







#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
// Matrices are stored in row-major order:
// M(row, col) = *(M.elements + row * M.width + col)
typedef struct {
int width;
int height;
int stride;
int* elements;
} Matrix;
// Thread block size
#define BLOCK_SIZE 2
// Matrix size
#define MATRIX_SIZE 4
void constantInit(int *elements, int size)
{
for (int i = 0; i < size; ++i)
{
elements[i] = (int)(rand() % 10 + 1);
}
}
/*
void constantInitA(int *elements, int size)
{
for (int i = 0; i < size; ++i)
{
elements[i] = i+1;
}
}
void constantInitB(int *elements, int size)
{
for (int i = 0; i < size; ++i)
{
elements[i] = i + 17;
}
}
*/
void printMatrix(Matrix *matrix)
{
int index;
int matrixSize = matrix->height*matrix->width;
for (int i = 0; i < matrix->height; i++)
{
for (int j = 0; j < matrix->width; j++)
{
index = i * (matrix->width) + j;
if (index < matrixSize)
{
printf("%3d ", matrix->elements[index]);
}
else
{
printf("the index is overflow for your Matrix!\n");
}
}
printf("\n");
}
printf("\n");
}
void multiplicateMatrixOnHost(Matrix *array_A, Matrix *array_B, Matrix *array_C, int M_p, int K_p, int N_p)
{
for (int i = 0; i < M_p; i++)
{
for (int j = 0; j < N_p; j++)
{
double sum = 0;
for (int k = 0; k < K_p; k++)
{
sum += array_A->elements[i*K_p + k] * array_B->elements[k*N_p + j];
}
array_C->elements[i*N_p + j] = sum;
}
}
}
__device__ void SetElement(const Matrix A, int row, int col, double value)
{
A.elements[row * A.stride + col] = value;
}
__device__ double GetElement(const Matrix A, int row, int col)
{
return A.elements[row * A.stride + col];
}
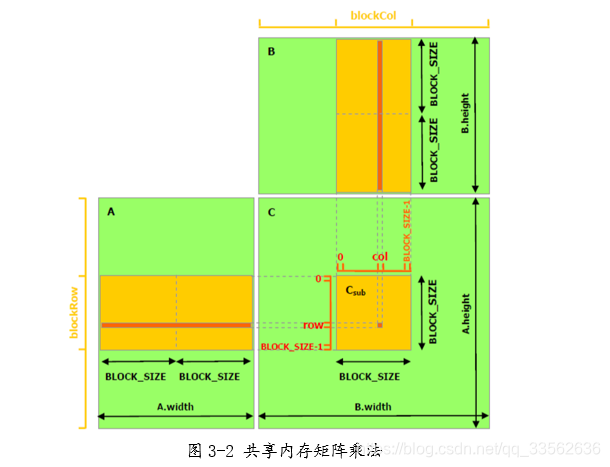
//获取A的BLOCK_SIZE*BLOCK_SIZE的子矩阵ASUB
__device__ Matrix GetSubMatrix(Matrix A, int row, int col)
{
