






任意步长动力学模型提升在线和离线强化学习的未来预测能力
ICLR 2025 | ADMPO:跨任意步预测的动力学模型能够有效提升有模型强化学习 - 知乎
1 南京大学计算机软件新技术国家重点实验室,南京,中国
2 南京大学人工智能学院,南京,中国
3 南京算力智库科技有限公司,南京,中国
4 鹏城实验室,深圳,518055,中国
摘要
基于模型的强化学习方法通过在动力学模型中进行策略探索,为提高数据效率提供了一种有前景的途径。然而,由于自举预测(将下一个状态归因于当前状态的预测),在动力学模型中准确预测连续步骤仍然是一个挑战,这会导致模型展开过程中的误差累积。在本文中,我们提出了任意步长动力学模型(ADM),通过将自举预测简化为直接预测来减轻复合误差。ADM 允许使用可变长度的计划作为输入来预测未来状态,而无需频繁进行自举预测。我们设计了两种算法,ADMPO-ON 和 ADMPO-OFF,分别将 ADM 应用于在线和离线基于模型的框架中。在在线设置中,与先前的最先进方法相比,ADMPO-ON 展示出了更高的样本效率 。在离线设置中,ADMPO-OFF 不仅与近期的最先进离线方法相比表现更优,而且仅使用单个 ADM 就能更好地量化模型不确定性。
1 引言
基于模型的强化学习 Model-based Reinforcement Learnin(MBRL)[34《A survey on model-based reinforcement learning》] 在在线 [15《Model-based value estimation for efficient model-free reinforcement learning》、6《Sample-efficient reinforcement learning with stochastic ensemble value expansion》、11《Deep reinforcement learning in a handful of trials using probabilistic dynamics models》、35《Algorithmic framework for model-based deep reinforcement learning with theoretical guarantees》、21《When to trust your model: Model-based policy optimization》、31《Model-based reinforcement learning with multi-step plan value estimation》] 和离线 [51《MOPO: Model-based offline policy optimization》、25《Morel: Model-based offline reinforcement learning》、50《COMBO: Conservative offline model-based policy optimization》、40《RAMBO-RL: Robust adversarial model-based offline reinforcement learning》、44《Model-bellman inconsistency for model-based offline reinforcement learning》、33《Reward-consistent dynamics models are strongly generalizable for offline reinforcement learning》] 设置中都已取得了实证成功。MBRL 的核心在于动力学模型,智能体可以在其中进行广泛的探索和评估,从而减少对真实世界样本的依赖。在基于模型的框架中,在线策略优化可以利用较大的更新数据比(UTD)[8《Randomized ensembled double q-learning: Learning fast without a model》] 来提高样本效率,而离线策略优化则可以使用模型生成的数据(超出数据集范围)来完成。
尽管一些研究致力于提出高保真的动力学模型,如对抗模型 [9《Adversarial counterfactual environment model learning》、5《Adversarial model for offline reinforcement learning》]、因果模型 [53《Offline reinforcement learning with causal structured world models》] 以及大多数 MBRL 算法采用的集成动力学模型 [11《Deep reinforcement learning in a handful of trials using probabilistic dynamics models》、21《When to trust your model: Model-based policy optimization》、51《MOPO: Model-based offline policy optimization》],但通过长期的模型展开生成高质量的虚拟样本仍然具有挑战性。在常见形式的动力学模型中,时间步的状态 - 动作对![]() 被用作输入来预测下一个状态
被用作输入来预测下一个状态。因此,在动力学模型中展开状态时,不可避免地会采用自举预测bootstrapping prediction,即把下一个状态的预测依赖于当前状态的预测结果。由于在虚拟的状态转换过程中误差会逐渐累积,生成状态的偏差误差会随着展开长度的增加而增大。如果在具有较大复合误差的不可靠样本上进行更新,策略将被有偏差的策略梯度误导。
在在线设置中,复合误差 [49《Error bounds of imitating policies and environments for reinforcement learning》] 对策略优化的影响限制了模型的利用,从而阻碍了样本效率的进一步提高。在离线设置中,复合误差影响了基于集成的当前模型不确定性估计的准确性。例如,使用与数据集对应的行为策略在模型中进行长期的展开仍然会导致较大的复合误差,并且不同学习器的累积偏差也不会相似。在这种情况下,集成的差异必然会很大,这与实际轨迹在数据集覆盖区域内的情况不一致。因此,在在线和离线设置中减少复合误差都至关重要。
