






电脑如何批量下载网页图片?在现代工作环境中,越来越多的人依赖电脑进行各种任务,其中之一就是批量下载网页图片。对于需要大量收集视觉素材的设计师、市场营销人员和内容创作者来说,批量下载网页图片不仅能提高工作效率,还能节省大量时间。本文将探讨批量下载网页图片的必要性以及一些实用的方法。如今,许多行业都强调视觉呈现,企业在营销活动中常常需要使用高质量的图片来吸引客户的注意。特别是在社交媒体、广告和网站设计中,丰富的图片资源能够增强内容的吸引力。因此,设计师和营销人员常常需要从不同的网站上收集大量的图片,以满足项目的需求。手动下载每一张图片不仅费时费力,而且容易出错。当你需要下载数十或数百张图片时,逐一保存的方式显得尤为低效。这时,批量下载工具的使用便显得尤为重要。通过使用一些专业的软件或浏览器扩展,用户可以一键下载网页上的所有图片,省去了繁琐的操作步骤。
为了帮助大家批量下载网页图片,小编专门去给大家找到了两个可实现的方法,配上详细的步骤可以让大家更加快速的稿定此任务,如果你正坐在电脑旁,就跟着步骤下载吧。

方法一:使用“星优图片下载助手”软件批量下载网页图片
软件下载地址:https://www.xingyousoft.com/softcenter/XYCapture
第1步,请在电脑上下载“星优图片下载助手”这个软件,下载好之后就可以安装了,安装结束后运行会用,随后本次请点击“其他网址”图片下载功能,进入下一步。
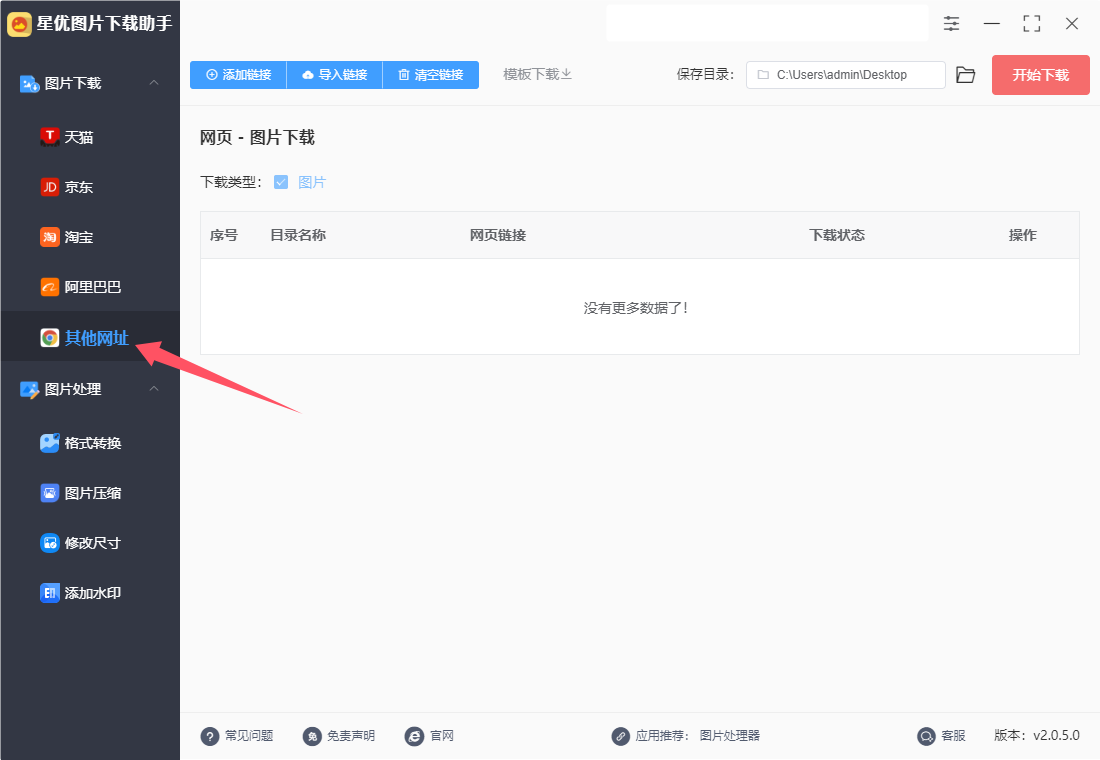
第2步,随后我们需要将网页链接添加到软件里,两个方式进行添加,下面是详细介绍:
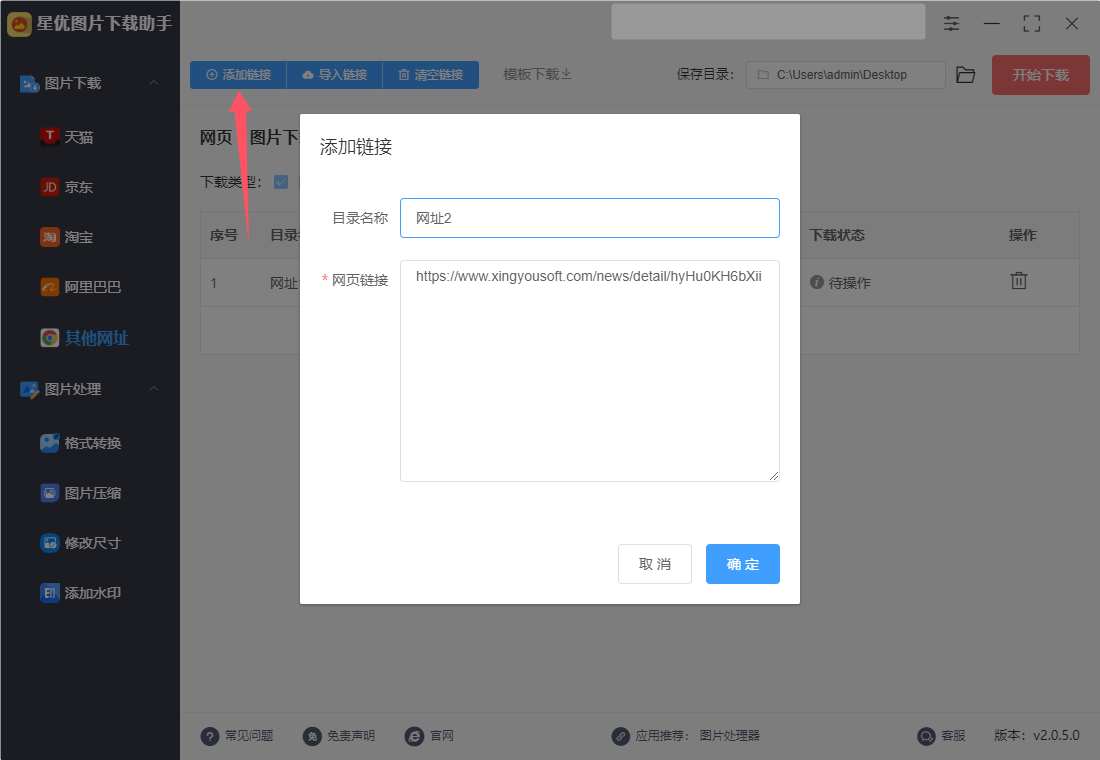
方式①,点击【添加连接】按键,随后会弹出添加窗口,输入链接名称和链接后即可提交添加,此方法一次只能添加一个链接,如果你有五个链接就需要添加五次。
