







一方面,在很多任务场景下,出 于人工成本的限制,无法获取足够的最优专家样本 供模仿学习智能体得到充分的训练,这种情况下必 须依赖于从次优专家样本中获取信息.另一方面,算 法性能过于依赖样本数据的品质,一旦专家数据集 上含有次优专家样本,对这类数据的直接模仿将使 算法性能大打折扣.因此,研究混合专家样本建模, 是提升模仿学习数据利用效率并最终提升算法性能 亟待解决的问题.
DWBC(Discriminator鄄Weighted Behavioral Cloning),结合对抗生成式网络和行为克隆,以分辨 专家样本和非专家样本这一任务训练判别器,并以 收敛后判别器的输出结果作为权重系数,计算行为 克隆损失,优化策略参数
上述方法均依赖对专家样本进行预处理 以获取相对排序或真实奖励等先验知识,耗费大量 人工标注成本.
针对混合专家样本数据集上模仿学习算法性能损失问题,提出基于噪声对比估计的权重自适 应对抗生成式模仿学习算法(GLANCE)
1)特征提取器的训练.利用最优专家样本及噪声 专家样本进行噪声对比估计,得到具有特征选择作 用的特征提取器,使次优专家样本的状态表征更接 近最优专家样本
2)权重系数的学习.先运行对抗生 成式模仿学习算法,再利用奖励函数预测的样本排 序和真实排序计算排序误差作为损失函数,优化专 家样本的权重系数.通过权重系数对专家数据进行 重分布,使其数据分布进一步接近最优专家策略,进 而提高模仿学习算法性能
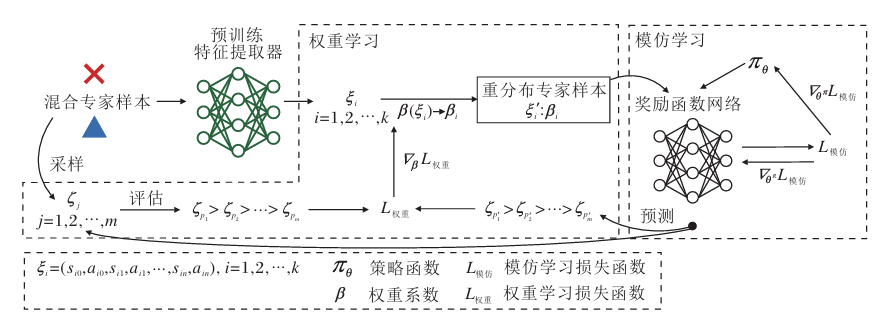
为 了尽可能减少因直接对次优专家样本进行模仿而造 成的模仿学习策略性能损失,引入特征提取器,使次 优专家样本状态表征尽可能接近最优专家样本
即通过最小化两者的KL散度达到使次优专家样本 状态表征接近最优专家样本状态表征的目的. GLANCE使用对抗生成式训练框架训练特征提取器 E[
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









