







为什么要引入激活函数
如果不使用非线性的激活函数,无论叠加多少层,最终的输出依然只是输入的线性组合。
引入非线性的激活函数,使得神经网络可以逼近任意函数。
TensorFlow 中有如下激活函数
它们定义在 tensorflow-1.1.0/tensorflow/python/ops/nn.py 文件中,
这里包括平滑非线性的激活函数,如:
sigmoid、tanh、elu、softplus 和 softsign
也包括连续但不是处处可微的函数 :
relu、relu6、crelu 和 relu_x,
以及随机正则化函数dropout:
tensorflow中各激活函数的为:
tf.nn.relu()
tf.nn.sigmoid()
tf.nn.tanh()
tf.nn.elu()
tf.nn.bias_add()
tf.nn.crelu()
tf.nn.relu6()
tf.nn.softplus()
tf.nn.softsign()
tf.nn.dropout() # 防止过拟合,用来舍弃某些神经元
常用的激活函数
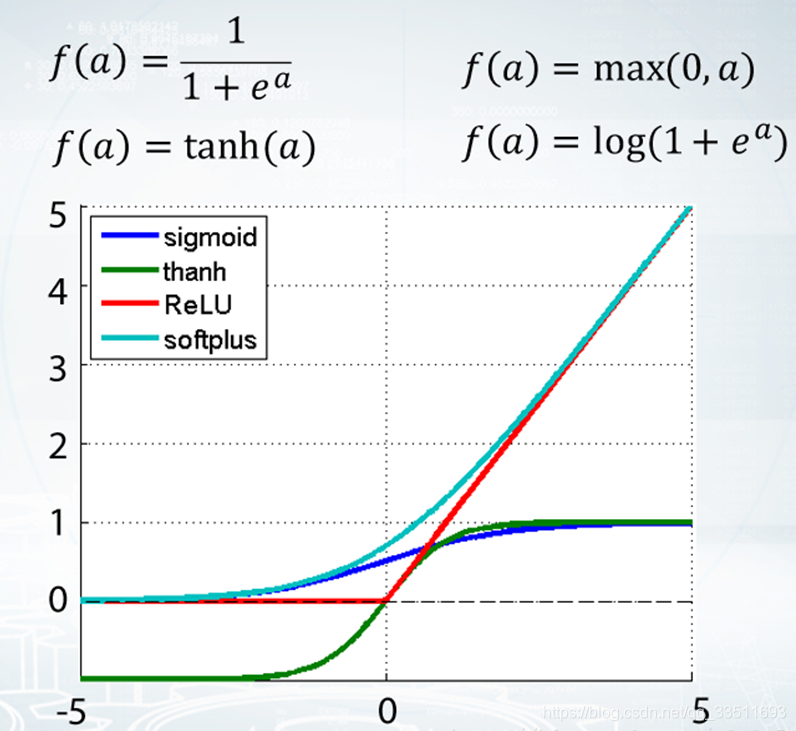
sigmoid函数
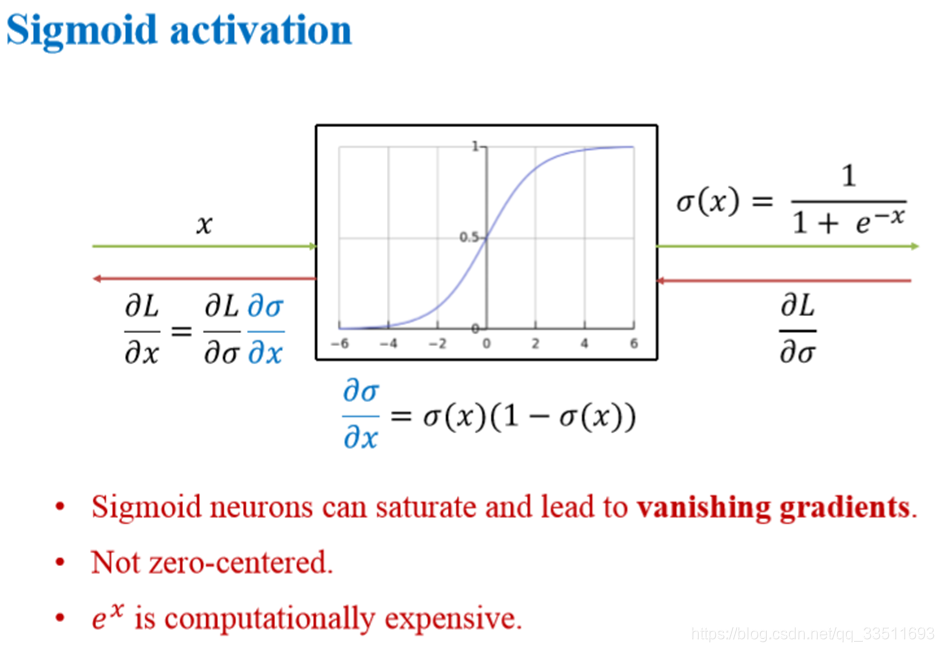
sigmoid函数,该函数是将取值为 (−∞ ,+∞)的数映射到 (0,1)(0,1) 之间。sigmoid函数的公式以及图形如下:
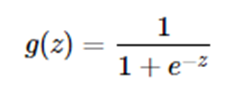
求导推导为:
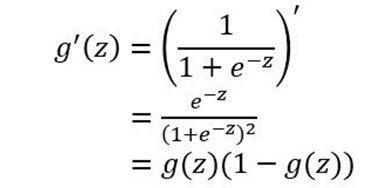
