对从52k训练数据中过滤出来的9k高质量数据进行微调。 AG 在多个测试集和受控人类评估上显着优于 GPT-4 评估的原始 Aas。将 7B 的训练时间从 80 分钟减少到 14 分钟。
详细解读:https://zhuanlan.zhihu.com/p/714969216
From Quantity to Quality: Boosting LLM Performance with Self-Guided Data Selection for Instruction Tuning
ACL24
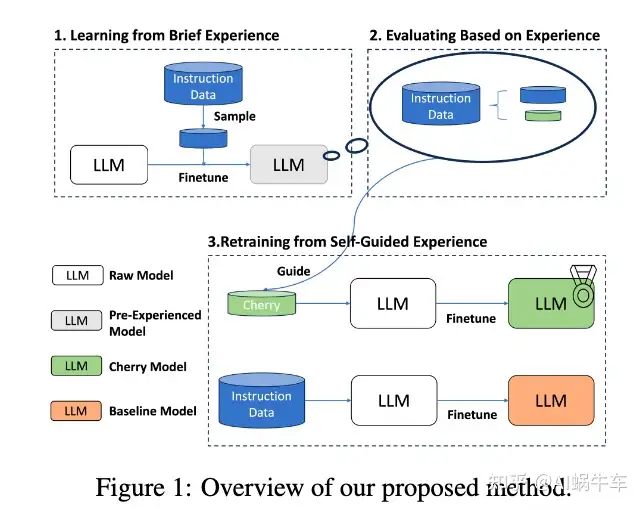
LLM领域中,指令数据质量和数量之间的平衡是一个重点。
本文中引入了一种自我引导的方法从开源数据集中自主识别和选择cherry样本,有效地减少人工管理和指令调整的潜在成本。
关键创新是指令遵循难度 (IFD) 指标,它是识别模型预期响应与其内在生成能力之间差异的关键指标。通过IFD指标精确选出cherry样本,从而显着提高模型训练效率。对 Alpaca 和 WizardLM 等数据集的实证验证。
详细解读:https://zhuanlan.zhihu.com/p/715591487
