






稳定对比强化学习:基于离线数据的机器人目标达成技术
Chongyi Zheng 、Benjamin Eysenbach 、Homer Walke 、Patrick Yin 、Kuan Fang 、Sergey Levine 、Ruslan Salakhutdinov
1 卡内基梅隆大学;2 普林斯顿大学;3 加州大学伯克利分校;4 华盛顿大学;5 康奈尔大学
arXiv:2306.03346v2 [cs.LG] 2024 年 2 月 26 日
发表于 2024 年国际学习
表征会议(ICLR)
摘要
主要依赖自监督学习的机器人系统,有望减少学习控制策略所需的人工标注和工程工作量。正如先前的机器人系统借鉴了计算机视觉(CV)和自然语言处理(NLP)中的自监督技术一样,我们的工作基于先前研究,这些研究表明强化学习(RL)本身可视为一个自监督问题:即学习在没有人为指定奖励或标签的情况下达成任何目标。尽管这一概念颇具吸引力,但几乎没有先前研究展示出自监督 RL 方法在机器人系统上的实际应用。通过首先研究这一任务具有挑战性的模拟版本,我们确定了关于架构和超参数的设计决策,这些决策将成功率提高了两倍。这些发现为我们的主要成果奠定了基础:我们证明了基于对比学习的自监督 RL 算法,能够解决基于图像的现实世界机器人操作任务,且任务仅需在训练后提供单一目标图像来指定。
1 引言
自监督学习是许多 NLP 和计算机视觉应用的基础,它利用未标记数据为下游任务获取良好的特征表示。我们如何让机器人学习算法具备类似的能力呢?在 NLP 和计算机视觉领域,自监督学习通常通过一个目标(通常是去噪)来实现,而下游任务则使用不同的目标(例如线性回归)。在 RL 环境中,先前的研究表明,(自监督)对比学习目标可以同时用于学习:(1)紧凑的特征表示;(2)目标条件策略;(3)相应的值函数(Eysenbach 等人,2022,《Contrastive learning as goal-conditioned reinforcement learning》)。从机器人学的角度来看,这种框架很有吸引力,因为用户无需手动指定这些组件(例如,无需调整奖励函数中的超参数)。
将这种自监督的目标条件 RL 应用于现实世界的机器人任务面临着一些挑战。首先,由于许多自监督学习的工作主要集中在 CV 和 NLP 领域,这些领域的最新创新可能无法直接应用于 RL 环境。其次,RL 环境所需的合适特征表示,不仅需要捕捉有关环境动态的细微和详细信息,还需要了解哪些状态可能导向特定的目标状态。这与典型的计算机视觉特征表示形成对比,后者主要关注静态图像中物体之间的关系(例如用于分类或分割)。尽管如此,这一挑战也带来了机遇:通过自监督 RL 算法学习到的特征表示,可能不仅包含图像本身的信息,还包含潜在的决策问题信息;它们可能不仅告诉我们图像中包含什么,还能指导如何生成实现其他图像目标的计划。
本文的目标是:(1)构建一种有效的目标条件 RL 方法,使其能够在现实世界的机器人数据集上运行;(2)理解该方法与先前方法之间的差异;(3)通过实证分析解释我们的方法表现更优的原因。虽然从机器人学的角度来看,我们使用的数据集规模较大,但不可否认的是,它们比计算机视觉和 NLP 领域的数据集小得多。我们将重点关注一类基于对比 RL 的先前 RL 方法(Touati & Ollivier,2021,《Learning one representation to optimize all rewards》;Eysenbach 等人,2022;2020,《C-learning: Learning to achieve goals via recursive classification》;Guo 等人,2018,《Neural predictive belief representations》)。为了实现现实世界的应用,我们首先研究架构、初始化和数据增强如何稳定这些对比 RL 方法,同时关注它们学习到的特征表示和策略。通过仔细的实验,我们发现了一组关于模型容量和正则化的设计决策,与先前的对比 RL 实现相比,这些决策将性能提高了 45%,相对于其他目标条件 RL 方法,性能提升了两倍。我们将我们的实现称为稳定对比 RL。我们的主要贡献在于现实世界的实验,在这些实验中,我们证明了这些设计决策能够实现基于图像的机器人操作。额外的实验揭示了所学特征表示的一个有趣特性:线性插值似乎与规划相对应 linear interpolation seems to corresponds to planning(见图 6)。
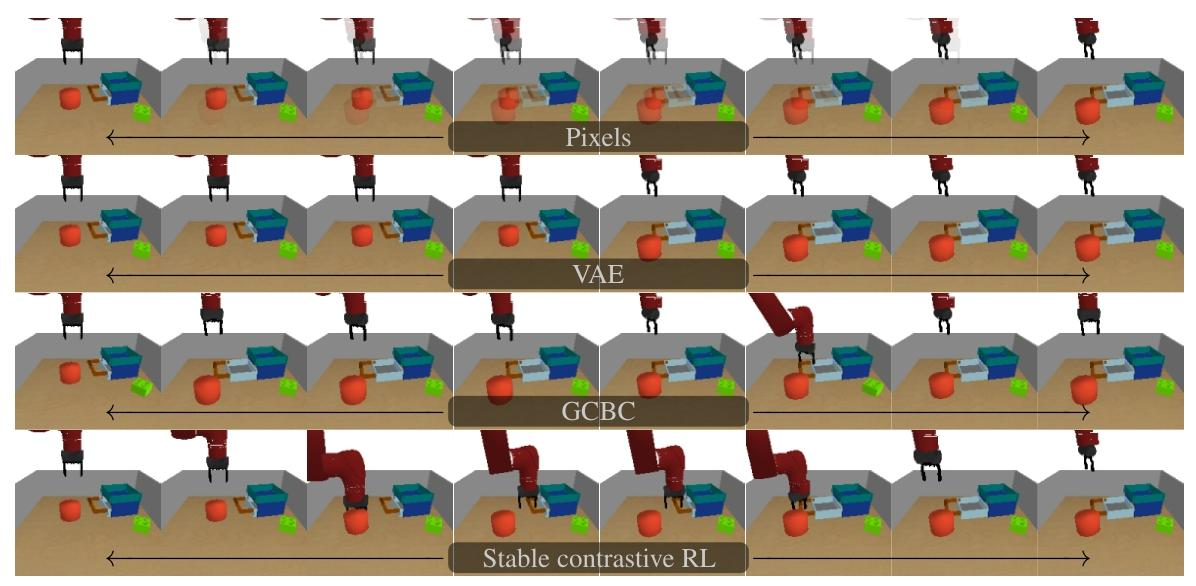
图6:学习到的表征可视化。(第一行)在像素空间中直接对两张图像进行插值,会生成不真实的图像。(第二行)使用变分自编码器(VAE),我们对最左边和最右边图像的表征进行插值,并可视化从验证集中检索到的最近邻图像。VAE能够捕捉图像的内容,但无法捕捉因果关系——物体在没有被机器人手臂触碰的情况下移动了。(第三行)基于目标条件的行为克隆(GCBC)同样生成了真实的图像,但忽略了时间因果关系。(第四行)稳定对比强化学习(RL)学习到的表征不仅能捕捉图像的内容,还能捕捉因果关系——机器人手臂首先从目标状态中的位置移开,以便将物体移动到合适的位置。
2 相关工作
