







腾讯云DeepSeek API对接微信小程序完全指南

1. 开发环境准备
在开始开发微信小程序与腾讯云DeepSeek API的对接之前,我们需要做好必要的环境准备工作。本章将指导你完成开发环境的搭建,包括安装最新版本的微信开发者工具(IDE),配置小程序的基本信息,如果你习惯于wxml语法的开发,本教程中也会有关于腾讯云AI代码助手插件的安装,需要注意的是本教程对于腾讯云AI代码助手插件 仅停留在安装的的这一步骤,因为我还是习惯于uniapp 的使用。 让我们按照以下步骤,一步步完成开发环境的准备工作。
系统架构

1.1 微信开发者工具安装
注意:第一次使用微信开发者工具时,第一步并不是下载微信开发者工具哦! 而是前往小程序后台, 进行注册并完成小程序开发者认证,这一内容本篇不会详细讲解。
关于:微信开发者工具, 我们需要点链接选择符合自己电脑版本的ide 进行下载
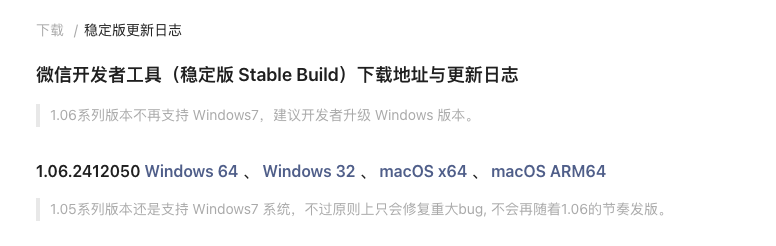
下载完成之后按照提示进行安装即可
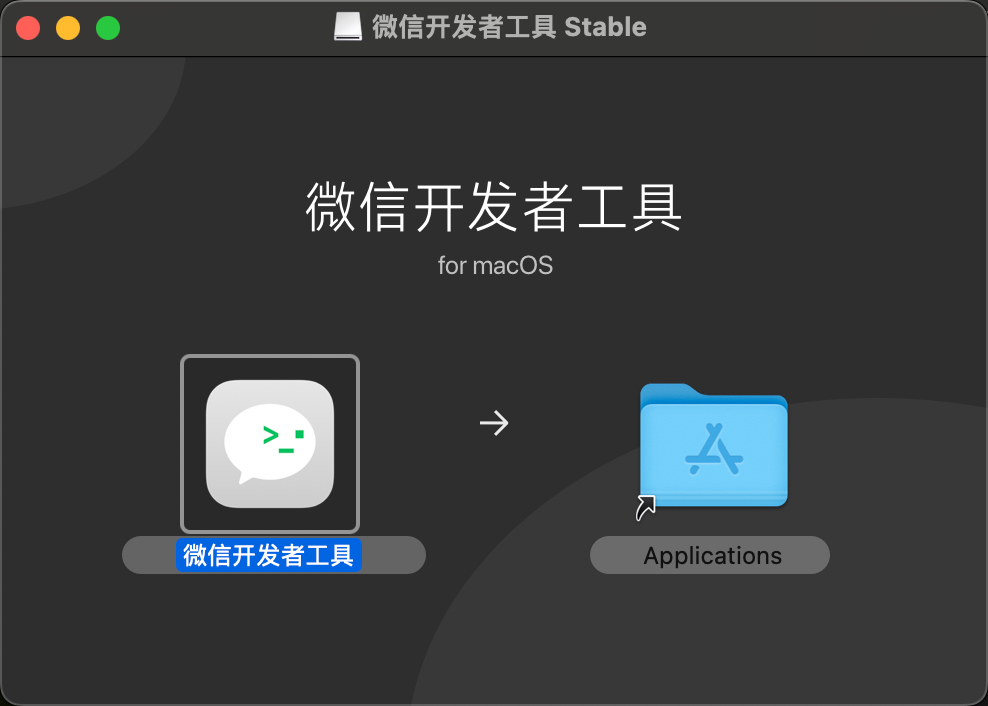
当开发工具安装完成之后, 我们首先创建一个空的项目模板 如下图所示
1.2 腾讯云AI代码助手配置
腾讯云AI代码助手现已完全集成到微信开发者工具中,配置过程变得更加简便。具体步骤如下:
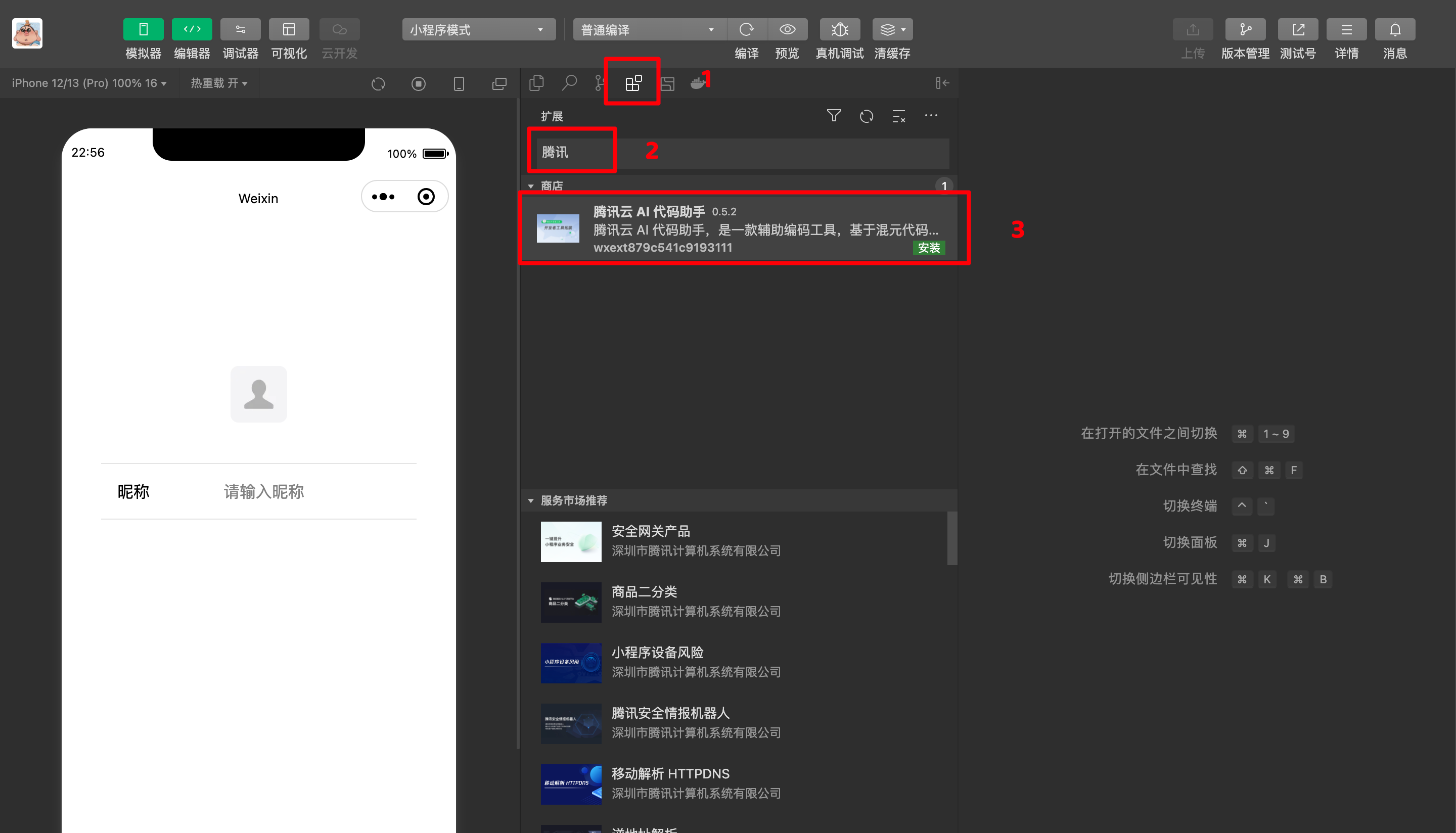