sigmoid函数作为非线性激活函数,但是其并不被经常使用,它具有以下几个缺点:
-
当 z 值非常大或者非常小时,通过上图我们可以看到,sigmoid函数的导数 g′(z) 将接近 0。这会导致权重 W 的梯度将接近 0
-
函数的输出不是以0为均值,将不便于下层的计算,具体可参考网页中的课程。sigmoid函数可用在网络最后一层,作为输出层进行二分类,尽量不要使用在隐藏层。
y_sigmoid = sess.run(tf.nn.sigmoid(x_vals))
tanh双曲正切函数
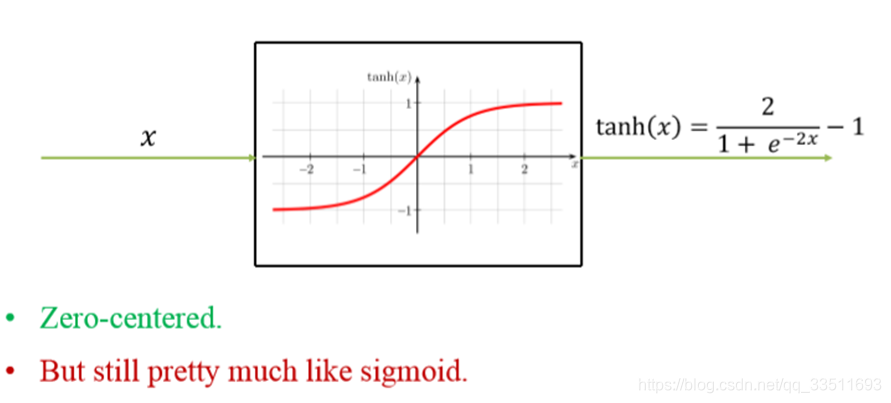
tanh函数相较于sigmoid函数要常见一些,该函数是将取值为 (−∞,+∞)(−∞,+∞) 的数映射到 (−1,1)(−1,1) 之间
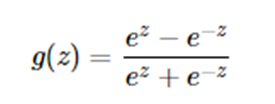
tanh函数在 0 附近很短一段区域内可看做线性的。由于tanh函数均值为 0,因此弥补了sigmoid函数均值为 0的缺点
tanh的求导公式为:
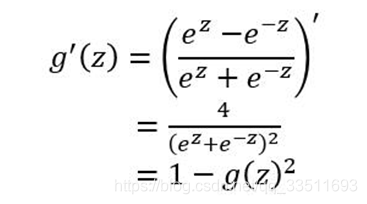
tanh函数的缺点同sigmoid函数的第一个缺点一样,当 z 很大或很小时,g′(z) 接近于 0 ,会导致梯度很小,权重更新非常缓慢,即梯度消失问题。
经验表明,在隐藏层中使用tanh函数的效果是优于sigmoid函数的,因为其输出更接近零均值。这会使得下一层的学习更加简单。
y_tanh = sess.run(tf.nn.tanh(x_vals))
ReLU修正线性单元