本文建立在先前关于自监督强化学习(RL)的研究基础之上,这一问题在目标条件强化学习、表征学习和模型学习等背景下得到了广泛研究。本文旨在探究哪些设计元素对于解锁一类有前景的自监督 RL 算法的能力至关重要。
- 目标条件强化学习:我们的工作基于大量先前关于目标条件 RL 的研究(Kaelbling,1993,《Learning to achieve goals》;Schaul 等人,2015,《Universal value function approximators》),这种问题设定很有吸引力,因为它可以完全以自监督的方式(无需人为奖励)来表述,并且允许用户通过简单提供目标图像来指定任务。该领域的先前工作大致可分为条件模仿学习方法(Lynch 等人,2020,《Learning latent plans from play》;Ding 等人,2019,《Goal-conditioned imitation learning》;Ghosh 等人,2020,《Learning to reach goals via iterated supervised learning》;Srivastava 等人,2019,《Training agents using upside-down reinforcement learning》;Gupta 等人,2020,《Relay policy learning: Solving long-horizon tasks via imitation and reinforcement learning》)和演员 - 评论家方法(Eysenbach 等人,2020;2022)。理论上,这些自监督方法应足以解决任意目标达成任务,但先前研究发现,添加额外的表征损失(Nair 等人,2018,《Visual reinforcement learning with imagined goals》;Nasiriany 等人,2019,《Planning with goal-conditioned policies》)、规划模块(Fang 等人,2022a,《Planning to practice: Efficient online fine-tuning by composing goals in latent space》;Savinov 等人,2018,《Semi-parametric topological memory for navigation》;Chane-Sane 等人,2021,《Goal-conditioned reinforcement learning with imagined subgoals》)和精心挑选的训练示例(Chebotar 等人,2021,《Actionable models: Unsupervised offline reinforcement learning of robotic skills》;Tian 等人,2020,《Model-based visual planning with self-supervised functional distances》)可以提高性能。本文研究这些组件是否是严格必要的,或者它们的功能是否可以从单个自监督目标中自然涌现。
- RL 中的表征学习:学习紧凑的视觉表征是将离线数据整合到 RL 算法中的常用方法(Baker 等人,2022,《Video pretraining (vpt): Learning to act by watching unlabeled online videos》;Ma 等人,2022b,《Vip: Towards universal visual reward and representation via value-implicit pre-training》;Nair 等人,2022,《R3m: A universal visual representation for robot manipulation》;Sermanet 等人,2018,《Time-contrastive networks: Self-supervised learning from video》;Yang & Nachum,2021,《Representation matters: offline pretraining for sequential decision making》;Such 等人,2019,《An atari model zoo for analyzing, visualizing, and comparing deep reinforcement learning agents》;Wang 等人,2022,《Investigating the properties of neural network representations in reinforcement learning》;Annasamy & Sycara,2019,《Towards better interpretability in deep q-networks》)。