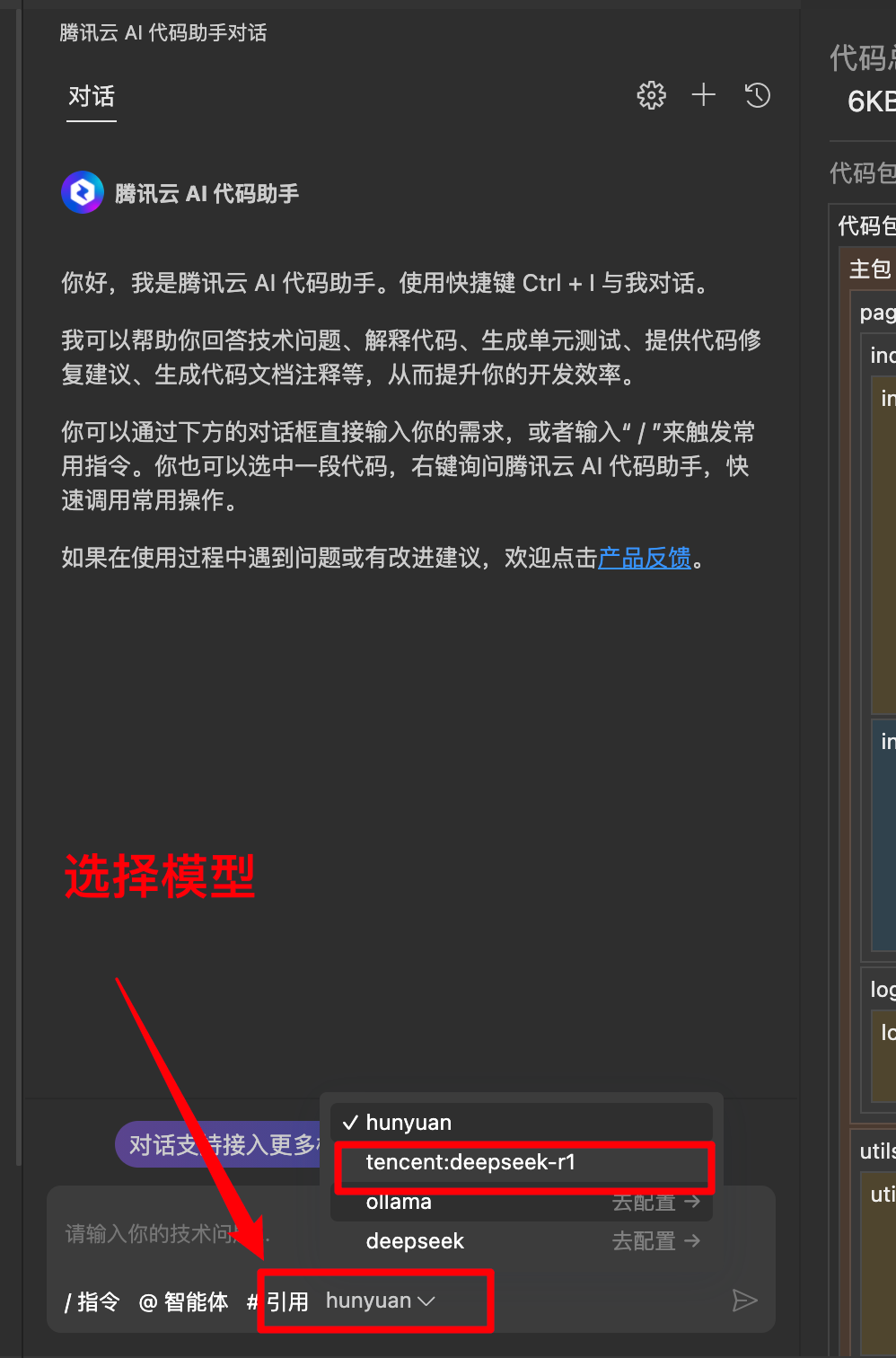
如上图所示三步帮你安装腾讯云AI 代码助手
- 点击图中所示的
1(扩展)。 - 在
2(输入框)中输入腾讯云即可 - 点击
3(安装) ,等待安装完成之后我们就可以体验啦
如下所示,腾讯AI代码助手目前已整合了tencent-deepseek R1模型。 开发者可以尽情的体验tencent-deepseek R1模型带来的便捷开发体验了喽~~
1.3 文案生成流程

2. 小程序界面设计
温馨提示:由于本人习惯于uniapp 项目的开发 因此本项目使用的是uniapp 来打包运行我们的小程序项目
