







文中所示公式以Andrew Ng CS229课程的讲义为主
定义:求解无约束最优化问题的一种常用方法,用负梯度方向为搜索方向的,梯度下降法越接近目标值,步长越小,前进越慢
算法实现:属于迭代算法,每一步都需要求解目标函数的梯度向量
1.参数方程
假设特征有X1,X2, , 则方程有:

一般而言,我们为了简化公式,可以假设 X0 = 1 , 此时方程可以写作:
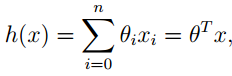 (
此处n表示的是特征个数)
(
此处n表示的是特征个数)
注:
θ 为学习算法的参数,学习算法即利用训练集合的选择或者学习得到合适的参数值。 (
θ ∈R ,
θ 包含(
θ1,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 5404
5404

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