一些先前方法直接使用现成的视觉表征学习组件,如特定于感知的损失(Finn 等人,2016,《Deep spatial autoencoders for visuomotor learning》;Lange & Riedmiller,2010,《Deep auto-encoder neural networks in reinforcement learning》;Watter 等人,2015,《Embed to control: A locally linear latent dynamics model for control from raw images》;Stooke 等人,2021,《Decoupling representation learning from reinforcement learning》;Shridhar 等人,2023,《Perceiver-actor: A multi-task transformer for robotic manipulation》;Goyal 等人,2023,《Rvt: Robotic view transformer for 3d object manipulation》;Gervet 等人,2023,《Act3d: 3d feature field transformers for multi-task robotic manipulation》)和数据增强(Laskin 等人,2020b、a,《Reinforcement learning with augmented data》《Curl: contrastive unsupervised representations for reinforcement learning》;Yarats 等人,2021,《Mastering visual continuous control: Improved data-augmented reinforcement learning》;Raileanu 等人,2021,《Automatic data augmentation for generalization in reinforcement learning》)来学习这些表征;其他工作则使用针对 RL 问题定制的表征学习目标(Ajay 等人,2020,《Opal: Offline primitive discovery for accelerating offline reinforcement learning》;Singh 等人,2020,《Parrot: Data-driven behavioral priors for reinforcement learning》;Zhang 等人,2020,《Learning invariant representations for reinforcement learning without reconstruction》;Gelada 等人,2019,《Deepmdp: Learning continuous latent space models for representation learning》;Han 等人,2021,《Learning domain invariant representations in goal-conditioned block mdps》;Rakelly 等人,2021,《Which mutual-information representation learning objectives are sufficient for control?》;Florensa 等人,2019,《Self-supervised learning of image embedding for continuous control》;Choi 等人,2021,《Variational empowerment as representation learning for goal-conditioned reinforcement learning》)。虽然这些方法取得了不错的效果,且其模块化设计使实验更易于进行(无需为每个实验重新训练表征),但它们将表征学习问题与 RL 问题解耦。我们的实验将表明,这种解耦可能导致学习到的表征无法很好地适应解决 RL 问题。通过适当的设计决策,自监督 RL 方法能够自行获取良好的表征。
- RL 中的模型学习 Model Learning in RL:另一类工作使用离线数据集来学习显式模型。虽然这些方法能够实现单步前向预测(Ha & Schmidhuber,2018,《World models》;Matsushima 等人,2020,《Deployment-efficient reinforcement learning via model-based offline optimization》;Wang & Ba,2019,《Exploring model-based planning with policy networks》)和自回归虚拟滚动(Finn & Levine,2017,《Deep visual foresight for planning robot motion》;Ebert 等人,2018,《Visual foresight: Model-based deep reinforcement learning for vision-based robotic control》;Nair 等人,2018;Yen-Chen 等人,2020,《Experience-embedded