







Flume的高可用分布式串行采集数据到HDFS示例
一、案例介绍
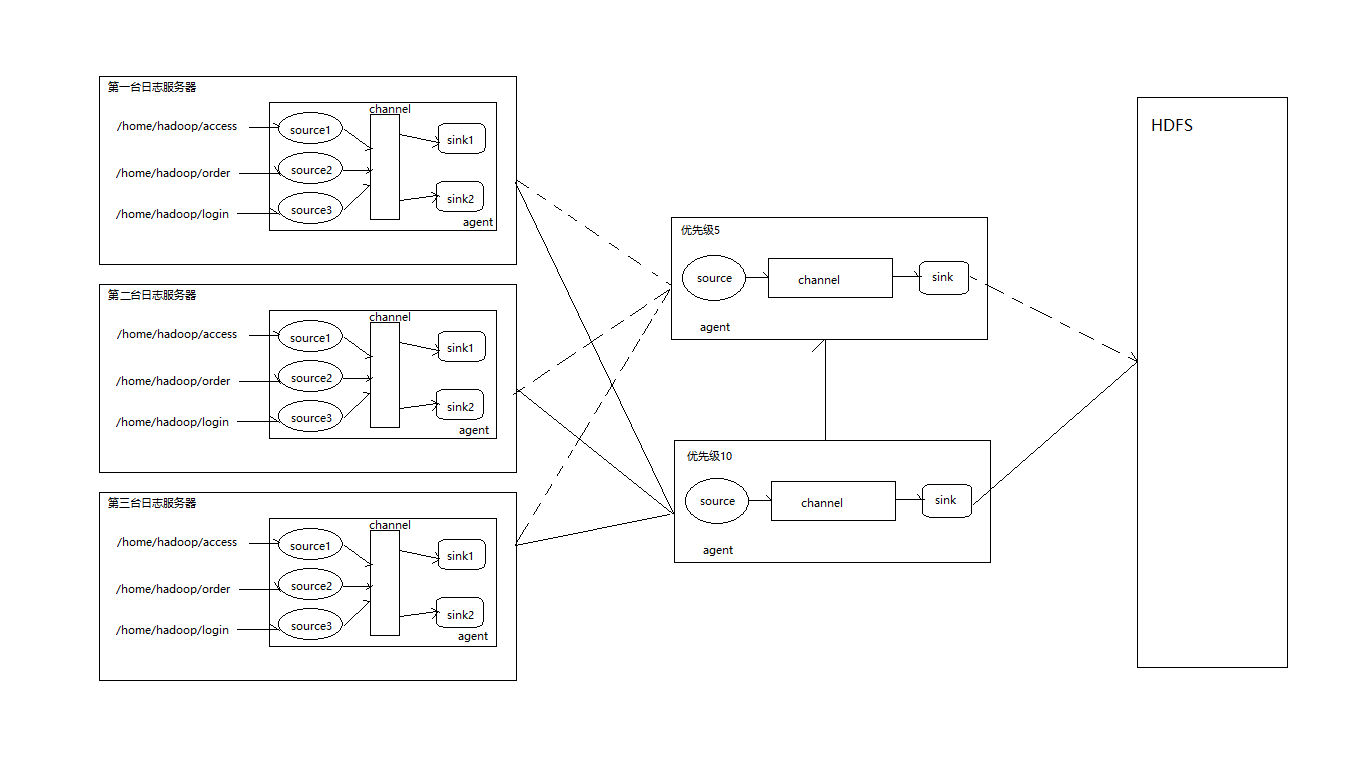
需要将3台log日志服务器(ip分别为:192.168.100.9,192.168.100.13,192.168.100.100)中的/home/hadoop/access,/home/hadoop/order,/home/hadoop/login文件夹中的log日志下沉(sink)到另外的agent集群中。
agent集群是使用2台机器(ip分别是:192.168.10.11,192.168.10.12)。其中192.169.100.11作为主(优先级10),192.169.100.12作为从(优先级5)。
agent集群收集的数据下沉(sink)到HDFS系统中。
收集数据需要按照主机ip,access,order,login进行分类,写到hdfs文件系统中。
分布式框架如图所示:
下面具体看配置文件
二、配置
- 日志客户端的agent配置信息,配置文件名称为
flume-collect-local-log.conf:
a1.sources=r1 r2 r3
a1.sinks=k1 k2
a1.channels=c1
a1.sinkgroups = g1
# r1
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /home/hadoop/access
a1.sources.r1.fileHeader = false
# r2
a1.sources.r2.type = spooldir
a1.sources.r2.spoolDir = /home/hadoop/order
a1.sources.r3.fileHeader = false
# r3
a1.sources.r3.type = spooldir
a1.sources.r3.spoolDir = /home/hadoop/login
a1.sources.r3.fileHeader = false
# r1拦截器
a1.sources.r1.interceptors = i1 i2
a1.sources.r1.interceptors.i1.type=static
a1.sources.r1.interceptors.i1.preserveExisting = true
a1.sources.r1.interceptors.i1.key = source
a1.sources.r1.interceptors.i1.value = access
a1.sources.r1.interceptors.i2.type=host
a1.sources.r1.interceptors.i2.hostHeader = hostname
# r2拦截器
a1.sources.r2.interceptors = i1 i2
a1.sources.r2.interceptors.i1.type=static
a1.sources.r2.interceptors.i1.preserveExisting = true
a1.sources.r2.interceptors.i1.key = source
a1.sources.r2.interceptors.i1.value = order
a1.sources.r2.interceptors.i2.type=host
a1.sources.r2.interceptors.i2.hostHeader = hostname
# r3拦截器
a1.sources.r3.interceptors = i1 i2
a1.sources.r3.interceptors.i1.type=static
a1.sources.r3.interceptors.i1.preserveExisting = true
a1.sources.r3.interceptors.i1.key = source
a1.sources.r3.interceptors.i1.value = login
a1.sources.r3.interceptors.i2.type=host
a1.sources.r3.interceptors.i2.hostHeader = hostname
# k1
a1.sinks.k1.type=avro
a1.sinks.k1.hostname = 192.168.100.11
a1.sinks.k1.port = 11111
# k2
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = 192.168.100.12
a1.sinks.k2.port = 11111
# c1
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 设置sink group优先级
a1.sinkgroups.g1.sinks = k1 k2
a1.sinkgroups.g1.processor.type = failover
a1.sinkgroups.g1.processor.priority.k1 = 10
a1.sinkgroups.g1.processor.priority.k2 = 5
a1.sinkgroups.g1.processor.maxpenalty = 10000