考虑到执行多步动作序列后的直接状态转换,将自举预测简化为直接预测是处理复合误差问题的一种潜在方法 [2《Towards a simple approach to multi-step model-based reinforcement learning》、3《Combating the compounding-error problem with a multi-step model》、7《Combining model-based and model-free RL via multi-step control variates》、36《Temporal abstraction in reinforcement learning with the successor representation》]。虽然在马尔可夫性质的假设下,状态仅依赖于状态 - 动作
![]() [46《Reinforcement learning: An introduction》],但实际上对的预测可以利用更早的信息。追溯前k步计划,
[46《Reinforcement learning: An introduction》],但实际上对的预测可以利用更早的信息。追溯前k步计划,![]() 和中间的k步动作
和中间的k步动作![]() 足以构成预测
足以构成预测 的依据。
为了处理可变长度的计划,我们引入了一种特殊的任意步长动力学模型(ADM),它允许使用![]() 和对应的
和对应的![]() (其中 k 是指定范围内的任意整数)作为输入来预测
(其中 k 是指定范围内的任意整数)作为输入来预测。当智能体面临轨迹分布中的变化时,来自不同回溯长度的状态预测将表现出明显的差异。这一特性使 ADM 能够自然地估计模型不确定性,而无需使用集成方法。我们用 ADM 替换集成动力学模型,设计了一种独特的带有随机回溯的模型展开方法,该方法可以插入到任何现有的 MBRL 算法框架中。在本文中,我们的主要目的是展示 ADM 生成的增强数据在改善未来预测和测量模型不确定性方面的卓越效果。
总的来说,我们的贡献总结如下:
(1)我们提出了一种广义的动力学模型 ADM,以替代现有在线和离线 MBRL 算法中使用的动力学模型,并展示了其在减少复合误差方面的优越性。
(2)我们提出了一种基于 ADM 的新在线 MBRL 算法 ADMPO-ON,并表明它在样本效率方面优于近期最先进的在线基于模型的算法,同时在 MuJoCo [47《Mujoco: A physics engine for model-based control》] 基准测试中保持有竞争力的性能。
(3)我们提出了一种基于 ADM 的新离线 MBRL 算法 ADMPO-OFF,并表明它可以有效地量化模型不确定性,在 D4RL [16《D4RL: Datasets for deep data-driven reinforcement learning》] 和 NeoRL [39《Neorl: A near real-world benchmark for offline reinforcement learning》] 基准测试中比近期最先进的离线算法表现更优。
2 预备知识
2.1 马尔可夫决策过程和强化学习
我们考虑一个标准的马尔可夫决策过程(MDP),由元组![]() 指定,其中 S 是状态空间,A 是动作空间,
指定,其中 S 是状态空间,A 是动作空间,![]() 是动力学函数,用于计算在给定
是动力学函数,用于计算在给定![]() 的情况下,
的情况下,![]() 的条件分布,
的条件分布,![]() 是初始状态分布,
是初始状态分布,![]() 是折扣因子。我们使用
是折扣因子。我们使用![]() 表示由动力学函数 T 和策略
表示由动力学函数 T 和策略![]() 诱导的状态上的在线策略分布。从多步的角度来看,状态
诱导的状态上的在线策略分布。从多步的角度来看,状态![]() 和奖励
和奖励![]() 的归因可以追溯到前 k 步计划,即
的归因可以追溯到前 k 步计划,即![]() 以及其间的动作序列
以及其间的动作序列![]() 。这种关系可以用k步动力学模型表示为:
。这种关系可以用k步动力学模型表示为:
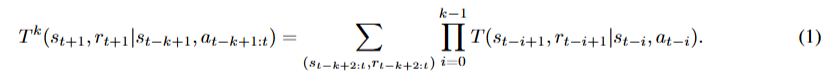 我们使用
我们使用![]() 表示由动力学函数 T 和策略
表示由动力学函数 T 和策略 诱导的,在给定
![]() 的条件下
的条件下![]() 的分布。
的分布。
强化学习(RL)的优化目标是找到一个策略 ,使得期望折扣回报
![]() 最大化。这样的策略可以通过对状态 - 动作值函数
最大化。这样的策略可以通过对状态 - 动作值函数![]() 的估计得到,其中
的估计得到,其中![]() 是状态值函数 [46《Reinforcement learning: An introduction》]。
是状态值函数 [46《Reinforcement learning: An introduction》]。
2.2 基于模型的强化学习
MBRL 旨在找到最优策略,同时将智能体的探索和评估从环境转移到学习到的动力学模型中。给定通过在真实环境中交互收集的数据集![]() ,通常训练动力学模型
,通常训练动力学模型![]() 以最大化期望似然
以最大化期望似然![]() [21《When to trust your model: Model-based policy optimization》]。估计的动力学模型定义了一个代理 MDP
[21《When to trust your model: Model-based policy optimization》]。估计的动力学模型定义了一个代理 MDP![]() 。然后,可以使用任何 RL 算法,结合增强数据集
。然后,可以使用任何 RL 算法,结合增强数据集 ![]() (其中
(其中![]() 是在
是在![]() 中展开得到的合成数据)来恢复最优策略。
中展开得到的合成数据)来恢复最优策略。
上述范式被基于模型的策略优化(MBPO)[21《When to trust your model: Model-based policy optimization》] 及其在在线设置中的许多后续工作 [31《Model-based reinforcement learning with multi-step plan value estimation》、30《Gradient information matters in policy optimization by back-propagating through model》、38《Trust the model when it is confident: Masked model-based actor-critic》、12《Model-augmented actor-critic: Backpropagating through paths》] 所采用。这些工作不需要考虑模型覆盖范围的问题,因为智能体可以在线探索以填补动力学模型不确定的区域。然而,在离线设置中,有限的数据集导致![]() 只能覆盖部分状态 - 动作空间。一旦智能体在