visual foresight》;Suh & Tedrake,2021,《The surprising effectiveness of linear models for visual foresight in object pile manipulation》),这是更一般的视频预测问题(Mathieu 等人,2015,《Deep multi-scale video prediction beyond mean square error》;Denton & Fergus,2018,《Stochastic video generation with a learned prior》;Kumar 等人,2019,《Videoflow: A flow-based generative model for video》)的一个子集,但模型输出通常会在预测未来状态时迅速退化(Janner 等人,2019,《When to trust your model: Model-based policy optimization》;Yu 等人,2020b,《Mopo: Model-based offline policy optimization》)。最终,拟合模型是一个自监督问题,而实际使用该模型进行规划或 RL 时则需要监督。附录 A 对这些先前方法进行了比较。
3 对比强化学习和设计决策
在本节中,我们将介绍相关符号和目标条件 RL 目标,然后修改我们在实验中使用的先前算法,并提及重要的设计决策。
3.1 预备知识:
我们假设一个目标条件控制的马尔可夫过程(一个没有奖励函数的 MDP),由状态![]() 、目标
、目标![]() 、动作
、动作、初始状态分布
![]() 和动态转移函数
和动态转移函数![]() 定义。我们将学习一个目标条件策略
定义。我们将学习一个目标条件策略![]() ,其中状态s和目标g均为 RGB 图像。给定一个策略
,其中状态s和目标g均为 RGB 图像。给定一个策略![]() ,我们将定义
,我们将定义![]() 为从状态
为从状态和动作
开始,经过 t 步后到达状态 s 的概率密度。折扣状态占用度量是这些密度的几何加权平均值:
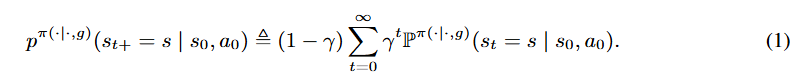
策略的学习是通过最大化在这种折扣状态占用度量下到达期望目标状态的可能性来实现的(Eysenbach 等人,2020;Touati & Ollivier,2021;Rudner 等人,2021,《Outcome-driven reinforcement learning via variational inference》;Eysenbach 等人,2022):
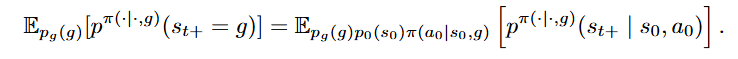
遵循先前的工作(Eysenbach 等人,2022),我们通过对比表征学习(Gutmann & Hyvärinen,2012,《Noise-contrastive estimation of unnormalized statistical models, with applications to natural image statistics》)来估计这个目标;我们将学习一个评论家函数,该函数以状态 - 动作对 (s,a) 和未来状态![]() 作为输入,并输出一个实数
作为输入,并输出一个实数![]() ,用于估计在当前状态和动作下到达未来状态的可能性(比率)。我们将评论家函数参数化为状态 - 动作表征
,用于估计在当前状态和动作下到达未来状态的可能性(比率)。我们将评论家函数参数化为状态 - 动作表征![]() 和未来状态表征
和未来状态表征![]() 之间的内积,即
之间的内积,即![]() ,并将评论家值解释为这些表征之间的相似度。
,并将评论家值解释为这些表征之间的相似度。
对比 RL 通过 NCEBinary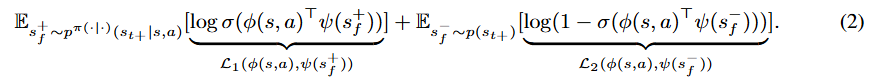
(Gutmann & Hyvärinen,2012;Ma & Collins,2018,《Noise contrastive estimation and negative sampling for conditional models: Consistency and statistical efficiency》;Hjelm 等人,2019,《Learning deep representations by mutual information estimation and maximization》)目标,区分从平均折扣状态占用度量中采样的未来状态 ![]()
和从任意状态 - 动作对中采样的未来状态![]()
这个目标也可以以离策略的方式表述(见 Eysenbach 等人(2020)和附录 B);在我们的实验中,我们将使用这种离策略版本。附录 C 提供了对比 RL 与难负样本挖掘之间联系的一些直观解释。
3.2 稳定对比强化学习的设计决策:
在本节中,我们描述稳定对比 RL 最重要的设计因素:(i)使用合适的编码器架构和批量大小;(ii)通过层归一化和冷启动初始化来稳定和加速训练;(iii)通过数据增强来防止过拟合
D1. Neural network architecture for image inputs.