UI界面如下图所示:
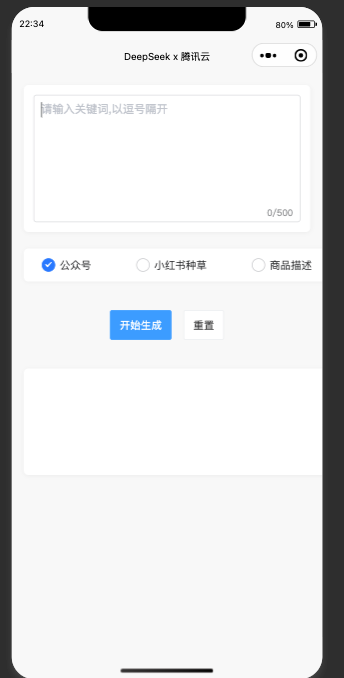
2.1 搭建基础UI界面
我们的UI界面设计简洁,主要包含以下四个核心组件:
- 关键词输入区:用户通过输入关键词,来觉得接下来文案的主要风格。
- 类型选择区: 用户通过选择
公众号,小红书等类型,来觉得文案生成的类型。 - 结果展示区:用于展示腾讯云DeepSeek API 返回的结果。
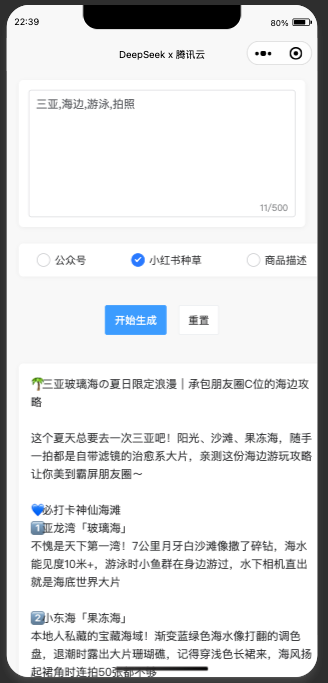
运行效果图如下
3. 腾讯云DeepSeek API集成
下面是腾讯云DeepSeek API 最新计费标准, 注意自己的token使用哦!