只能覆盖部分状态 - 动作空间。一旦智能体在![]() 中展开时遇到分布外的样本,学习过程可能会崩溃。因此,MOPO [51《MOPO: Model-based offline policy optimization》] 和一些后续的离线 MBRL 算法 [25《Morel: Model-based offline reinforcement learning》、44《Model-bellman inconsistency for model-based offline reinforcement learning》] 在奖励函数中引入了一个惩罚项来衡量模型不确定性,使智能体能够在的安全区域内进行采样。
中展开时遇到分布外的样本,学习过程可能会崩溃。因此,MOPO [51《MOPO: Model-based offline policy optimization》] 和一些后续的离线 MBRL 算法 [25《Morel: Model-based offline reinforcement learning》、44《Model-bellman inconsistency for model-based offline reinforcement learning》] 在奖励函数中引入了一个惩罚项来衡量模型不确定性,使智能体能够在的安全区域内进行采样。
3 方法
在本节中,我们提出了一种特殊的任意步长动力学模型(ADM),以取代主流的集成动力学模型。将 ADM 应用于现有的 MBRL 框架进行策略优化,我们引入了两种算法,即在线的 ADMPO - ON 和离线的 ADMPO - OFF。ADM 通过回溯可变长度的计划将自举预测简化为直接预测,从而改进了未来状态的预测。因此,ADMPO - ON 可以在在线设置中提高样本效率,而 ADMPO - OFF 可以在离线设置中准确估计模型不确定性。
3.1 任意步长动力学模型
目前,流行的动力学模型通常基于单步操作,以![]() 作为输入来预测
作为输入来预测![]() 。在更广泛的背景下,动力学模型也可以是多步的 [2《Towards a simple approach to multi-step model-based reinforcement learning》、3《Combating the compounding-error problem with a multi-step model》、7《Combining model-based and model-free RL via multi-step control variates》],其输入包括
。在更广泛的背景下,动力学模型也可以是多步的 [2《Towards a simple approach to multi-step model-based reinforcement learning》、3《Combating the compounding-error problem with a multi-step model》、7《Combining model-based and model-free RL via multi-step control variates》],其输入包括![]() 以及 k 步动作序列
以及 k 步动作序列![]() ,用于预测
,用于预测 ![]() 和
和 ![]() 。为了在模型的回溯长度上引入灵活性,我们进一步扩展了多步动力学模型的定义,允许 k 为指定范围内的任意正整数,如定义 3.1 所示。
。为了在模型的回溯长度上引入灵活性,我们进一步扩展了多步动力学模型的定义,允许 k 为指定范围内的任意正整数,如定义 3.1 所示。
定义 3.1(任意步长动力学模型):给定最大回溯长度 m,任意步长动力学模型 ![]() 是在给定 k 步计划
是在给定 k 步计划![]() 的条件下,
的条件下,![]() 和
和 ![]() 的分布,其中 k 可以是
的分布,其中 k 可以是![]() 之间的任意整数。
之间的任意整数。
为了处理可变步长的输入,我们使用带有门控循环单元(GRU)[10《Learning phrase representations using RNN encoder-decoder for statistical machine translation》] 的循环神经网络(RNN)[13《Finding structure in time》] 来实现任意步长动力学模型,如图 1 左侧所示。
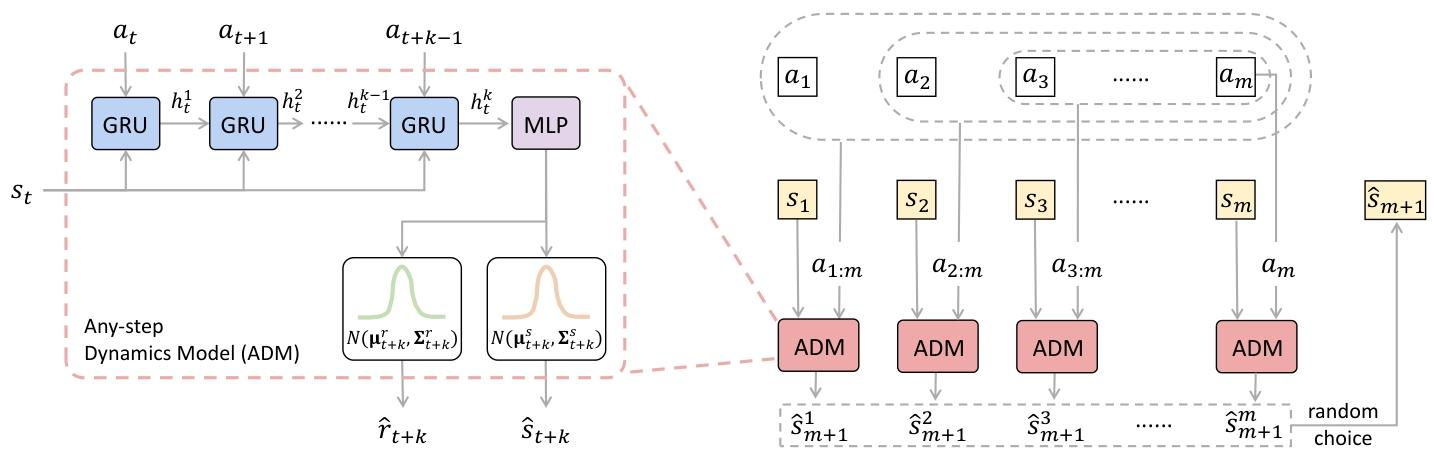
当然,Transformer [48《Attention is all you need》] 也是一种可行的选择,但由于模型结构超出了本研究的范围,我们未予以考虑。由于输入状态仅包含一步,而动作可能是多步的序列,我们复制状态以匹配动作序列的长度,然后依次将其输入到 RNN 中。输入![]() 经过 RNN 表示后,得到隐藏状态
经过 RNN 表示后,得到隐藏状态![]() ,然后将其输入到多层感知器(MLP)中,以获得
,然后将其输入到多层感知器(MLP)中,以获得![]() 和
和![]() 的均值和标准差,即
的均值和标准差,即![]() 和
和![]() 。与先前基于模型的方法 [21《When to trust your model: Model-based policy optimization》、38《Trust the model when it is confident: Masked model-based actor-critic》、31《Model-based reinforcement learning with multi-step plan value estimation》] 类似,我们将
。与先前基于模型的方法 [21《When to trust your model: Model-based policy optimization》、38《Trust the model when it is confident: Masked model-based actor-critic》、31《Model-based reinforcement learning with multi-step plan value estimation》] 类似,我们将![]() 和
和![]() 的分布建模为高斯分布,并通过采样进行预测。我们将任意步长动力学模型称为 ADM,并表示为
的分布建模为高斯分布,并通过采样进行预测。我们将任意步长动力学模型称为 ADM,并表示为![]() ,其中
,其中表示神经网络参数。利用从环境中获得的真实样本,通过最大化以下期望似然来训练