在视觉和语言领域,增大架构规模使大型神经网络能够在越来越大的数据集上实现更高的性能(Tan & Le, 2019;Brown 等人,2020;Dosovitskiy 等人,2020;Radford 等人,2021;Baker 等人,2022 )。虽然大型视觉模型(例如 ResNets(He 等人,2016)和 Transformers(Vaswani 等人,2017))已被应用于 RL 场景(Espeholt 等人,2018;Shah & Kumar, 2021;Kumar 等人,2022;Chen 等人,2021a;Janner 等人,2021),但浅层卷积神经网络(CNNs)在 RL 中仍然广泛使用(Schrittwieser 等人,2020;Laskin 等人,2020a、b;Badia 等人,2020;Hafner 等人,2020;2019),这表明简单的架构可能就已足够。在我们的实验中,我们将研究架构的两个方面:视觉特征提取器,以及在这些视觉特征之上学习到的对比表征。对于视觉特征提取器,我们将比较简单的 CNN 和更大的 ResNet。对于对比表征,我们将研究缩放这些多层感知器(MLP)的宽度和深度所产生的影响。虽然先前的方法通常将视觉特征提取器与后续的 MLP 分开训练(Radford 等人,2021),但我们的实验也将研究端到端的训练方法。附录 D 包含了我们网络架构的概述。
D2. 批量大小
计算机视觉领域的先前研究(Chen 等人,2020;He 等人,2020;Grill 等人,2020;Chen 等人,2021b)发现,对比表征学习受益于较大的批量大小,这可以稳定并加速学习过程。在对比 RL 的背景下,使用更大的批量不仅会增加正样本的数量(与批量大小成线性关系),还会增加负样本的数量(与批量大小成二次方关系)(Eysenbach 等人,2022)。这意味着,给定一个未来目标![]() ,算法将能够看到更多随机目标
,算法将能够看到更多随机目标。我们将研究由于批量大小增加而增多的正样本和负样本,会如何影响对比 RL。
D3. 层归一化
我们推测,从包含各种操作行为示例的多样化离线数据集中学习,可能会导致数据集中不同子集的特征和梯度有所差异(Yu 等人,2020a)。我们将依据先前 RL 领域的实证研究(Bjorck 等人,2021;Kumar 等人,2022),研究在视觉特征提取器和后续的 MLP 中添加层归一化(Ba 等人,2016)是否能提升性能。我们将对 CNN 和 MLP 的每一层,在非线性激活函数之前应用层归一化进行实验。
D4. 冷启动初始化
先前的研究提出,正样本之间的对齐对于对比表征学习至关重要(Wang & Isola, 2020)。为了在初始训练阶段促进表征的对齐,我们将对最终前馈层的权重进行初始化。具体而言,我们将使用![]() 来初始化
来初始化![]() 最终层的权重,使得在学习的初始阶段,这些表征彼此保持接近。我们将这种 “冷启动初始化” 方法与更标准的初始化策略进行比较。
最终层的权重,使得在学习的初始阶段,这些表征彼此保持接近。我们将这种 “冷启动初始化” 方法与更标准的初始化策略进行比较。
D5. 数据增强
遵循先前的研究(Eysenbach 等人,2022;Fujimoto & Gu, 2021;Baker 等人,2022;Peng 等人,2019;Siegel 等人,2019;Nair 等人,2020;Wang 等人,2020),我们将在行动者目标中加入额外的行为克隆正则化项,对行动者采样分布外的动作进行惩罚。虽然我们的大多数设计决策增加了模型容量,但添加这种行为克隆起到了一种正则化的作用,这在离线 RL 场景中通常很重要,可以避免过拟合(Fujimoto & Gu, 2021)。初步实验发现,这个正则化项本身容易导致过拟合,这促使我们像先前离线 RL 研究(Yarats 等人,2020;Laskin 等人,2020b;Hansen 等人,2021)那样,研究数据增强(随机裁剪)的方法。
4 实验
我们的实验首先研究驱动稳定对比 RL 的设计决策,并使用模拟和真实世界的基准测试,将对比 RL 与其他离线目标条件策略学习方法进行比较,这些方法包括使用条件模仿学习的方法,以及利用辅助目标预训练表征的方法。然后,我们分析稳定对比 RL 学习到的表征的独特属性,为我们方法的良好性能提供实证解释。最后,我们进行各种消融研究,以测试我们算法学习到的策略的泛化性和可扩展性。我们的实验旨在回答以下问题:
- 哪些设计因素的组合,能最有效地驱动对比 RL 解决机器人任务?
- 在模拟和真实世界的基准测试中,稳定对比 RL 与先前的离线目标条件 RL 方法相比表现如何?
- 稳定对比 RL 学习到的表征,是否具有能解释其工作原理的特性?
- 我们方法学习到的策略,是否受益于对比学习的鲁棒性和可扩展性?