Self-Evolved Diverse Data Sampling for Efficient Instruction Tuning
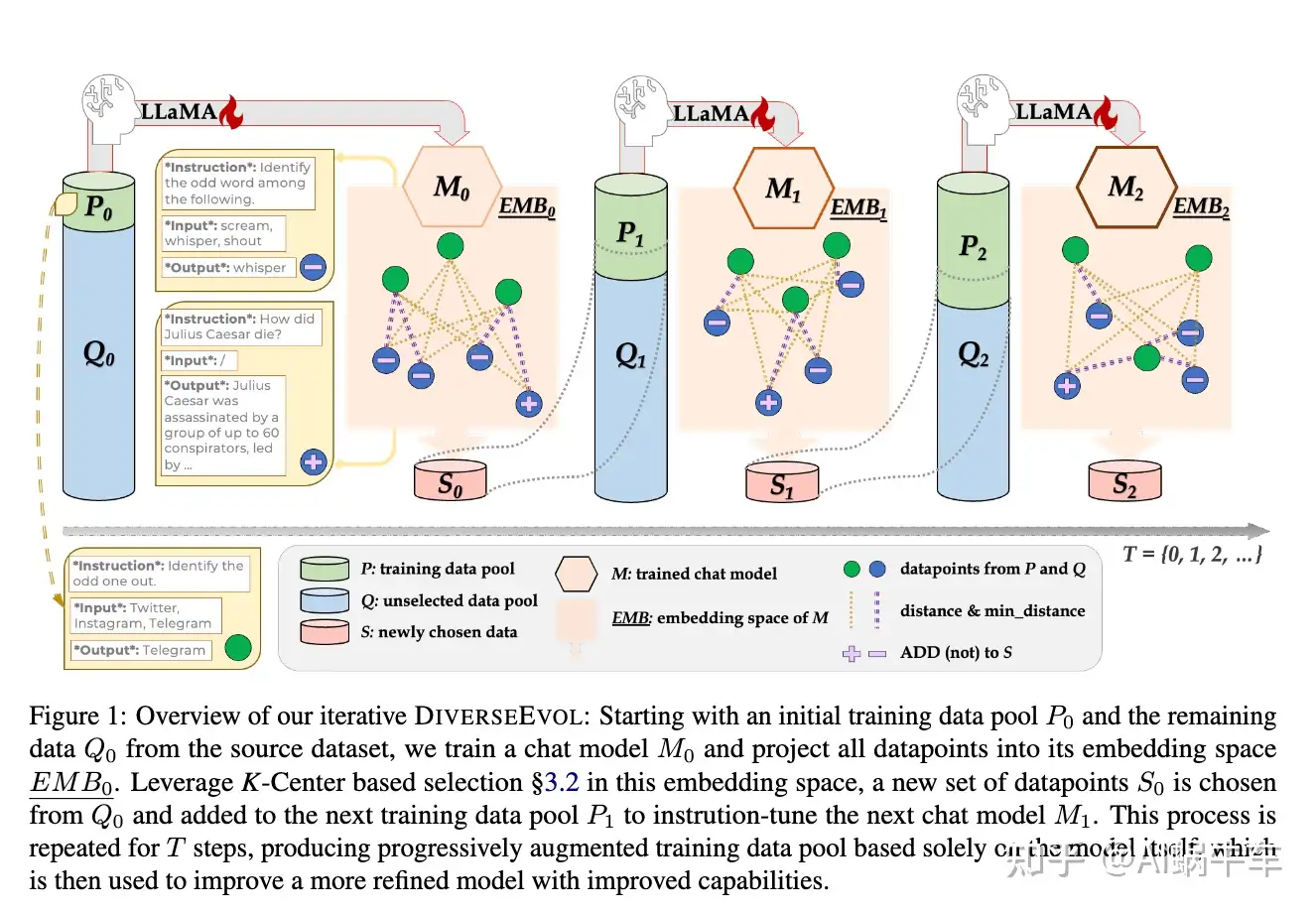
提升大型语言模型的指令遵循能力需要大量的sft数据集。然而,庞大的数量带来了相当大的计算负担和标注成本。为了研究一种label-efficient的指令微调方法,允许模型本身主动采样子集,引入了一种自进化机制DiverseEvol。
在此过程中,模型迭代地增强其训练子集以完善其自身的性能,而无需人类或更高级LLM的干预。数据采样技术的关键在于增强所选子集的多样性,因为模型根据其当前的embedding选择与任何现有数据点最不同的新数据点。
实验表明:模型在不到8%的原始数据集上进行训练,与完整数据训练相比,可以保持或提高性能。提供了实验证据来分析sft训练数据集多样性的重要性以及迭代采样方案相对于一次采样的的重要性。
详细解读:https://zhuanlan.zhihu.com/p/716017794
One-Shot Learning as Instruction Data Prospector for Large Language Models