📢 腾讯云DeepSeek API 最新计费标准
🕒 生效时间:2025年2月26日 0时起
DeepSeek 模型价格表
模型类型 输入价格 输出价格 DeepSeek-R1 0.004元/千token 0.016元/千token DeepSeek-V3 0.002元/千token 0.008元/千token 📚 详细文档:腾讯云DeepSeek API调用指南
3.1 API接入配置
关于 DeepSeek API 接口 的相关文档可以点击链接进行查看, 接下来我们将逐步实现如和配置 腾讯云DeepSeek 为我们接下来的开发作准备
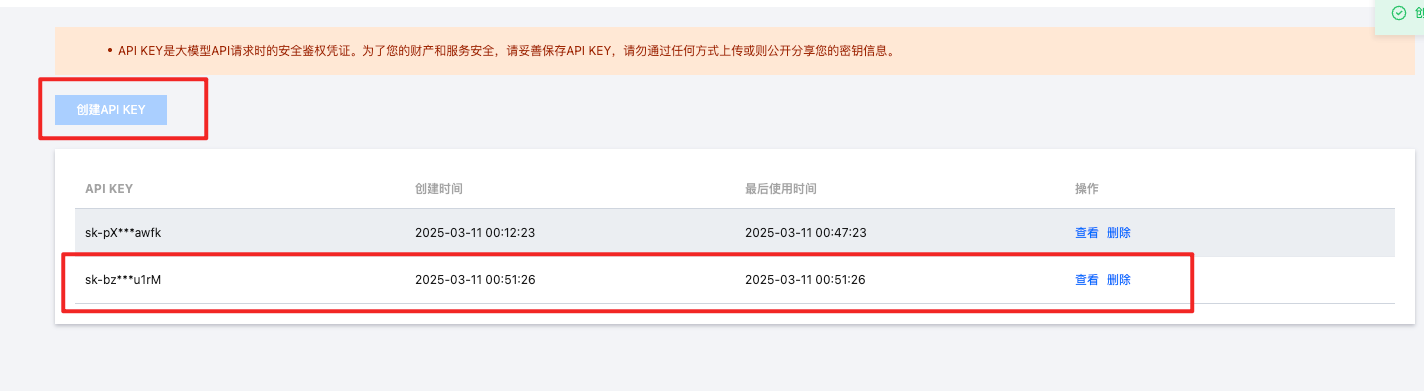
创建API KEY
API 使用前提是需要用于一个API KEY ,访问地址:https://console.cloud.tencent.com/lkeap/api 来创建我们的API KEY 如下图所示, 点击按钮 创建API KEY 即可, 点击查看时可以看到已经创建的 API KEY
编写py代码 进行本地请求
我这里用的是Flask 框架,为我们小程序调用DeepSeek API提供接口服务,代码如下:
import os
import logging
from flask import Flask, request, jsonify
from flask_cors import CORS
from openai import OpenAI
from typing import Dict, Any
# 初始化Flask应用
app = Flask(__name__)
CORS(app) # 启用跨域支持
# 配置日志记录
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# 环境变量配置
OPENAI_CONFIG = {
"api_key": os.getenv("OPENAI_API_KEY", "sk-pXLyNnk8bdl8zkmFkBIi7KBRiaLTATlmGsr8QfTwek7Zawfk"),
"base_url": os.getenv("OPENAI_BASE_URL", "https://api.lkeap.cloud.tencent.com/v1")
}
# 初始化OpenAI客户端
client = OpenAI(**OPENAI_CONFIG)
def validate_request(data: Dict[str, Any]) -> tuple:
"""请求参数验证"""
if not data.get('content'):
logger.warning("Missing content parameter")
return False, "Content parameter is required"
if len(data['content']) > 1000:
logger.warning("Content length exceeds limit")
return False, "Content exceeds maximum length of 1000 characters"
return True, ""
def process_stream_response(stream) -> dict:
"""处理流式响应数据"""