![]() :
:
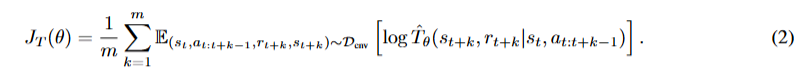
有了![]() ,可以减少模型展开过程中的频繁自举预测。具体来说,给定最大回溯长度 m,从数据缓冲区中采样一个长度为 m 的状态 - 动作序列
,可以减少模型展开过程中的频繁自举预测。具体来说,给定最大回溯长度 m,从数据缓冲区中采样一个长度为 m 的状态 - 动作序列![]() ,在
,在![]() 中开始展开。为了预测
中开始展开。为了预测![]() ,从
,从![]() 中均匀随机选择一个整数作为回溯长度。如果只选择回溯一步,则将
中均匀随机选择一个整数作为回溯长度。如果只选择回溯一步,则将![]() 输入到
输入到![]() 中以获得预测结果;如果选择回溯 m-1 步,则将
中以获得预测结果;如果选择回溯 m-1 步,则将![]() 输入到
输入到![]() 中,依此类推。图 1 右侧展示了基于随机回溯的上述过程。对
中,依此类推。图 1 右侧展示了基于随机回溯的上述过程。对![]() 的进一步预测最多应回溯到
的进一步预测最多应回溯到![]() ,因为
,因为![]() 是使用最大长度为m 步的序列进行训练的。类似地,后续状态预测最多也可以回溯 m 步。回溯状态作为下一个状态预测的一部分归因,在期望上位于前面几步。因此,ADM 减少了展开轨迹的实际自举次数。ADM 中完整的步展开过程如算法 1 所示。
是使用最大长度为m 步的序列进行训练的。类似地,后续状态预测最多也可以回溯 m 步。回溯状态作为下一个状态预测的一部分归因,在期望上位于前面几步。因此,ADM 减少了展开轨迹的实际自举次数。ADM 中完整的步展开过程如算法 1 所示。
算法步骤:
- for τ = 0 to H-1 do: 循环H次,进行展开
- Sample am+τ ~ πφ(·|sm+τ):
- 根据当前状态sm+τ
- 使用策略πφ采样下一个动作am+τ
- Randomly sample an integer k from [1,m] uniformly:
- 随机均匀采样一个整数k
- k的范围是1到m
- Roll out the next step in ADM via (sm+τ+1,rm+τ+1) ~ Tθ(·|sm+τ+1-k,am+τ+1-k:m+τ):
- 使用ADM模型Tθ预测下一个状态sm+τ+1和奖励rm+τ+1
- 基于过去k步的状态和动作序列
- end for: 结束循环
- return (sm,am,rm+1,sm+1,...,sm+H-1,am+H-1,rm+H,sm+H):

与现有的 MBRL 算法类似,ADM 中的策略展开可以生成大量的虚拟样本用于策略更新。我们将基于 ADM 的新 dyna 风格的策略优化框架称为 ADMPO(基于 ADM 的策略优化,ADM-based Policy Optimization)。任何策略优化算法都可以插入到这个框架中。在后续小节中,我们将分别介绍用于在线和离线设置的两种基础算法,ADMPO - ON 和 ADMPO - OFF。
3.2 ADMPO - ON:在线设置中基于 ADM 的策略优化
在在线设置中,智能体与真实环境进行交互,同时优化策略。与 MBPO [21《When to trust your model: Model-based policy optimization》] 类似,ADMPO - ON 可以分为两个交替阶段,即使用不断收集的样本更新动力学模型,以及利用通过模型展开生成的样本额外进行策略优化。ADMPO - ON 用 ADM 替换了 MBPO 框架中的集成动力学模型。它使用公式(2)所示的优化目标训练 ADM,并使用算法 1 中描述的展开方法生成大量虚拟样本。详细的伪代码见附录 C.1。
在展开过程中,ADM 在每一步随机选择一个回溯长度,并将待预测的状态归因于可变长度的计划。当回溯 k 步时,我们将采样过程![]() 视为
视为![]() ,其中
,其中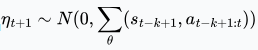 ,
,![]() 是确定性动力学函数,
是确定性动力学函数,![]() 是用于构建零均值噪声分布的标准差函数。在期望上,
是用于构建零均值噪声分布的标准差函数。在期望上,![]() 的目标值估计为:
的目标值估计为:
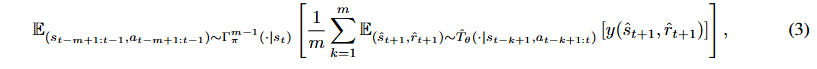
其中![]() 。通过我们的 ADM 展开生成的数据可以视为一种隐式增强。这种增强来自两个方面:(i)在应用学习到的 ADM 预测下一个状态时回溯长度的变化;(ii)在每个回溯长度处由分布
。通过我们的 ADM 展开生成的数据可以视为一种隐式增强。这种增强来自两个方面:(i)在应用学习到的 ADM 预测下一个状态时回溯长度的变化;(ii)在每个回溯长度处由分布![]() 引入的噪声。根据 [52《Is model ensemble necessary? Model-based RL via a single model with lipschitz regularized value function》],状态预测的变化可以有效地隐式正则化 Q 网络在模型预测不确定区域周围的局部利普希茨条件,从而调节值感知模型误差 [14《Value-aware loss function for model-based reinforcement learning》]。
引入的噪声。根据 [52《Is model ensemble necessary? Model-based RL via a single model with lipschitz regularized value function》],状态预测的变化可以有效地隐式正则化 Q 网络在模型预测不确定区域周围的局部利普希茨条件,从而调节值感知模型误差 [14《Value-aware loss function for model-based reinforcement learning》]。
3.3 ADMPO - OFF:离线设置中基于 ADM 的策略优化
在离线设置中,由于数据集对应的行为策略的限制,学习到的 ADM 只能覆盖状态 - 动作空间的部分区域。在这些安全区域之外是风险区域,在该区域模型是不确定的,并且由于智能体无法进行在线探索而无法修复。为了防止策略优化崩溃,需要将学习到的模型的利用集中在安全区域内。同时,应努力在风险区域的边界之外进行探索,以发现比行为策略更有利于获得更好策略的样本。实现保守性和泛化性之间的这种平衡通常需要测量模型不确定性。基于 ADM,接下来我们将介绍一种新的不确定性量化方法。