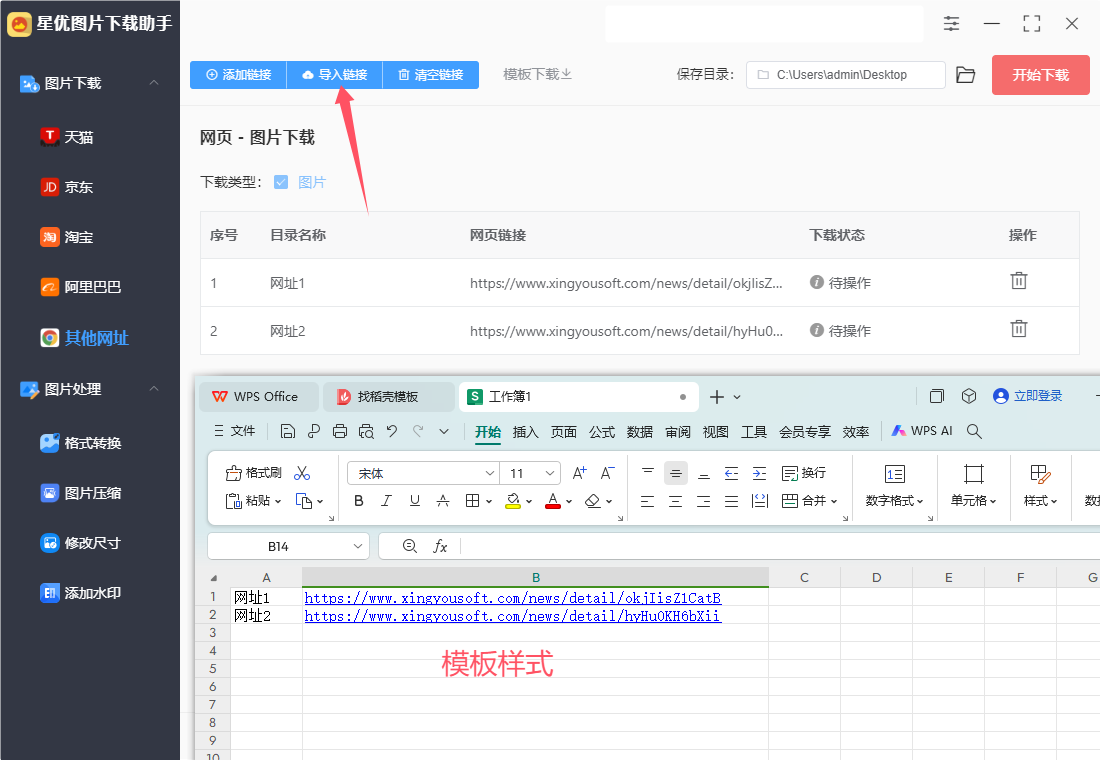
方式②,点击【导入链接】按键,然后将含有网页链接的excel文件导入到软件里,excel表格的第一列添加链接名,第二列添加网页链接,此方式适合批量导入链接。
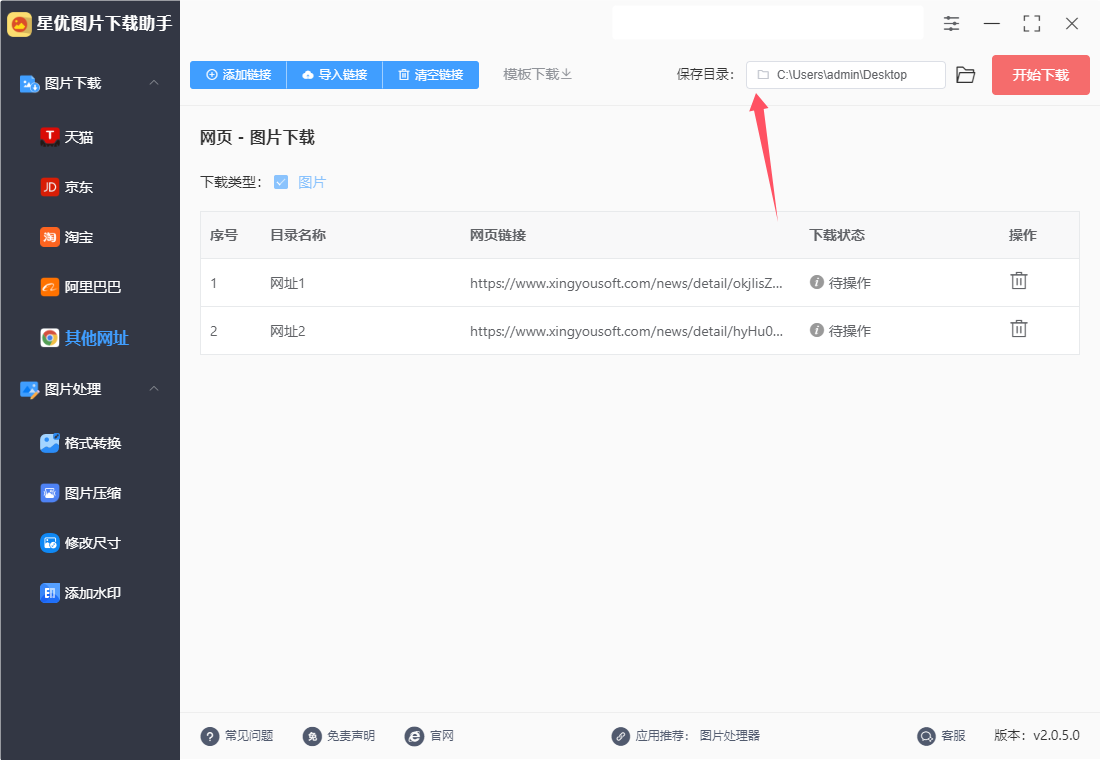
第3步(可选),然后设置一下保存目录,指定电脑上的一个文件夹用来保存下载下来的图片,当然你也可以忽略此步骤,软件默认保存到电脑桌面。
第4步,随后设置完成后,就可以点击【开始下载】红色启动图片批量下载程序了,下载时间的长短要看网页图片数量以及网络速度。
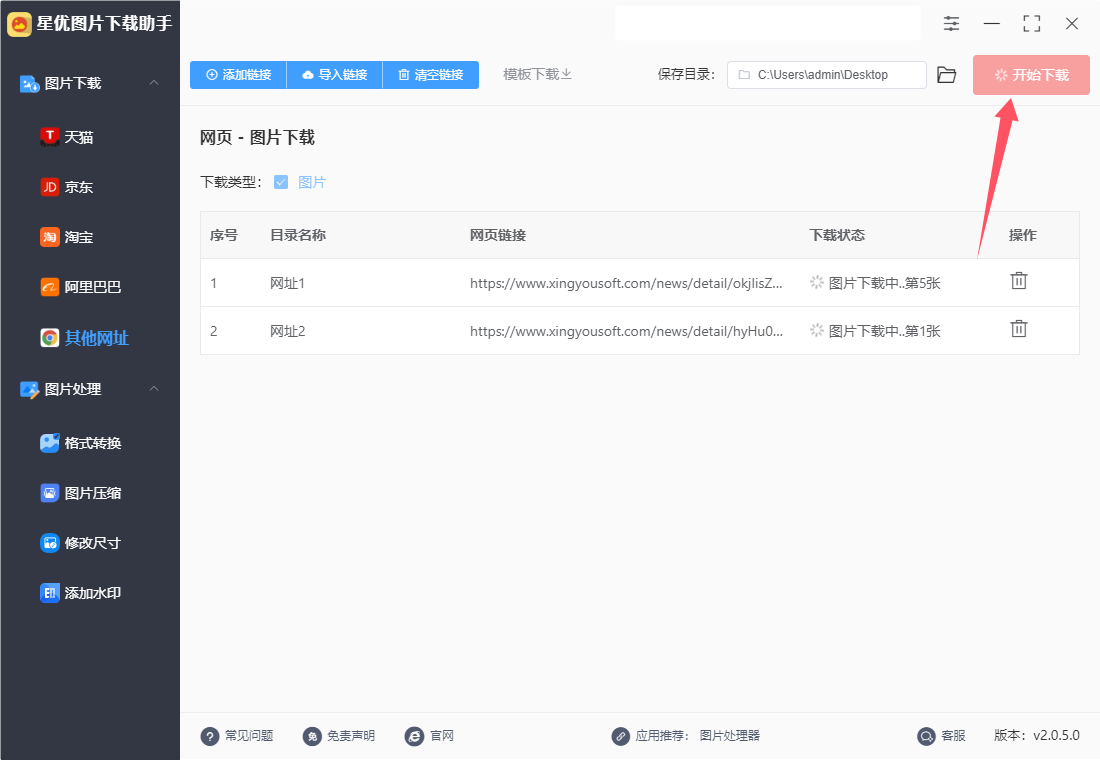
第5步,下载结束后软件会自动打开保存目录,在里面大家可以一条网址链接生成了一个文件夹,每条链接下载的图片则保存在相应的文件夹里。
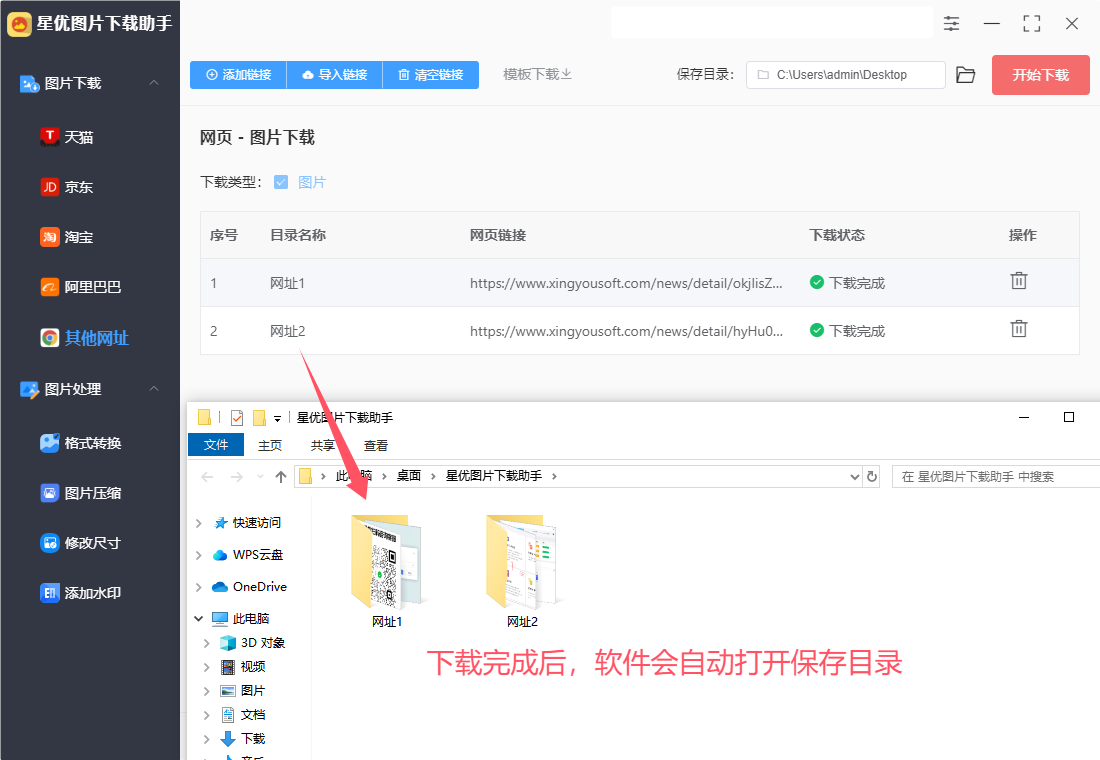
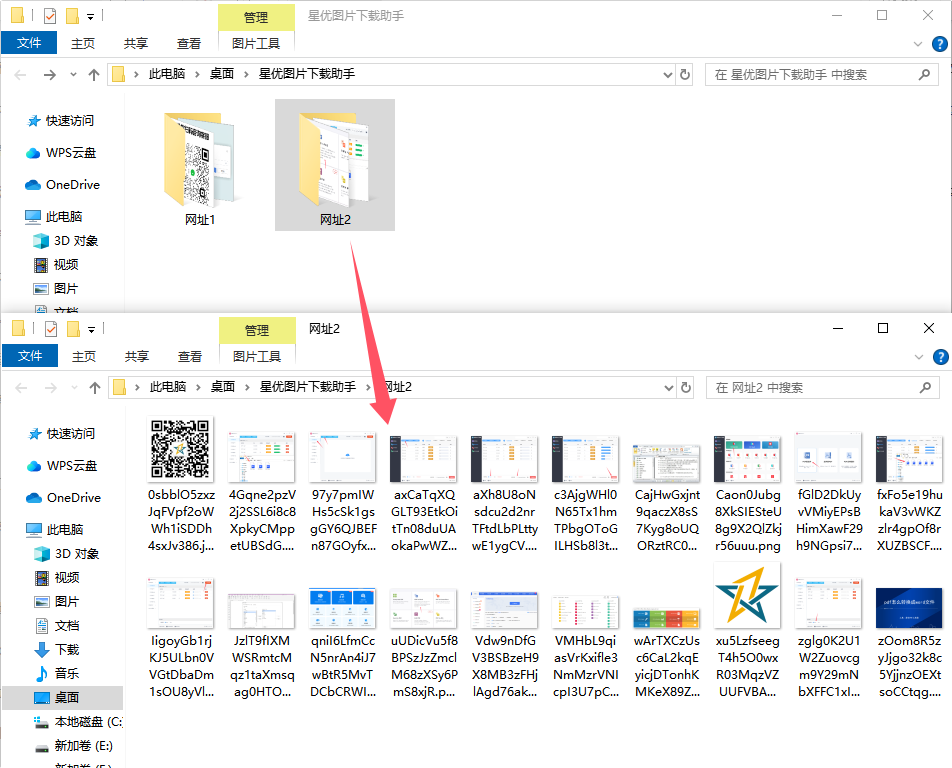
第6步,打开一个文件夹可以看到,成功将网页里的图片全部下载了下来。
方法二:借助BeautifulSoup批量下载网页图片
使用BeautifulSoup进行网页抓取是一个非常实用的技能,特别是当你需要批量提取网页中的图片链接并下载时。下面是一个完整的步骤和示例代码,教你如何使用BeautifulSoup和Requests库来实现这个功能。
环境准备
确保你已经安装了Requests和BeautifulSoup库。如果还没有安装,可以使用以下命令进行安装:
pip installRequestsbeautifulsoup4
步骤概述
发送请求并获取网页内容:使用Requests获取网页的 HTML 内容。