result = {"reasoning_content": "", "answer_content": ""}
for chunk in stream:
if not chunk.choices:
continue
delta = chunk.choices[0].delta
# 使用getattr安全获取属性
if reasoning := getattr(delta, 'reasoningcontent', None):
result["reasoning_content"] += reasoning
if content := getattr(delta, 'content', None):
result["answer_content"] += content
return result
@app.route('/deepseekapi', methods=['POST'])
def generate_content():
"""
处理生成请求
---
parameters:
- name: body
in: body
required: true
schema:
type: object
properties:
content:
type: string
responses:
200:
description: 生成结果
400:
description: 无效请求
500:
description: 服务器错误
"""
# 请求验证
data = request.get_json()
print(data)
is_valid, message = validate_request(data)
if not is_valid:
return jsonify({"error": message}), 400
try:
# 创建流式请求
stream = client.chat.completions.create(
model="deepseek-r1",
messages=[{"role": "user", "content": data['content']}],
stream=True,
temperature=0.7, # 添加生成参数
max_tokens=1000
)
# 处理流式响应
processed_data = process_stream_response(stream)
# 结果后处理
processed_data["answer_content"] = processed_data["answer_content"].strip()
return jsonify(processed_data)
except Exception as e:
logger.error(f"API请求失败: {str(e)}", exc_info=True)
return jsonify({"error": "服务暂时不可用,请稍后再试"}), 500
if __name__ == "__main__":
app.run(
host=os.getenv("FLASK_HOST", "0.0.0.0"),
port=int(os.getenv("FLASK_PORT", 5001)),
debug=os.getenv("FLASK_DEBUG", "false").lower() == "true"
)
验证
我们的Flask 框架暴露出来的请求信息如下:
curl --location --request POST 'http://192.168.31.134:5001/deepseekapi' \