在我们的 ADM 中,使用不同回溯长度预测的状态会表现出差异。直观地说,这些差异与数据分布密切相关。当智能体处于安全区域时,差异较小。随着智能体逐渐向风险区域探索,差异趋于增大。使用不同回溯 k 获得的概率预测 ![]() 之间的差异自然地衡量了模型不确定性,这可以使用方差(或标准差)来量化,如定义 3.2 所示。
之间的差异自然地衡量了模型不确定性,这可以使用方差(或标准差)来量化,如定义 3.2 所示。
定义 3.2(ADM 不确定性量化器):对于任何最大回溯长度 m 和相应学习到的 ADM ![]() ,
,![]() 在
在![]() 处的不确定性量化为:
处的不确定性量化为:
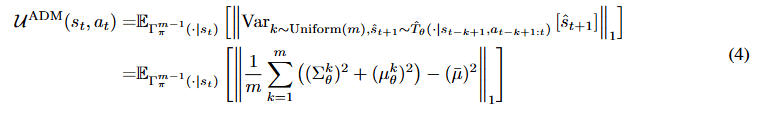
对于任何![]() ,其中为了方便起见
,其中为了方便起见![]() ,
,![]() ,并且
,并且![]() 。
。
这个不确定性项对应于认知和随机模型 epistemic and aleatoric mode 不确定性的组合,其形式与集成标准差类似 [32《Revisiting design choices in offline model based reinforcement learning》、29《Simple and scalable predictive uncertainty estimation using deep ensembles》]。然而,多样性的来源已从集成转移到可变回溯长度。由于通过认知或随机不确定性来估计近似误差已在许多工作中得到应用 [51《MOPO: Model-based offline policy optimization》、4《Pessimistic bootstrapping for uncertainty-driven offline reinforcement learning》、44《Model-bellman inconsistency for model-based offline reinforcement learning》、32《Revisiting design choices in offline model based reinforcement learning》],我们假设我们的 ADM 不确定性(公式 4)是一个可接受的误差估计器 [51《MOPO: Model-based offline policy optimization》],如假设 3.3 所述。
假设 3.3(可接受误差估计器):假设存在一个正实数![]() ,使得对于任何最大回溯长度 m 以及任何
,使得对于任何最大回溯长度 m 以及任何![]() ,以下不等式(5)成立:
,以下不等式(5)成立:
![]()
其中,![]() 是由下式得到的总体条件分布:
是由下式得到的总体条件分布:
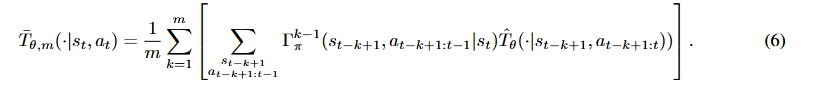
在假设 3.3 以及 PEVI(悲观值迭代,Pessimistic Value Iteration)[23《Is pessimism provably efficient for offline RL?》] 提出的- 不确定性量化器定义(详见附录 A)下,我们给出以下定理,证明
![]() 可以作为一个
可以作为一个- 不确定性量化器来界定贝尔曼误差。
定理 3.4:![]() 是一个有效的
是一个有效的 - 不确定性量化器,其中
![]() 。具体来说:
。具体来说:
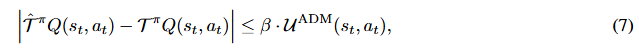
其中,![]() 是由 ADM 诱导的代理贝尔曼算子,用于估计真实的贝尔曼算子
是由 ADM 诱导的代理贝尔曼算子,用于估计真实的贝尔曼算子![]() 。
。
证明:见附录 B。
根据 PEVI [23《Is pessimism provably efficient for offline RL?》] 提出的次优性定理(详见附录 A),通过悲观值迭代得到的策略![]() (在值迭代过程中,将任何
(在值迭代过程中,将任何- 不确定性量化器作为惩罚项纳入其中 [46《Reinforcement learning: An introduction》])与最优策略
![]() 之间的最优性差距是有界的。该最优性差距主要由贝尔曼误差和不确定性量化决定。直观地说,在动力学模型已使用丰富数据进行训练的安全区域中,贝尔曼误差通常较小,并且在不同回溯长度下往往具有较高的一致性;而在数据稀缺的风险区域中,往往会出现较大的误差,并且不同回溯长度的预测结果也会变得不一致。惩罚项可以防止策略采取导致其进入风险区域的行动,否则模型会对这些行动产生不准确的值估计。因此,我们可以通过以下方式对贝尔曼算子进行惩罚,以获得悲观的值估计:
之间的最优性差距是有界的。该最优性差距主要由贝尔曼误差和不确定性量化决定。直观地说,在动力学模型已使用丰富数据进行训练的安全区域中,贝尔曼误差通常较小,并且在不同回溯长度下往往具有较高的一致性;而在数据稀缺的风险区域中,往往会出现较大的误差,并且不同回溯长度的预测结果也会变得不一致。惩罚项可以防止策略采取导致其进入风险区域的行动,否则模型会对这些行动产生不准确的值估计。因此,我们可以通过以下方式对贝尔曼算子进行惩罚,以获得悲观的值估计:
![]()
我们希望惩罚项![]() 尽可能小,从而限制最优性差距。虽然我们的假设 3.3 缺乏理论保证,并且定理 3.4 中边界的紧性也不明确,但我们在 4.3.3 节中提供了充分的证据,表明我们的不确定性量化有效地估计了模型误差。总体而言,ADMPO - OFF 是 ADMPO - ON 的离线版本,它在 ADMPO - ON 的策略优化过程中引入了惩罚贝尔曼算子(公式 8),遵循 MOPO [51《MOPO: Model-based offline policy optimization》] 的算法框架。详细的伪代码见附录 C.2。
尽可能小,从而限制最优性差距。虽然我们的假设 3.3 缺乏理论保证,并且定理 3.4 中边界的紧性也不明确,但我们在 4.3.3 节中提供了充分的证据,表明我们的不确定性量化有效地估计了模型误差。总体而言,ADMPO - OFF 是 ADMPO - ON 的离线版本,它在 ADMPO - ON 的策略优化过程中引入了惩罚贝尔曼算子(公式 8),遵循 MOPO [51《MOPO: Model-based offline policy optimization》] 的算法框架。详细的伪代码见附录 C.2。
4 实验
在本节中,我们进行了多项实验来回答以下问题:
(1)ADM 生成的样本是否比集成动力学模型的复合误差更小?
(2)ADMPO - ON 在在线设置中的表现如何?
(3)ADMPO - OFF 在离线设置中的表现如何?ADM 是否比集成动力学模型能更好地量化模型不确定性?