解析网页内容:使用BeautifulSoup解析 HTML,找到图片标签。
提取图片链接:从图片标签中提取出图片的 URL。
下载图片:将提取到的图片链接进行下载。
示例代码
以下是一个完整的示例代码,展示如何批量提取网页里的图片链接并下载这些图片。
import requests
from bs4 import BeautifulSoup
import os
def download_images(url, folder_name):
# 发送请求获取网页内容
response = requests.get(url)
if response.status_code != 200:
print(f"无法访问网页,状态码:{response.status_code}")
return
# 解析网页内容
soup = BeautifulSoup(response.content, 'html.parser')
# 创建存储图片的文件夹
if not os.path.exists(folder_name):
os.makedirs(folder_name)
# 找到所有图片标签
img_tags = soup.find_all('img')
img_urls = []
for img in img_tags:
# 提取图片链接
img_url = img.get('src')
if img_url:
# 处理相对路径
if img_url.startswith('/'):
img_url = url + img_url
img_urls.append(img_url)
# 下载图片
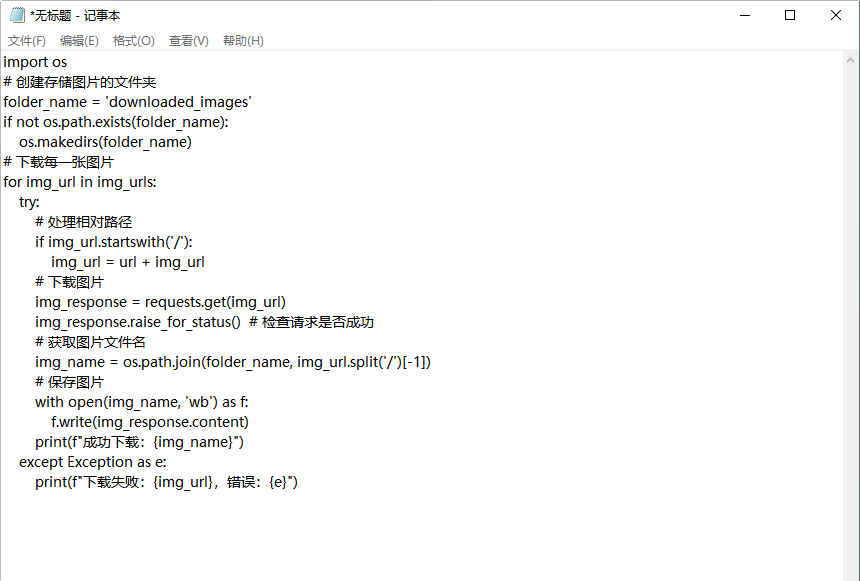
for img_url in img_urls:
try:
img_response = requests.get(img_url)
img_response.raise_for_status() # 检查请求是否成功
# 获取图片文件名
img_name = os.path.join(folder_name, img_url.split('/')[-1])
# 写入文件
with open(img_name, 'wb') as f:
f.write(img_response.content)
print(f"下载图片: {img_name}")
except Exception as e:
print(f"下载失败: {img_url},错误: {e}")
# 使用示例
url = 'https://example.com' # 替换为目标网页的 URL
folder_name = 'downloaded_images'
download_images(url, folder_name)
代码解释
发送请求:使用 requests.get(url) 发送 GET 请求,获取网页内容。
解析内容:BeautifulSoup(response.content, 'html.parser') 解析 HTML 内容。
提取图片:使用 soup.find_all('img') 找到所有的 <img> 标签,并提取 src 属性。
下载图片:对每个图片链接进行下载,使用 requests.get(img_url) 获取图片内容,并将其保存到指定文件夹中。
注意事项
相对路径:如果图片链接是相对路径,需要将其转换为绝对路径。
防止重复:在下载时可以考虑检查文件是否已经存在,以避免重复下载。
图片版权:确保你有权使用下载的图片。
通过以上步骤,你就可以方便地批量提取网页中的图片链接并下载这些图片了。这种方法在需要收集大量视觉素材时非常有用。