--header 'User-Agent: Apifox/1.0.0 (https://apifox.com)' \
--header 'Content-Type: application/json' \
--header 'Accept: */*' \
--header 'Host: 192.168.31.134:5001' \
--header 'Connection: keep-alive' \
--data-raw '{
content: "请根据以下内容生成500字小红书种草文案:↵关键词:三亚,海边,游泳,拍照↵"
}'
我么通过postman 来测试其连通性,如下图所示
运行服务
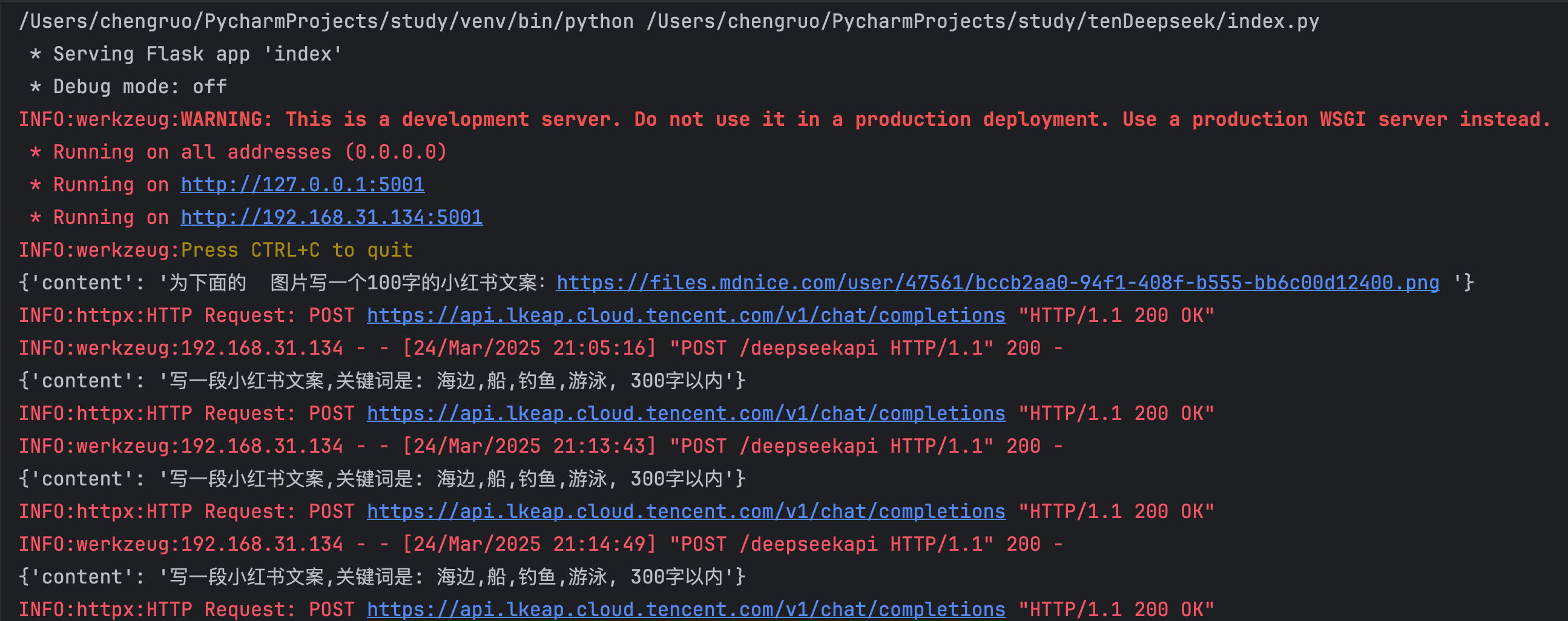
postman 数据返回
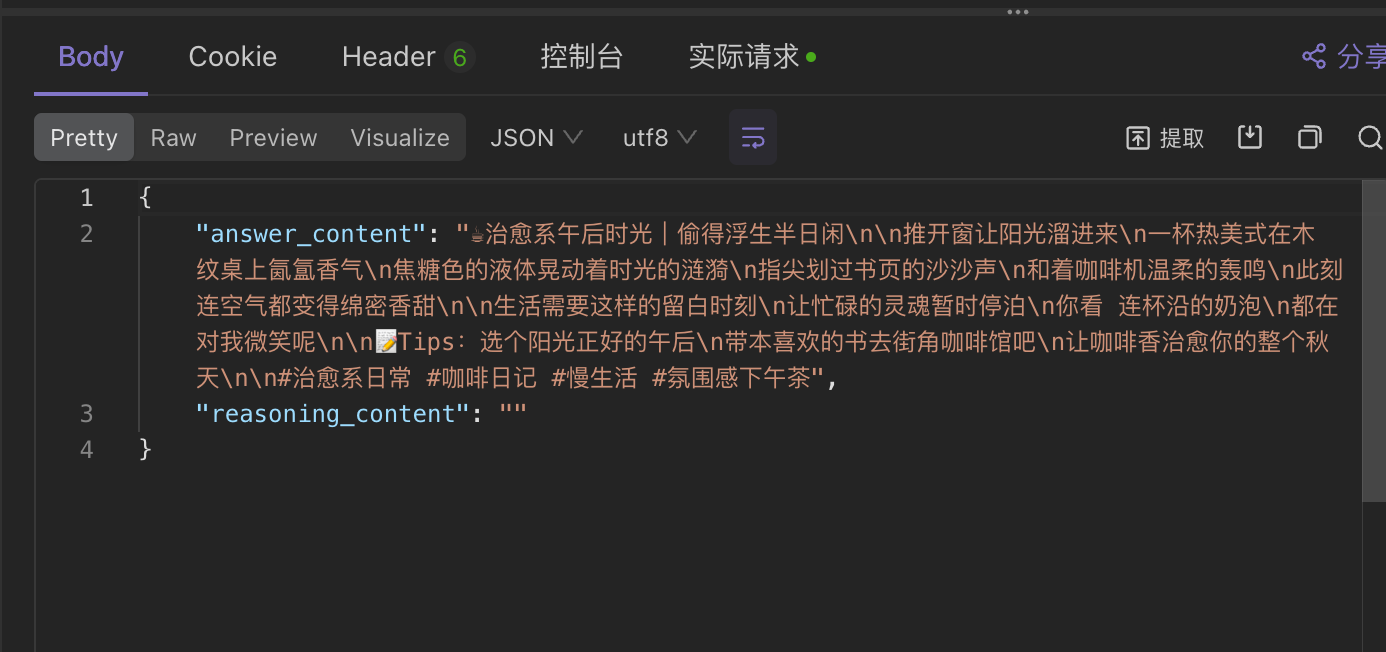
postman 接口配置示例
我们输入的content内容是:请根据以下内容生成500字小红书种草文案:↵关键词:三亚,海边,游泳,拍照↵, 发送请求查看结果
此时我们的DeepSeek接口的本地调用就已经完成了。
整体来说整个过程还是蛮丝滑的, 接下来我们分析一下 如和实现小程序的对接。
4. 小程序代码实现
ui 代码层
<template>
<view class="content">
<!-- <view class="upload-section">
<uv-upload
:fileList="fileList"
@afterRead="afterRead"
@delete="deletePic"
:maxCount="1"
name="1"
></uv-upload>
</view> -->
<view class="txtArea">
<uv-textarea
v-model="textArea"
placeholder="请输入关键词,以逗号隔开"
:height="150"
:border="'surround'"
:count="true"
:maxlength="500"
></uv-textarea>
</view>
<view class="type-section">
<uv-radio-group
v-model="typeValue"
placement="row"
@change="handleChangeType"
:wrap="false"
>
<uv-radio
v-for="(item, index) in typeOptions"
:key="index"
:name="item.value"
:label="item.text"
></uv-radio>
</uv-radio-group>
</view>
<view class="button-section">
<uv-button
type="primary"
text="开始生成"
@click="startGenerate"
></uv-button>
<uv-button type="info" text="重置" @click="resetForm"></uv-button>
</view>
<view class="result-section">
<uv-loading-icon
v-if="loading"
text="文案生成中..."