4.1 动力学模型评估
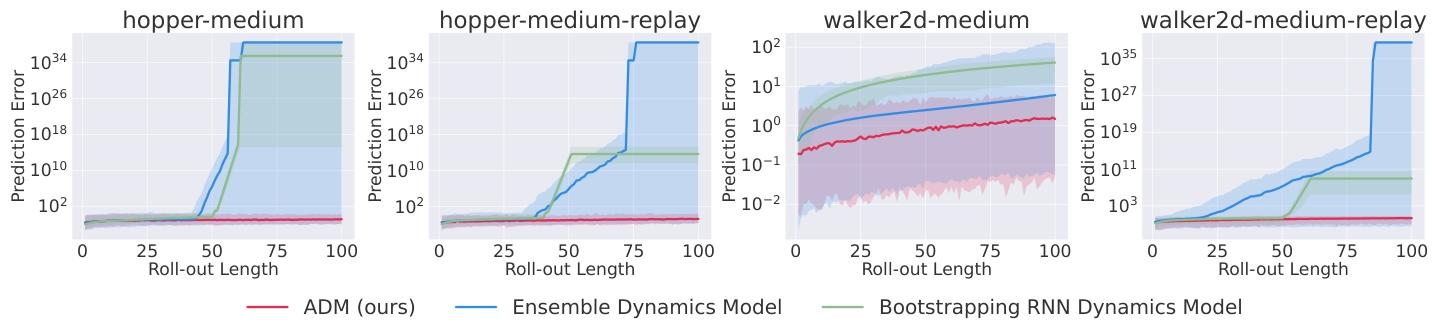
评估动力学模型质量的一个重要指标是复合误差,它会随着模型展开长度的增加而增大。我们选择了四个 D4RL [16《D4RL: Datasets for deep data-driven reinforcement learning》] 数据集,即 hopper - medium - v2、hopper - medium - replay - v2、walker2d - medium - v2 和 walker2d - medium - replay - v2,来比较 ADM 与常用的集成动力学模型之间的复合误差。为了消除 RNN 结构的影响,我们还比较了自举 RNN 动力学模型,该模型与 ADM 具有相同的结构,但使用历史状态 - 动作序列作为输入来预测 。图 2 展示了随着展开长度增加,复合误差的增长曲线。我们观察到,ADM 的曲线始终接近零,而其他两个模型在展开长度超过一定阈值后呈现指数增长。这一现象表明,由于 ADM 在模型展开过程中的任意步回溯机制,它能够改进对未来状态的预测。
4.2 在线设置评估
我们在四个具有挑战性的 MuJoCo 连续控制任务 [47《Mujoco: A physics engine for model-based control》](包括 Hopper、Walker2d、Ant 和 Humanoid)上评估 ADMPO - ON。所有任务均采用 v3 版本并遵循默认设置。我们选择了四种基于模型的方法和一种无模型方法作为基线。这些方法包括 SAC [20《Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor》](最先进的无模型强化学习算法)、STEVE [6《Sample-efficient reinforcement learning with stochastic ensemble value expansion》](将集成方法纳入基于模型的值扩展中)、MBPO [21《When to trust your model: Model-based policy optimization》](使用真实环境样本和分支展开数据的混合来更新策略)、BMPO [28《Bidirectional model-based policy optimization》](基于 MBPO 构建,并将动力学模型替换为双向模型)以及 DDPPO [30《Gradient information matters in policy optimization by back-propagating through model》](采用基于双模型的学习方法来控制预测误差和梯度误差)。
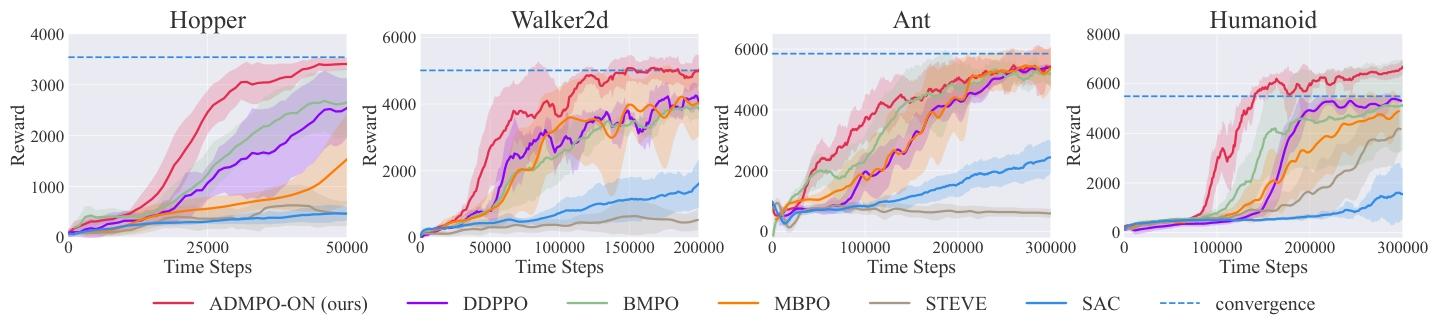
图 3 展示了 ADMPO - ON 和其他五个基线的学习曲线,以及 SAC 的渐近性能。ADMPO - ON 在比基线方法更少的环境步骤下就取得了有竞争力的性能。以最具挑战性的 Humanoid 任务为例,ADMPO - ON 在 150k 步后就达到了 SAC 收敛性能(约 6000)的 100%,而 DDPPO 需要约 200k 步,其他四种方法在 300k 步时甚至都无法接近蓝色虚线(SAC 的渐近性能)。在 Humanoid 任务上,ADMPO - ON 的学习效率比 DDPPO 快约 1.33 倍,并且在学习效率上优于其他基线方法。经过训练后,ADMPO - ON 在所有这四个 MuJoCo 任务上都能达到接近 SAC 渐近性能的最终性能。这些结果表明,ADMPO - ON 既具有高样本效率,又具有有竞争力的性能。关于 ADMPO - ON 在在线设置中表现良好的原因的进一步研究,可在附录 E.1 中找到。
4.3 离线设置评估
4.3.1 D4RL 基准测试结果
我们将 ADMPO - OFF 与四种无模型方法进行比较:BC(行为克隆,Behavioral Cloning),它简单地模仿数据集中的行为策略;CQL [27《Conservative Q-learning for offline reinforcement learning》],它对分布外的状态 - 动作对的 Q 值进行同等惩罚;TD3 + BC [17《A minimalist approach to offline reinforcement learning》],它只是在 TD3 [19《Addressing function approximation error in actor-critic methods》] 的策略优化目标中加入了一个 BC 项;EDAC [1《Uncertainty-based offline reinforcement learning with diversified q-ensemble》],它通过集成方法量化 Q 值的不确定性;以及五种基于模型的方法:MOPO [51《MOPO: Model-based offline policy optimization》],它将模型预测的不确定性作为惩罚项添加到奖励函数中;COMBO [50《COMBO: Conservative offline model-based policy optimization》],它将 CQL 的惩罚函数引入基于模型的框架中;RAMBO [40《RAMBO-RL: Robust adversarial model-based offline reinforcement learning》],它通过对抗训练动力学模型和策略来实现保守性;CBOP [22《Conservative bayesian model-based value expansion for offline policy optimization》],它在 MVE [15《Model-based value estimation for efficient model-free reinforcement learning》] 技术中引入了短视展开的自适应加权,并采用集成动力学模型下的值的方差来保守地估计 Q 值;MOBILE [44《Model-bellman inconsistency for model-based offline reinforcement learning》],它提出了模型 - 贝尔曼不一致性来估计贝尔曼误差。
表 1 报告了在十二个 D4RL [16《D4RL: Datasets for deep data-driven reinforcement learning》] MuJoCo 数据集(v2 版本)上的结果。每个数据集的归一化分数是在离线学习后通过在线评估获得的。报告性能的来源见附录 D.4。我们观察到,ADMPO - OFF 在大多数任务中优于其他九个基线方法,并获得了最高的平均分数。