方法三:利用Requests库批量下载网页图片
利用Requests库批量下载网页图片是一项非常实用的技能,尤其是在需要快速收集大量视觉素材时。下面是详细的步骤和示例代码,帮助你使用Requests库实现这个功能。
环境准备
首先,确保你已经安装了Requests库。如果尚未安装,可以使用以下命令进行安装:
pip install requests
步骤概述
发送请求获取网页内容:使用Requests库发送 HTTP 请求,获取网页的 HTML 内容。
解析网页内容:可以使用BeautifulSoup解析 HTML(如果需要提取特定元素),或者直接从 HTML 中查找图片链接。
提取图片链接:找到网页中所有图片的 URL。
下载图片:使用Requests下载提取到的图片。
详细步骤
步骤 1: 发送请求获取网页内容
使用 requests.get() 方法获取网页的 HTML 内容。
import requests
# 目标网页 URL
url = 'https://example.com' # 替换为目标网页的 URL
response = requests.get(url)
# 检查请求是否成功
if response.status_code == 200:
print("成功获取网页内容")
else:
print(f"无法访问网页,状态码:{response.status_code}")
步骤 2: 解析网页内容
如果网页结构复杂,建议使用BeautifulSoup来解析 HTML 内容,以便更方便地提取图片链接。
from bs4 import BeautifulSoup
# 解析网页内容
soup = BeautifulSoup(response.content, 'html.parser')
步骤 3: 提取图片链接
找到网页中的所有 <img> 标签,并提取出 src 属性。