4.1 实验设置:在讨论实验之前,我们先介绍一下将使用的实验设置。我们的实验采用了一系列基于先前工作(Fang 等人,2022a、b;Ebert 等人,2021;Mendonca 等人,2021)的模拟和真实世界目标条件控制任务。首先,我们使用(Fang 等人,2022a、b)中提出的五个模拟操作任务的基准测试(图 2),这些任务需要控制模拟机械臂来重新排列各种物体。其次,我们使用(Mendonca 等人,2021)中提出的目标条件运动基准测试。这些任务需要达到期望的姿势,比如控制四足动物用两只脚保持平衡。第三,我们使用 6 自由度的 WidowX 250 机械臂,研究在这些模拟基准测试中的良好性能,是否能转化为在真实世界中的成功。我们在扩展版的 Bridge 数据集(Ebert 等人,2021)上进行训练,该数据集需要控制机械臂完成不同的家务任务。有关任务、数据集的详细信息,以及解决这些任务的挑战,请参见附录 E。
4.2 消融研究:我们的第一个实验研究不同设计决策,对对比 RL 性能的影响,旨在找到一组关键设计因素(如架构、初始化),以有效地提升这种目标条件 RL 算法的性能。我们在 “抽屉” 任务(图 1)和 “推块、打开抽屉” 任务(附录 F.4)上进行消融研究,并报告三个随机种子的平均值和标准差。附录中包含更多实验,强调了大批量(D2,附录 F.13)的重要性,并表明较低维度的表征能实现更高的成功率(附录 F.15)。
- D1. 网络架构:我们研究图像编码器和后续多层感知器(MLP)的架构。对于图像编码器,我们将一个浅层的 3 层卷积神经网络(CNN,类似于 DQN(Mnih 等人,2015))与 ResNet 18(He 等人,2016)进行比较。图 1(左)显示,在纳入除架构外相同的设计决策时,3 层 CNN 编码器的性能比 ResNet 18 编码器高出 2.89 倍(81% 对 28%)。附录 F.1 中的额外实验表明,这一违反直觉的发现,可能是由于过拟合造成的。接下来,我们研究后续 MLP 的架构,用(宽度,深度)表示。我们的实验表明,(1024,4)的 MLP 产生了最佳结果,这表明更宽的 MLP 性能更好。在后续实验中,我们使用 3 层 CNN 作为视觉特征提取器,后面接一个(1024,4)的 MLP。附录 F.2 包含了在 “预训练和微调” 设置下的额外实验,该设置遵循先前的工作(Kumar 等人,2022;Nair 等人,2022),直接将在视觉数据集上预训练的视觉编码器用于 RL 任务。
- D3. 稳定性、D4. 初始化和 D5. 数据增强:我们假设层归一化可以平衡特征幅度并防止梯度干扰,而数据增强可以减轻过拟合。我们在图 1(右)中的实验表明,层归一化和数据增强(通过随机裁剪)对于良好的性能都至关重要。接下来,我们研究权重初始化,采用 3.2 节中概述的 “冷启动初始化” 策略。我们发现,这种使用非常小的初始权重的策略,比的初始化策略性能提升了 2.49 倍(82% 对 33%)。附录图 27 中的额外实验表明,和的结果仅略逊于。在附录 F.14 中,我们展示了较小的学习率和学习率 “热身”,与冷启动初始化有不同(更差)的效果。这些消融实验的结果促使我们在其他实验中应用层归一化、数据增强和冷启动初始化。
- 总结:我们的实验表明,以下设计决策可以稳定对比 RL:(i)使用简单的 3 层 CNN 视觉特征提取器,后面接一个宽的 MLP。(ii)添加层归一化。(iii)用小值初始化 MLP 最后一层的权重。(iv)对状态和目标图像都应用随机裁剪。(v)使用大批量(2048)。我们用稳定对比 RL 来表示这些设计决策的组合,并在附录 E 中提供实现。我们将我们的方法称为 “稳定”,是因为我们发现这些设计决策产生了更稳定的学习曲线(见附录图 13)。在 “推块、打开抽屉” 任务上的额外消融实验(见附录图 14)也得出了类似的结论。
4.3 与先前离线目标条件 RL 方法的比较:接下来,我们研究稳定对比 RL 与先前方法相比的有效性,这些先前方法包括使用目标条件监督学习的方法,以及采用辅助表征学习目标的方法。我们在从模拟和真实世界收集的数据集上进行实验,训练期间不与环境进行任何交互 —— 也就是说,所有实验都集中在离线、目标条件 RL 上。