4.3.2 NeoRL 基准测试结果
NeoRL [39《Neorl: A near real-world benchmark for offline reinforcement learning》] 是一个离线强化学习基准,它以一种更保守、更接近现实世界数据收集场景的方式收集数据。我们关注在 Hopper - v3、HalfCheetah - v3 和 Walker2d - v3 这三个环境中,使用三种不同质量(低、中、高)的策略收集的九个数据集。在我们的评估中,每个数据集包含 1000 条轨迹。
我们将我们的 ADMPO - OFF 与六个基线方法进行比较,包括 BC、CQL、TD3 + BC、EDAC、MOPO 和 MOBILE。表 2 展示了这些方法的归一化分数。由于 NeoRL 数据的覆盖范围狭窄且有限,所有基线方法的性能都有所下降。相比之下,我们的 ADMPO - OFF 保持了相对较高的平均分数,在大多数任务中仍然表现出色。这种显著的优势表明我们的算法在更具挑战性的现实世界任务中的潜力。
4.3.3 不确定性量化
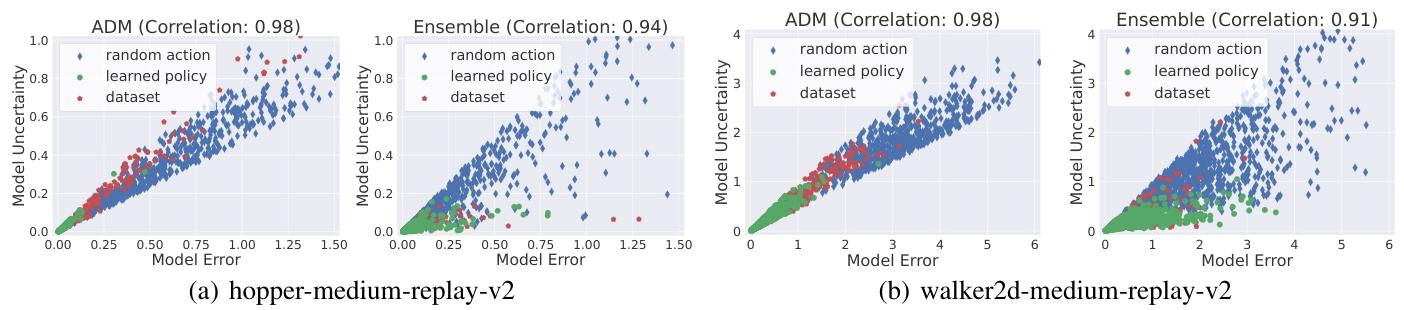
在我们的分析中,我们分别在学习到的 ADM 和集成动力学模型中采样了大量的状态 - 动作对。这些样本是通过使用三种策略进行模型展开获得的:随机选择动作、离线训练后学习到的策略以及数据集中的行为策略。随后,我们测量它们的模型不确定性和模型误差。在两个 D4RL 任务 hopper - medium - replay - v2 和 walker2d - medium - replay - v2 上得到的散点图如图 4 所示。我们观察到,我们的 ADM 能够更好地量化模型不确定性。一方面,在 ADM 中采样得到的模型误差较大的点,往往表现出更大的量化模型不确定性。在这两个任务中观察到的相关系数为 0.98,超过了集成动力学模型的相关系数。另一方面,ADM 比集成模型能更好地区分来自不同策略的样本。由随机动作生成的样本偏离了数据集分布,其不确定性在预期中应该是最大的。相反,当学习到的策略在数据集覆盖的安全区域内进行优化时,模型不确定性在预期中应该是最小的。ADM 的实验图更清晰地展示了这一现象。
5 相关工作
这项工作与在线和离线 dyna 风格的 MBRL [45《Integrated architectures for learning, planning, and reacting based on approximating dynamic programming》] 相关。
5.1 在线基于模型的强化学习
在在线设置中,MBRL 算法旨在利用模型展开数据加速值估计或策略优化。MVE [15《Model-based value estimation for efficient model-free reinforcement learning》] 通过使用动力学模型进行固定深度的短期想象来增强 Q 值目标估计。STEVE [6《Sample-efficient reinforcement learning with stochastic ensemble value expansion》] 在 MVE 的基础上,将集成方法纳入值扩展中,以更好地估计 Q 值。SLBO [35《Algorithmic framework for model-based deep reinforcement learning with theoretical guarantees》] 直接使用 TRPO [41《Trust region policy optimization》],利用在动力学模型中展开到轨迹末端生成的合成数据来优化策略。MBPO [21《When to trust your model: Model-based policy optimization》] 提出了一种分支展开方案来截断不可靠的样本,从而减少复合误差 [49《Error bounds of imitating policies and environments for reinforcement learning》] 的影响,并采用 SAC [20《Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor》],使用真实世界数据和模型生成数据的混合来更新策略。
近期的工作主要从两个角度提高 MBRL 的性能。一个角度是专注于学习更好的动力学模型,如双向模型 [28《Bidirectional model-based policy optimization》]、对抗模型 [9《Adversarial counterfactual environment model learning》、5《Adversarial model for offline reinforcement learning》]、因果模型 [53《Offline reinforcement learning with causal structured world models》] 以及多步模型 [2《Towards a simple approach to multi-step model-based reinforcement learning》、3《Combating the compounding-error problem with a multi-step model》、7《Combining model-based and model-free RL via multi-step control variates》]。另一个角度是追求更好地利用学习到的模型,提高模型生成样本的可靠性 [38《Trust the model when it is confident: Masked model-based actor-critic》],或者应用基于模型的多步规划技术 [11《Deep reinforcement learning in a handful of trials using probabilistic dynamics models》、12《Model-augmented actor-critic: Backpropagating through paths》、24《Differentiable algorithm networks for composable robot learning》、37《Path integral networks: End-to-end differentiable optimal control》、42《Universal planning networks: Learning generalizable representations for visuomotor control》、31《Model-based reinforcement learning with multi-step plan value estimation》]。