Matrix Asub;
Asub.width = BLOCK_SIZE;
Asub.height = BLOCK_SIZE;
Asub.stride = A.stride;
Asub.elements = &A.elements[A.stride * BLOCK_SIZE * row + BLOCK_SIZE * col];
// printf("Asub.elements:%d\n",A.elements[A.stride * BLOCK_SIZE * row + BLOCK_SIZE * col]);
return Asub;
}
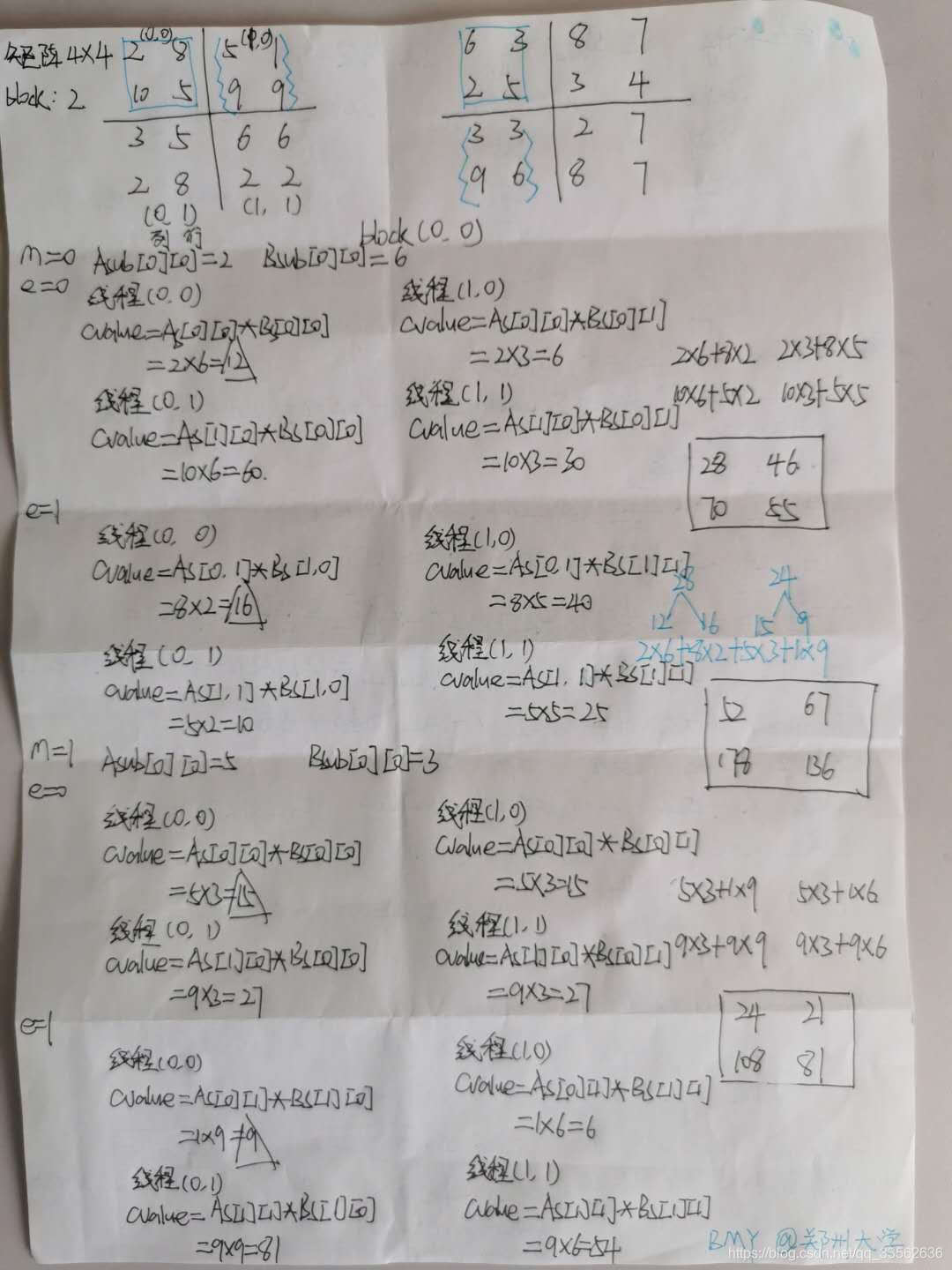
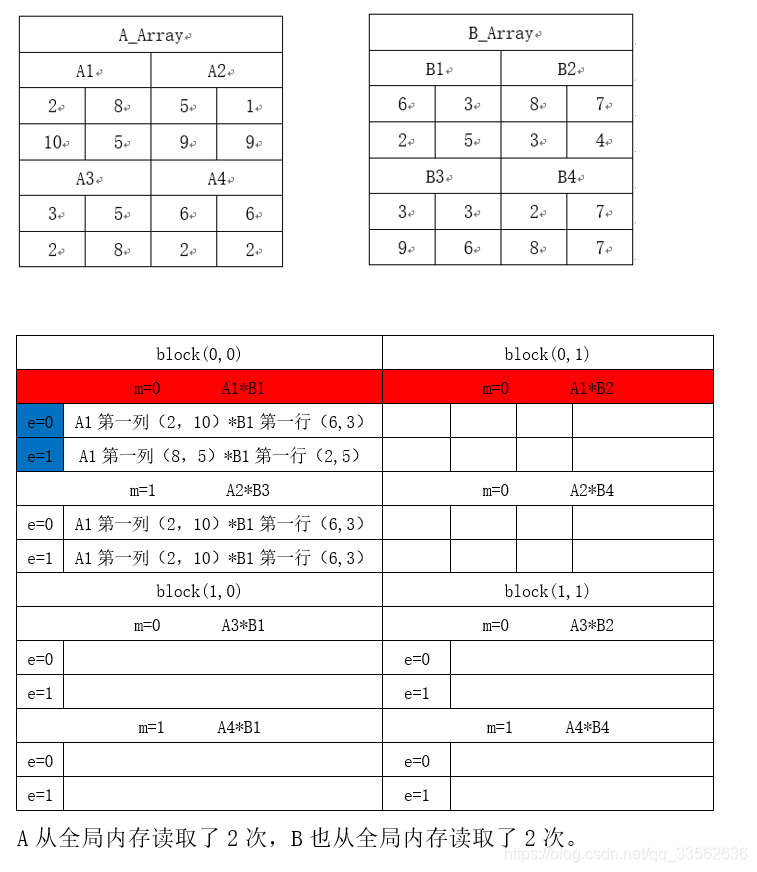
__global__ void MatMulKernel(const Matrix A, const Matrix B, Matrix C)
{
//将行和列分块
int blockRow = blockIdx.y;
int blockCol = blockIdx.x;
//每个线程块计算C的一个子矩阵Csub
Matrix Csub = GetSubMatrix(C, blockRow, blockCol);
//每个线程计算Csub中的一个元素,通过将结果累加到Cvalue
double Cvalue = 0;
//Csub中的线程行列
int row = threadIdx.y;
int col = threadIdx.x;
//循环遍历A和B的所有子矩阵,以计算Csub,并对每个子矩阵相乘,将结果累加
for (int m = 0; m < (A.width / BLOCK_SIZE); ++m)
{
/*
printf("blockRow %d\n",blockRow);
printf("blockCol %d\n", blockCol);
*/
//获取A B 的子矩阵Asub Bsub
Matrix Asub = GetSubMatrix(A, blockRow, m);
Matrix Bsub = GetSubMatrix(B, m, blockCol);
//分别用于保存子矩阵Asub Bsub的共享内存
__shared__ double As[BLOCK_SIZE][BLOCK_SIZE];
__shared__ double Bs[BLOCK_SIZE][BLOCK_SIZE];
//将Asub Bsub加载到共享内存中,每个线程加载每个子矩阵的一个元素
As[row][col] = GetElement(Asub, row, col);
Bs[row][col] = GetElement(Bsub, row, col);
__syncthreads();
for (int e = 0; e < BLOCK_SIZE; ++e)
{
Cvalue += As[row][e] * Bs[e][col];
}
__syncthreads();
}
//将Csub写入设备内存 ,每个线程写一个元素
SetElement(Csub, row, col, Cvalue);
}
int main(int argc, char **argv)
{
clock_t start = 0, finish = 0;
double time;
int devID = 0;
cudaSetDevice(devID);
cudaDeviceProp deviceProp;
cudaGetDevice(&devID);
cudaGetDeviceProperties(&deviceProp, devID);
/*
printf("GPU Device %d: \"%s\" with compute capability %d.%d\n\n",
devID, deviceProp.name, deviceProp.major, deviceProp.minor);
*/