- 模拟评估 - 操作任务:我们首先与五个基于目标条件行为克隆的基线方法进行比较。最简单的目标条件行为克隆(“GCBC”)(Chen 等人,2021a;Ding 等人,2019;Emmons 等人,2021;Ghosh 等人,2020;Lynch 等人,2020;Paster 等人,2020;Srivastava 等人,2019)训练一个策略,以有条件地模仿到达目标的轨迹。目标条件 IQL(GC-IQL)是 IQL(Kostrikov 等人,2021)的目标条件版本,IQL 是一种最先进的离线 RL 算法。GoFar(Ma 等人,2022a)是 GCBC 的改进版本,它使用学习到的评论家函数对动作的对数似然进行加权。第四个基线方法是 WGCSL(Yang 等人,2022),它通过折扣优势权重对策略回归进行增强。我们还与对比 RL(Eysenbach 等人,2022)进行比较,这有助于我们测试这些设计决策是否提高了性能。与稳定对比 RL 一样,这些基线方法都是直接在目标图像上进行端到端训练,不使用任何显式的特征学习。如图 2 所示,稳定对比 RL 在五个任务中的四个上与基线方法相当或超过它们。在那些更具挑战性的任务(推块、打开抽屉;桌上取放;抽屉取放)上,我们可以看到这些基线方法和稳定对比 RL 之间有明显的差异。然而,基线方法无法解决这些更具挑战性的任务。稳定对比 RL 在其中一个任务(推块、关闭抽屉)上的表现比 GC-IQL 和 GCBC 差,这可能是因为该任务中的方块遮挡了抽屉把手,引入了部分可观测性问题。
- 模拟评估 - 运动任务:我们接下来的一组实验集中在运动任务上。进行这些实验是为了观察相同的设计决策,在操作任务之外的任务上是否有帮助,以及在我们只有次优数据的任务上的效果。我们在先前工作(Mendonca 等人,2021)中的两个目标到达任务(Walker 和 Quadruped)上,将稳定对比 RL 与对比 RL、GCBC 和 GC-IQL 进行比较。我们在离线设置下评估所有方法,记录到达 12 个独特目标姿势的平均成功率。如图 4 所示,稳定对比 RL 在两个运动任务上都超过了所有三个基线方法,比最强的基线方法平均成功率高出 33%。
- 真实世界评估:接下来,我们研究这些方法是否能够有效地解决真实世界中基于图像的目标导向操作任务,并且完全从离线数据中学习。我们将稳定对比 RL 与模拟结果中表现最好的基线方法 GCBC 进行比较。我们也与 GC-IQL 进行比较,因为它在模拟实验中表现良好,并且其简单性在实际应用中具有吸引力。我们在三个目标到达任务上进行评估,并在图 5 中报告成功率。稳定对比 RL 在简单任务(到达茄子)上的表现与基线方法相似,而在两个较难的任务(取放勺子、推罐子)上达到了 60% 的成功率,而所有基线方法在这些任务上都没有进展。我们推测,这种良好的性能可能是由于稳定对比 RL 的难负样本挖掘动态机制,而我们的设计决策解锁了这一机制。在 4.4 节中,我们对稳定对比 RL 和基线方法学习到的表征进行可视化,为我们的方法实现更高成功率提供直观解释。4.5 节和附录 F.7 比较了我们的方法和基线方法在轨迹不同时间步学习到的 Q 值,旨在定量分析我们方法的优势。
4.4 学习到的表征可视化:为了理解为什么稳定对比 RL 在 4.3 节中能实现高成功率,我们研究自监督 RL 获取的表征,是否包含特定任务的信息。为了回答这个问题,我们对稳定对比 RL、VAE 和 GCBC 在 “推块、打开抽屉” 任务上学习到的表征进行可视化。给定一个初始图像(图 6 最左边)和期望的目标图像(图 6 最右边),我们在这两个图像的表征之间进行插值,并在留出的验证集中检索最近邻图像。作为比较,我们还包括在像素空间中的直接插值。不出所料,在像素空间中插值生成的图像不切实际。虽然在 VAE 和 GCBC 的表征空间中进行线性插值,生成的图像真实,但检索到的图像未能捕捉到因果关系,这表明需要添加其他机制,例如重新标记潜在目标(Nair 等人,2018;Pong 等人,2020;Rosete-Beas 等人,2022)和带有值约束的潜在子目标规划(Fang 等人,2022a、b)。当对稳定对比 RL 的表征进行插值时,中间表征对应于策略在从初始观察到最终目标的转换过程中,应该访问的观察序列。这些结果表明,稳定对比 RL 在学习到的表征中捕捉到了因果关系,为其良好性能提供了直观解释。附录 F.5 和 F.6 包含一个定量实验和更多可视化内容。
图6:学习到的表征可视化。(第一行)在像素空间中直接对两张图像进行插值,会生成不真实的图像。(第二行)使用变分自编码器(VAE),我们对最左边和最右边图像的表征进行插值,并可视化从验证集中检索到的最近邻图像。VAE能够捕捉图像的内容,但无法捕捉因果关系——物体在没有被机器人手臂触碰的情况下移动了。(第三行)基于目标条件的行为克隆(GCBC)同样生成了真实的图像,但忽略了时间因果关系。(第四行)稳定对比强化学习(RL)学习到的表征不仅能捕捉图像的内容,还能捕捉因果关系——机器人手臂首先从目标状态中的位置移开,以便将物体移动到合适的位置。