5.2 离线基于模型的强化学习
尽管一些无模型强化学习算法 [26《Stabilizing off-policy Q-learning via bootstrapping error reduction》、18《Off-policy deep reinforcement learning without exploration》、17《A minimalist approach to offline reinforcement learning》、27《Conservative Q-learning for offline reinforcement learning》、1《Uncertainty-based offline reinforcement learning with diversified q-ensemble》、4《Pessimistic bootstrapping for uncertainty-driven offline reinforcement learning》] 对离线强化学习研究做出了重要贡献,但 MBRL 算法在离线设置中似乎更具前景,因为它们可以利用动力学模型扩展数据集,在很大程度上提高数据效率。
离线 MBRL 的核心问题在于如何有效地利用模型。MOPO [51《MOPO: Model-based offline policy optimization》] 和 MOReL [25《Morel: Model-based offline reinforcement learning》] 在原始奖励函数中添加模型预测的不确定性作为惩罚项,以实现悲观的值估计。MOBILE [44《Model-bellman inconsistency for model-based offline reinforcement learning》] 通过在离线基于模型的框架中引入模型 - 贝尔曼不一致性来改进不确定性量化。COMBO [50《COMBO: Conservative offline model-based policy optimization》] 应用 CQL [27《Conservative Q-learning for offline reinforcement learning》],强制使模型生成的分布外样本的 Q 值较小。RAMBO [40《RAMBO-RL: Robust adversarial model-based offline reinforcement learning》] 通过对抗模型学习实现保守性,在最小化值的同时保持对转移函数的拟合。CBOP [22《Conservative bayesian model-based value expansion for offline policy optimization》] 在 MVE [15《Model-based value estimation for efficient model-free reinforcement learning》] 技术中引入短视展开的自适应加权,并采用集成动力学模型下的值的方差来保守地估计 Q 值。MOREC [33《Reward-consistent dynamics models are strongly generalizable for offline reinforcement learning》] 使用对抗判别器设计了一种奖励一致的动力学模型,以使模型生成的样本更可靠。
6 结论
在这项工作中,我们提出了一种新的环境模型学习和利用方法,即任意步长动力学模型(ADM)。ADM 适用于在线和离线 MBRL 框架,并分别产生了两种算法 ADMPO - ON 和 ADMPO - OFF。多项分析和实验表明,ADM 在性能上优于先前 MBRL 方法中广泛应用的集成动力学模型。唯一的问题是 RNN 在训练过程中可能会消耗更多资源。我们相信 ADM 具有超出本文所展示能力的强大潜力。未来,我们将探索 ADM 在非马尔可夫视觉强化学习场景中的可扩展性,同时考虑在线和离线设置
**输入参数:**
- `Tθ`: 初始ADM模型
- `πφ`: 初始策略
- `H`: 展开长度
- `m`: 最大回溯长度
- `Denv`: 真实环境数据缓冲区
- `Dmodel`: 模型生成数据缓冲区
- `U`: wADM更新的步数
- `N`: 交互轮数
- `E`: 每轮的步数**算法主要步骤:**
1. **环境探索**
```
探索U步环境步骤,将数据添加到Denv
```2. **主循环(N轮)**
- 每轮开始时训练ADM模型:
```
使用Denv中的数据训练Tθ,通过最大化方程(2)
```
- 每轮包含E步:
1. **环境交互**
```
- 根据当前状态st使用策略πφ采样动作at
- 在真实环境中执行at
- 将(st,at,rt+1,st+1)添加到Denv
```2. **模型展开(M次)**
```
- 从Denv采样m步状态-动作序列
- 使用ADM-Roll算法展开H步
- 将展开数据添加到Dmodel
```3. **策略更新(G次)**
```
使用Denv和Dmodel中的样本更新策略πφ
```
**输入参数:**
- `Denv`: 预先收集的数据集
- `Tθ`: 初始ADM模型
- `πφ`: 初始策略
- `H`: 展开长度
- `m`: 最大回溯长度
- `Dmodel`: 模型生成数据缓冲区
- `N`: 迭代次数
- `β`: 惩罚系数**算法主要步骤:**
1. **ADM训练**
```
使用预先收集的数据集Denv训练ADM模型Tθ,通过最大化方程(2)
```2. **主循环(N次迭代)**
每次迭代包含两个主要部分:A. **模型展开(M次)**
```
- 从Denv采样m步状态-动作序列(si:i+m-1, ai:i+m-2)
- 使用ADM-Roll算法展开H步
- 对每个展开步骤应用奖励惩罚: r̃ = r - βUADM(s,a)
- 将惩罚后的展开数据添加到Dmodel
```B. **策略更新(G次)**
```
使用Denv和Dmodel中的样本更新策略πφ
```




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