mode="circle"
size="28"
></uv-loading-icon>
<uv-text v-if="resultText" :text="resultText"></uv-text>
</view>
</view>
</template>
tip: 关于注释地方会在最下面的附录项进行讲解说明
接口调用方法
startGenerate() {
// 1. 判断用户是否上传图片或输入关键词
if (!this.textArea) {
uni.showToast({
title: "请输入关键词",
icon: "none",
});
return;
}
// 2. 配置prompt提示词
let prompt = `请根据以下内容生成500字${this.typeText}文案:\n`;
// 添加关键词内容
if (this.textArea) {
prompt += `关键词:${this.textArea}\n`;
}
// 添加图片信息
// if (this.fileList.length > 0) {
// prompt += `${this.fileList[0].url}\n`;
// }
// 3. 设置加载状态
this.loading = true;
// 4. 接口调用
request({
url: "/deepseekapi",
method: "POST",
data: {
content: prompt,
},
})
.then((res) => {
console.log("生成成功:", res);
this.loading = false;
this.resultText =
res.answer_content || "文案生成失败,请稍后重试...";
})
.catch((err) => {
console.error("生成失败:", err);
this.loading = false;
});
},
此处我们主要实现的事对于提示词的拼接,然后进行接口的调用, 需要注意的是 ,我进行的提示词拼接可能并不是最完美的, 具体应用到业务层时还需要微调哦!!
效果演示
如下图所示:
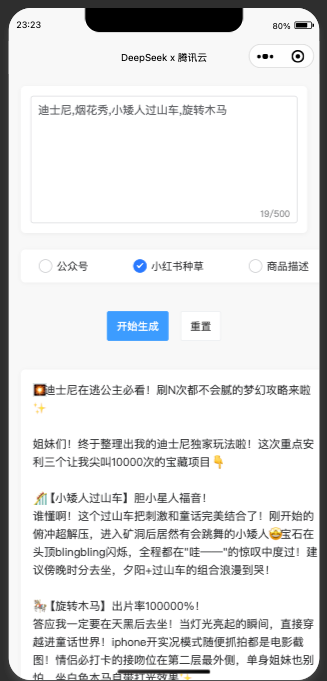
附录
该小程序其实最初的设计是有个图片识别功能, 通过识别图片来生成对应的文案, 但是目前如果仅使用腾讯云DeepSeek API 是无法实现该功能的,需要结合 大模型知识引擎 中的图片对话或文件对话(实时文档解析+对话) 的接口,通过识别图片内容之后再次调用腾讯云DeepSeek API 来获取对应的文案。
总结
通过本教程,开发者可以快速搭建一个基于腾讯云DeepSeek API的文案生成小程序,为内容创作提供AI助手支持。后续还可以扩展更多功能,如图片识别等高级特性,进一步提升应用的实用性。
uniapp源码访问地址 : https://gitcode.com/qq_33681891/txDeepseek



















 366
366

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