# 找到所有图片标签
img_tags = soup.find_all('img')
img_urls = []
# 提取每个图片的链接
for img in img_tags:
img_url = img.get('src')
if img_url:
img_urls.append(img_url)
# 打印提取到的图片链接
print("提取到的图片链接:")
for img_url in img_urls:
print(img_url)
步骤 4: 下载图片
使用Requests下载每个提取到的图片,并将其保存到本地。
import os
# 创建存储图片的文件夹
folder_name = 'downloaded_images'
if not os.path.exists(folder_name):
os.makedirs(folder_name)
# 下载每一张图片
for img_url in img_urls:
try:
# 处理相对路径
if img_url.startswith('/'):
img_url = url + img_url
# 下载图片
img_response = requests.get(img_url)
img_response.raise_for_status() # 检查请求是否成功
# 获取图片文件名
img_name = os.path.join(folder_name, img_url.split('/')[-1])
# 保存图片
with open(img_name, 'wb') as f:
f.write(img_response.content)
print(f"成功下载:{img_name}")
except Exception as e:
print(f"下载失败:{img_url},错误:{e}")
完整代码示例
以下是完整的代码示例,将上述所有步骤合并在一起:
import requests
from bs4 import BeautifulSoup
import os
def download_images(url):
# 发送请求获取网页内容
response = requests.get(url)
if response.status_code != 200:
print(f"无法访问网页,状态码:{response.status_code}")
return
# 解析网页内容
soup = BeautifulSoup(response.content, 'html.parser')
# 创建存储图片的文件夹
folder_name = 'downloaded_images'
if not os.path.exists(folder_name):
os.makedirs(folder_name)
# 找到所有图片标签
img_tags = soup.find_all('img')
img_urls = []
# 提取图片链接
for img in img_tags:
img_url = img.get('src')
if img_url:
# 处理相对路径
if img_url.startswith('/'):
img_url = url + img_url
img_urls.append(img_url)
# 下载图片
for img_url in img_urls:
try:
img_response = requests.get(img_url)
img_response.raise_for_status() # 检查请求是否成功
# 获取图片文件名
img_name = os.path.join(folder_name, img_url.split('/')[-1])