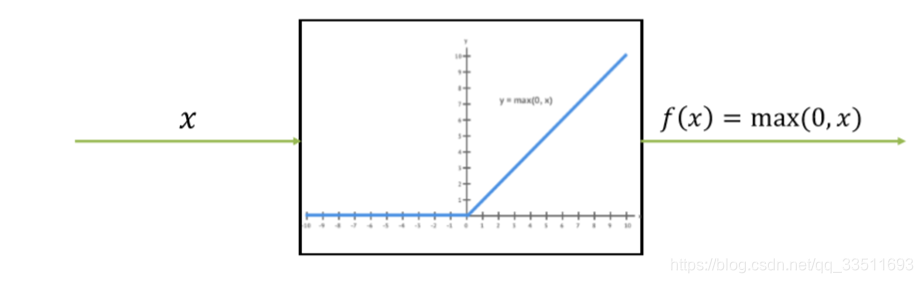
ReLU函数又称为修正线性单元(Rectified Linear Unit),是一种分段线性函数,其弥补了sigmoid函数以及tanh函数的梯度消失问题。
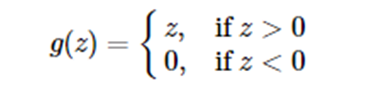
求导公式为:
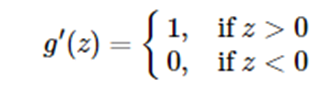
ReLU函数的优点:
- 在输入为正数的时候(对于大多数输入 z空间来说),不存在梯度消失问题。
- 计算速度要快很多。ReLU函数只有线性关系,不管是前向传播还是反向传播,都比sigmod和tanh要快很多。(sigmod和tanh要计算指数,计算速度会比较慢)
- Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生。
ReLU函数的缺点:
(1)当输入为负时,梯度为0,会产生梯度消失问题。
(2)学习率设计得过大会造成梯度为0,导致神经元死亡,并且是不可逆的。
在零点的导数不存在,在实际使用中,z不会恰好为0,一般为一个很小的浮点数,这时导数取0或1都可以。
ReLU易于优化。只要出现激活状态,导数都能保持较大。梯度不仅大而且一致。二阶导数几乎处处为0,并且在ReLU处于激活状态时,一阶导数处处为1。
通常将偏置b设置成一个小的正值,如0.1。使得其对训练集中大多数输入呈现激活状态,并且允许导数通过。
ReLU是最常用的激活函数。
y_relu = sess.run(tf.nn.relu(x_vals))
Leaky ReLU