4.5 机械臂匹配问题:先前的研究发现,有些目标比其他目标更容易区分(容易的负样本)(Rosete-Beas 等人,2022;Tian 等人,2020;Alakuijala 等人,2022),而有些目标可能需要长时间的推理才能达到(难负样本)。例如,在 “推块、打开抽屉” 任务上,先前的目标条件算法(Fang 等人,2022a;Kostrikov 等人,2021)只是简单地将机械臂的位置与目标图像中的位置进行匹配,无法将绿色方块移动到目标位置。我们将这种失败称为机械臂匹配问题。稳定对比 RL 使用对比损失(公式 2)学习评论家函数,可能会进行某种难负样本挖掘,正确分配 Q 值,避免机械臂匹配问题。我们在图 7 中通过比较稳定对比 RL 和对比 RL 学习到的 Q 值,来测试这一假设,目的是评估我们的设计决策,是否能导致对 Q 值更准确的估计。先前的研究表明,预训练的 VAE 表征也可能有效,因此我们还与应用于 VAE 特征之上的 GC-IQL 版本进行比较(Fang 等人,2022a、b)。我们通过一次滚动中的最小值和最大值对这些 Q 值进行归一化。图 7 比较了物体不在正确位置,但夹爪在正确位置的观察的 Q 值。GC-IQL 错误地为这个观察分配了高 Q 值。相比之下,稳定对比 RL 为这个观察预测了一个小的值,突出了其 Q 函数的准确性,并展示了它如何避免机械臂匹配行为,实现更高的成功率。附录 F.7 包括在最优轨迹中 Q 值的比较。
4.6 数据集大小对性能的影响:在计算机视觉和自然语言处理中,模型性能随着数据量的增加而提升,这已得到成功证明(Brown 等人,2020;He 等人,2022),这促使我们研究在离线 RL 设置中,对比 RL 是否具有类似的扩展能力。为了回答这个问题,我们进行了数据集大小从 100K 增加到 1M 的实验,将稳定对比 RL 与一个使用预训练特征来改进策略学习的基线方法进行比较。图 8 中的结果表明,稳定对比 RL 有效地利用了额外的数据,随着数据集大小的增加,成功率提高了 3 倍。相比之下,PTP 的性能在 250K 转换左右达到饱和,这表明稳定对比 RL 观察到的大部分性能提升,可能来自更好的表征,而不是更好的反应策略。在附录 F.9 中,我们发现增加数据集大小也提高了二元准确率。
4.7 泛化到未见相机角度和物体颜色:我们接下来的一组实验研究稳定对比 RL 学习到的策略的鲁棒性。我们假设稳定对比 RL 可能在未见任务上有较好的泛化能力,原因有两个:(1)稳定对比 RL 类似于先前工作中用于提高鲁棒性的对比辅助目标(Nair 等人,2022;Laskin 等人,2020b、a);(2)因为稳定对比 RL 仅使用评论家目标学习特征,我们期望这些特征不会保留与任务无关的信息(不像基于自动编码的表征)。我们进行了一个实验,通过改变环境,比较稳定对比 RL 与一个使用通过重建预训练特征的基线方法的泛化能力。我们在图 9 中展示了改变俯仰角的结果,其他结果和完整细节见附录 F.10。这些实验提供了初步证据,表明我们的方法学习到的策略可能具有较好的泛化能力。在附录 F.11 和 F.12 中,我们研究了用辅助目标和子目标规划增强稳定对比 RL 的效果,这些对于先前的工作(Fang 等人,2022a)很重要,但会降低稳定对比 RL 的性能。
5 结论
在本文中,我们研究了能够使自监督 RL 方法解决现实世界中机器人操作任务的设计决策,这些任务曾让先前的方法束手无策。我们发现,关于架构、批量大小、归一化、初始化和增强的决策都非常重要。
局限性:目标条件 RL 背后的主要动机之一,是它可能实现与计算机视觉(Zhai 等人,2022)和 NLP(Kaplan 等人,2020)中自监督方法类似的缩放定律。我们的工作只是开发适用于现实世界机器人数据集的自监督 RL 方法的一小步;与 NLP 和 CV 中的模型大小和数据集规模相比,我们的研究规模还很小。然而,我们的设计决策确实使我们能够在离线环境中显著提高性能(见图 1),并且确实产生了一种方法,其成功率似乎随着数据集大小翻倍而线性增加(附录图 22)。因此,我们乐观地认为,这些设计决策可能为进一步扩展这些方法提供有益的指导。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