# 写入文件
with open(img_name, 'wb') as f:
f.write(img_response.content)
print(f"成功下载:{img_name}")
except Exception as e:
print(f"下载失败:{img_url},错误:{e}")
# 使用示例
url = 'https://example.com' # 替换为目标网页的 URL
download_images(url)
注意事项
请求频率:如果需要下载大量图片,建议在每次请求之间添加延时,避免对服务器造成负担。
相对路径处理:确保正确处理相对路径,将其转换为绝对路径。
图片版权:请遵循相关法律法规,确保下载和使用图片的合法性。
处理异常:确保代码能够处理各种异常情况,例如请求失败、文件写入错误等。
在日常工作中,经常需要收集并整理大量网页图片以支持项目展示或内容创作。面对这一需求,掌握在电脑上批量下载网页图片的技巧显得尤为重要。通过使用专业的图片下载工具或浏览器扩展,可以大大提高工作效率。这些工具通常支持设置过滤条件,只下载特定类型的图片(如JPEG、PNG),并能根据网页结构自动识别并提取图片链接。此外,部分工具还支持多线程下载,进一步缩短了下载时间。在进行批量下载时,也应注意版权问题,确保所下载的图片均可用于商业或非商业用途。总之,合理利用批量下载工具,不仅能有效减轻重复劳动,还能确保收集到高质量的图片资源,为工作增添助力。为了方便大家,小编在文章中给大家介绍了几个“电脑如何批量下载网页图片?”的解决办法,方法步骤清晰可靠,赶紧去试试看吧。















 1795
1795

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