//Alloc and init host matrix
Matrix A, B, C;
A.width = A.height = A.stride = MATRIX_SIZE;
B.width = B.height = B.stride = MATRIX_SIZE;
C.width = C.height = C.stride = MATRIX_SIZE;
int size_A = A.width * A.height;
int size_B = B.width * B.height;
int size_C = C.width * C.height;
int mem_size_A = sizeof(int) * size_A;
int mem_size_B = sizeof(int) * size_B;
int mem_size_C = sizeof(int) * size_C;
A.elements = (int *)malloc(mem_size_A);
B.elements = (int *)malloc(mem_size_B);
C.elements = (int *)malloc(mem_size_C);
constantInit(A.elements, size_A);
constantInit(B.elements, size_B);
printf("\n");
printf(" Matrix_A: (%d×%d)\n", A.height, A.width);
printMatrix(&A);
printf(" Matrix_B: (%d×%d)\n", B.height, B.width);
printMatrix(&B);
start = clock();
multiplicateMatrixOnHost(&A, &B, &C, MATRIX_SIZE, MATRIX_SIZE, MATRIX_SIZE);
finish = clock();
time = (double)(finish - start) / CLOCKS_PER_SEC;
printf("\n");
printf(" ------------------------------------------------------------------------------------\n");
printf(" Computing matrix product using multiplicateMatrixOnHost \n");
printf(" ------------------------------------------------------------------------------------\n\n");
printf(" Matrix_hostRef: (%d×%d) CPU运行时间为:%lfs\n", C.height, C.width, time);
printMatrix(&C);
//Alloc and init device matrix
Matrix d_A;
d_A.width = A.width;
d_A.height = A.height;
d_A.stride = A.stride;
cudaMalloc(&d_A.elements, mem_size_A);
cudaMemcpy(d_A.elements, A.elements, mem_size_A, cudaMemcpyHostToDevice);
Matrix d_B;
d_B.width = B.width;
d_B.height = B.height;
d_B.stride = B.stride;
cudaMalloc(&d_B.elements, mem_size_B);
cudaMemcpy(d_B.elements, B.elements, mem_size_B, cudaMemcpyHostToDevice);
Matrix d_C;
d_C.width = C.width;