ACL2024
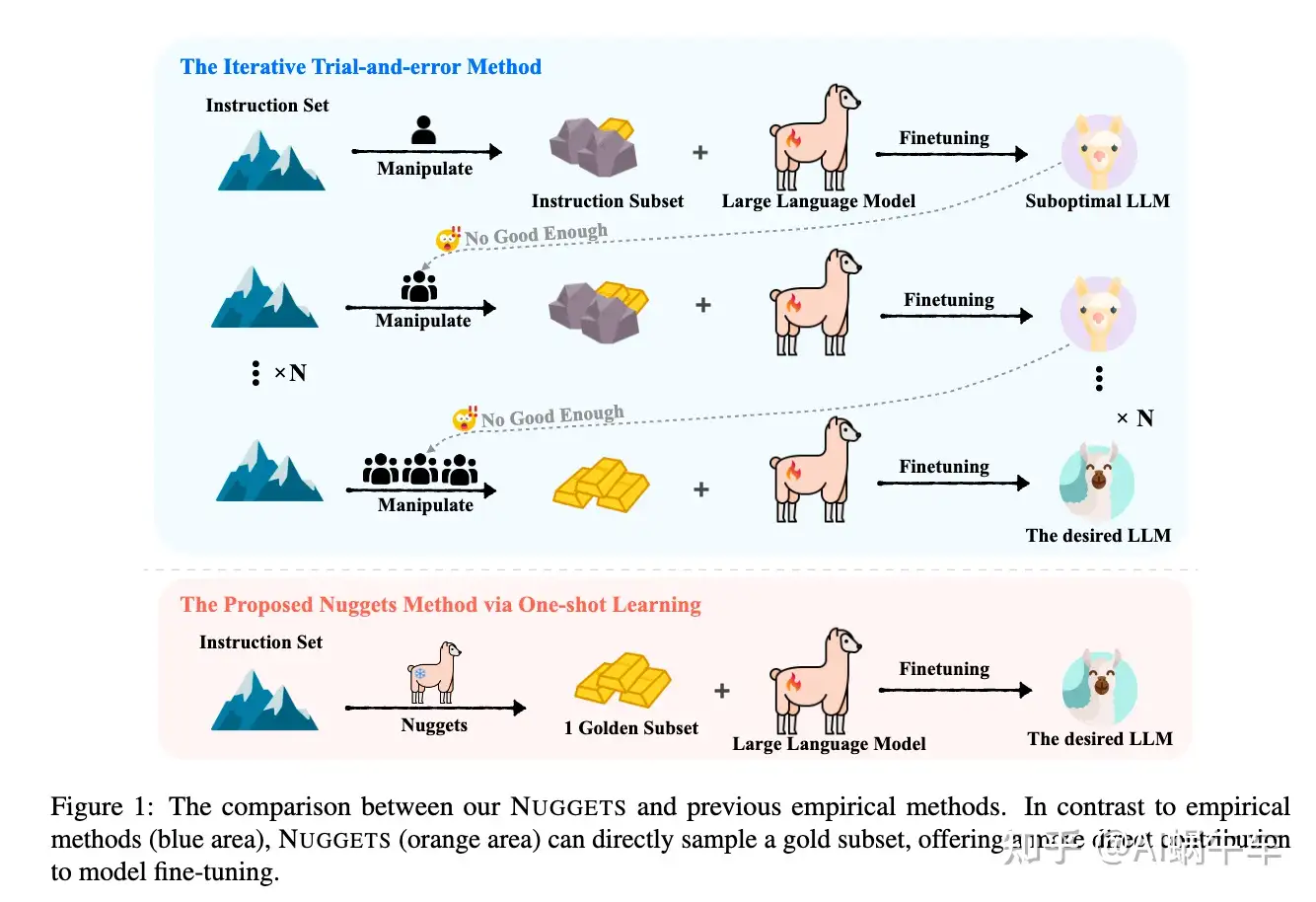
sft目前的实践通常取决于扩大数据规模,而没有明确的策略来确保数据质量,从而无意中引入可能会损害模型性能的噪声。
为了应对这一挑战,引入了Nuggets,它利用one shot learning从广泛的数据集中辨别和选择高质量的sft数据。
Nuggets评估单个指令示例作为有效的一次性学习实例的潜力,从而确定那些可以显着提高跨不同任务性能的实例。
通过对 MT-Bench 和 Alpaca-Eval 等两个基准的综合评估,发现使用NUGGETS的前1% examples进行sft明显优于使用整个数据集的传统方法。
详细解读:https://zhuanlan.zhihu.com/p/716511563
MoDS: Model-oriented Data Selection for Instruction Tuning
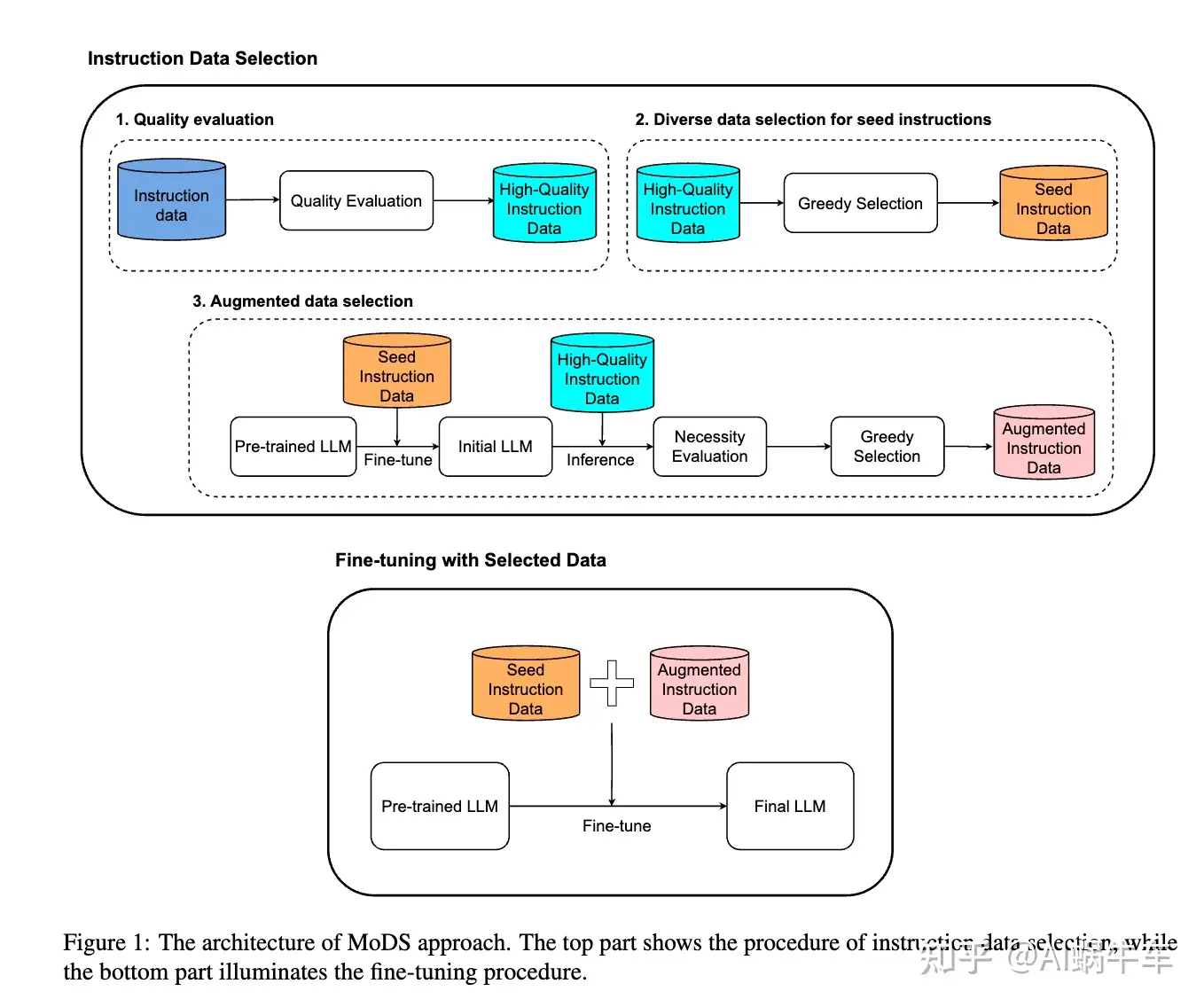
sft已经成为让LLM遵循用户指令的一种方式。通常,需要使用数十万个数据来微调基础LLM。最近,研究表明少量的高质量指令数据就足够。然而,如何在给定的数据中选择合适的指令数据?
为了解决这个问题,提出了一种面向模型的数据选择(MoDS)方法,该方法基于考虑三个方面的新标准来选择指令数据:质量、覆盖范围和必要性。
首先,利用质量评估模型从原始指令数据集中过滤出高质量子集,然后设计算法进一步从高质量子集中选择具有良好覆盖率的seed instruction dataset。应用seed数据集来微调基础LLM获得初始sft LLM。最后,用一个必要性评估模型来找出初始sft LLM效果较差的sft数据,将这些数据作为下一步改进LLM的必要指令。
从原始指令数据集中得到一个小的高质量、覆盖面广、必要性高的子集。实验结果表明,使用MoDS方法选择的 4,000 个指令对进行微调的模型比使用包含 214k 指令数据的完整原始数据集进行微调的模型表现更好。
详细解读:https://zhuanlan.zhihu.com/p/716857492

















 692
692

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