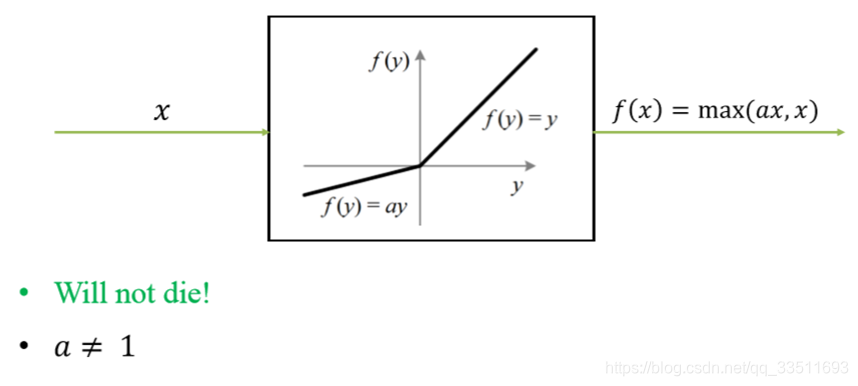
这是一种对ReLU函数改进的函数,又称为PReLU函数,但其并不常用。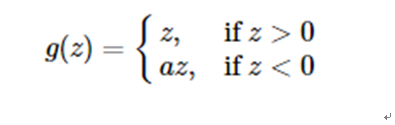
其中 a 取值在 (0,1) 之间。
Leaky ReLU函数的导数为:
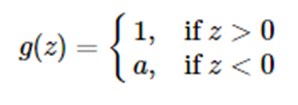
leakyrelu的优点
- 相比于sigmoid等,计算量小,
- 相比于sigmoid,不容易出现梯度消失情况,能加速网络训练速度
- 使得一些神经元输出为0,增加稀疏性,防止过拟合。
ELU
定义如下:
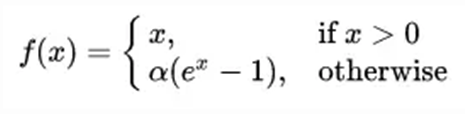
ELU也是为解决ReLU存在的问题而提出,显然,ELU有ReLU的基本所有优点,以及:
不会有Deal ReLU问题
输出的均值接近0,zero-centered,它的一个小问题在于计算量稍大。类似于Leaky ReLU,理论上虽然好于ReLU,但在实际使用中目前并没有好的证据ELU总是优于ReLU。
优点:
(1)ELU减少了正常梯度与单位自然梯度之间的差距,从而加快了学习。
(2)在负的限制条件下能够更有鲁棒性。
网址深度学习之激活函数的python实现方式
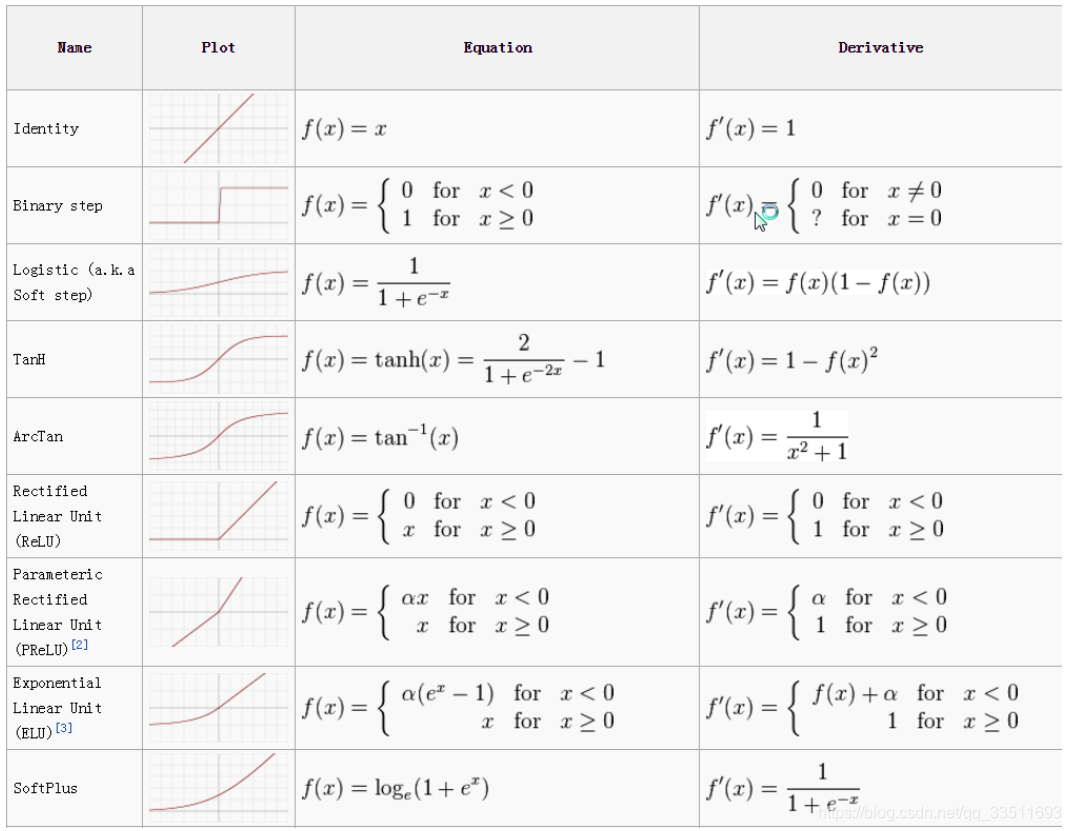
其他一些常用的激活函数如下:















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