d_C.height = C.height;
d_C.stride = C.stride;
cudaMalloc(&d_C.elements, mem_size_C);
//launch warmup kernel
dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE);
dim3 dimGrid(C.width / dimBlock.x, C.height / dimBlock.y);
printf(" ------------------------------------------------------------------------------------\n");
printf(" Computing matrix product using multiplicateMatrixOnDevice_block \n");
printf(" ------------------------------------------------------------------------------------\n\n");
//------------------------------------------------------ Computing matrix product using MatMulKernel
cudaEvent_t gpustart, gpustop;
float elapsedTime = 0.0;
cudaEventCreate(&gpustart);
cudaEventCreate(&gpustop);
cudaEventRecord(gpustart, 0);
// cudaLaunchKernelGGL(MatMulKernel, dim3(dimGrid), dim3(dimBlock), 0, 0, d_A, d_B, d_C);
MatMulKernel << <dimGrid, dimBlock >> > (d_A, d_B, d_C);
//copy back
cudaDeviceSynchronize();
cudaEventRecord(gpustop, 0);
cudaEventSynchronize(gpustop);
cudaEventElapsedTime(&elapsedTime, gpustart, gpustop);
cudaMemcpy(C.elements, d_C.elements, mem_size_C, cudaMemcpyDeviceToHost);
cudaDeviceSynchronize();
printf(" Matrix_deviceRef: (%d×%d) <<<(%d,%d),(%d,%d)>>> GPU运行时间为:%fs\n",
C.height, C.width, dimGrid.x, dimGrid.y, dimBlock.x, dimBlock.y, elapsedTime / 1000);
// printf("\n 加速比为: (%lf/%lf)=%lf\n", time, (elapsedTime) / 1000, time / (elapsedTime / 1000));
cudaEventDestroy(gpustart);
cudaEventDestroy(gpustop);
printMatrix(&C);
free(A.elements);
free(B.elements);
free(C.elements);
cudaFree(d_A.elements);
cudaFree(d_B.elements);
cudaFree(d_C.elements);
return 0;
}
block(0,0)执行流程

















 246
246

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