# r1 r2 r3 c1 s1关系配置8
a1.sources.r1.channels = c1
a1.sources.r2.channels = c1
a1.sources.r3.channels = c1
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c1这里配置了static拦截器,用于传递标识,给HDFS进行分区
- agent集群的配置信息,配置文件名称为
flume-collect-hdfs.conf:
a1.sources = r1
a1.channels = c1
a1.sinks = k1
# r1
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 11111
# 拦截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = timestamp
# s1
a1.sinks.k1.type=hdfs
a1.sinks.k1.hdfs.path=/flume-log/%{source}/%{hostname}/%y%m%d
a1.sinks.k1.hdfs.fileType=DataStream
a1.sinks.k1.hdfs.writeFormat=TEXT
a1.sinks.k1.hdfs.rollInterval=1
a1.sinks.k1.hdfs.filePrefix=%Y-%m-%d
a1.sinks.k1.hdfs.fileSuffix=.txt
a1.sinks.k1.hdfs.rollSize = 1024
a1.sinks.k1.hdfs.rollCount = 10
a1.sinks.k1.hdfs.rollInterval = 60
# c1
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 配置r1 s1 c1的关系
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1三、执行
- 给log日志服务器的
access,order,login目录写入测试文件。如:
access.log
access 192.168.100.9order.log
order 192.168.100.9login.log
login 192.168.100.9给每一台机器的对应目录设置写入不同的内容,测试hdfs分区情况
- 分别启动agent集群中的(
192.168.100.11和192.168.100.12)的flume服务
bin/flume-ng agent -c conf -f conf/flume-collect-hdfs.conf -name a1 -Dflume.root.logger=INFO,console- 分别启动log日志中的flume服务
bin/flume-ng agent -c conf -f conf/flume-collect-local-log.conf -name a1 -Dflume.root.logger=INFO,console四、查看结果
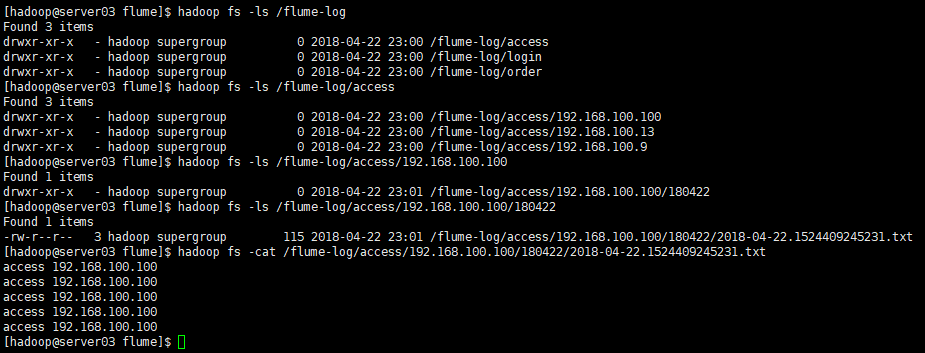
结果是分区状态的。
补充:Flume的负载平衡示例
Flume的客户端收集日志的conf文件。通过a1.sinkgroups.g1.processor.type = load_balance实现负载均衡。
#a1 name
a1.channels = c1
a1.sources = r1
a1.sinks = k1 k2
#set gruop
a1.sinkgroups = g1
#set channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/hadoop/logs/test.log
# set sink1
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = 192.168.100.11
a1.sinks.k1.port = 11111
# set sink2
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = 192.168.100.12
a1.sinks.k2.port = 11111
#set sink group
a1.sinkgroups.g1.sinks = k1 k2
#set load-balance
a1.sinkgroups.g1.processor.type = load_balance
# 默认是round_robin,还可以选择random
a1.sinkgroups.g1.processor.selector = round_robin
#如果backoff被开启,则 sink processor会屏蔽故障的sink
a1.sinkgroups.g1.processor.backoff = true
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c1flume的服务器端代码和上面一样的。















 1726
1726

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









