







一、背景
LightRAG是由北邮和港大联合出品,是一款微软GraphRAG的优秀替代者。公司最近开始进行大模型与业务之间的结合,为了可以提供更多的技术选型或者为技术开发提供更多创作思路,所以有了这篇文章。
二、LightRAG简介
LightRAG是个精炼的RAG框架,使用Python来实现,专门用于通过检索关键知识片段来构建响应,并且整合了知识图谱和嵌入技术。
与只是将文档简单拆分成独立片段的
统RAG系统不同,LightRAG进一步深化了这一过程——创建了实体与实体之间的关系对,将文本中的概念紧密联系起来。
它与微软的GraphRAG有相似之处,但LightRAG在速度和成本上更具优势,并且支持对图谱进行增量更新,无需每次都重新生成整个图谱。
本文主要是讲解LightRag的原理,如果想了解LightRag怎么安装和使用请看下面这篇文章:LightRag 安装及其使用向导-CSDN博客
三、LightRAG较于GraphRAG的优势
GraphRAG与LightRAG都依赖大模型帮忙语义解析语义,构建知识图谱。但是GraphRag通常需要大量的调用大模型,并且常常需要使用成本较高的模型,例如GPT-4o。每当数据更新时,GraphRAG都需要重新构建整个图谱,这无疑增加了额外的成本。
相比之下,LightRAG则展现了其独特的优势,它不仅减少了大模型的调用次数节约了成本。
同时对于知识图谱的更新也是采用增量更新的模式。同时根据LightRAG的实验结果,也可以看出LightRAG在多个领域处理多中不同类型的任务能力上也强于其他RAG。
| 农业 | 计算机科学 | 法律 | 混合 | |||||
|---|---|---|---|---|---|---|---|---|
| NaiveRAG | LightRAG | NaiveRAG | LightRAG | NaiveRAG | LightRAG | NaiveRAG | LightRAG | |
| 全面性 | 32.4% | 67.6% | 38.4% | 61.6% | 16.4% | 83.6% | 38.8% | 61.2% |
| 多样性 | 23.6% | 76.4% | 38.0% | 62.0% | 13.6% | 86.4% | 32.4% | 67.6% |
| 赋能性 | 32.4% | 67.6% | 38.8% | 61.2% | 16.4% | 83.6% | 42.8% | 57.2% |
| 总体 | 32.4% | 67.6% | 38.8% | 61.2% | 15.2% | 84.8% | 40.0% | 60.0% |
| RQ - RAG | LightRAG | RQ - RAG | LightRAG | RQ - RAG | LightRAG | RQ - RAG | LightRAG | |
| 全面性 | 31.6% | 68.4% | 38.8% | 61.2% | 15.2% | 84.8% | 39.2% | 60.8% |
| 多样性 | 29.2% | 70.8% | 39.2% | 60.8% | 11.6% | 88.4% | 30.8% | 69.2% |
| 赋能性 | 31.6% | 68.4% | 36.4% | 63.6% | 15.2% | 84.8% | 42.4% | 57.6% |
| 总体 | 32.4% | 67.6% | 38.0% | 62.0% | 14.4% | 85.6% | 40.0% | 60.0% |
| HyDE | LightRAG | HyDE | LightRAG | HyDE | LightRAG | HyDE | LightRAG | |
| 全面性 | 26.0% | 74.0% | 41.6% | 58.4% | 26.8% | 73.2% | 40.4% | 59.6% |
| 多样性 | 24.0% | 76.0% | 38.8% | 61.2% | 20.0% | 80.0% | 32.4% | 67.6% |
| 赋能性 | 25.2% | 74.8% | 40.8% | 59.2% | 26.0% | 74.0% | 46.0% | 54.0% |
| 总体 | 24.8% | 75.2% | 41.6% | 58.4% | 26.4% | 73.6% | 42.4% | 57.6% |
| GraphRAG | LightRAG | GraphRAG | LightRAG | GraphRAG | LightRAG | GraphRAG | LightRAG | |
| 全面性 | 45.6% | 54.4% | 48.4% | 51.6% | 48.4% | 51.6% | 50.4% | 49.6% |
| 多样性 | 22.8% | 77.2% | 40.8% | 59.2% | 26.4% | 73.6% | 36.0% | 64.0% |
| 赋能性 | 41.2% | 58.8% | 45.2% | 54.8% | 43.6% | 56.4% | 50.8% | 49.2% |
| 总体 | 45.2% | 54.8% | 48.0% | 52.0% | 47.2% | 52.8% | 50.4% | 49.6% |
四、LightRag调用流程分析
Rag技术分为两个部分:Input Document 和 Query
4.1 Input Document
4.1.1 图增强实体和关系提取
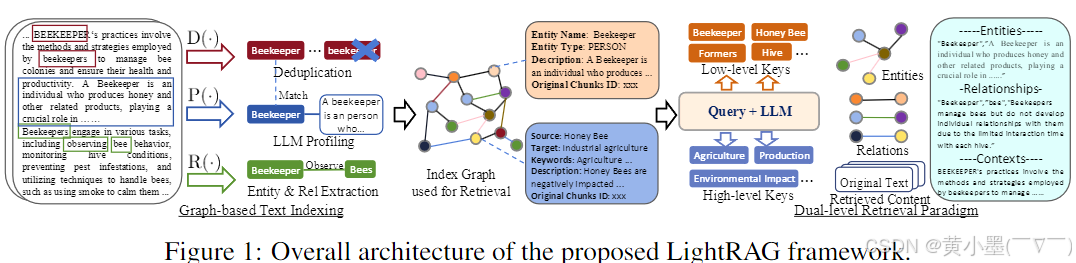
先将文档分割成小块以便快速识别和获取信息,接着利用大语言模型(LLM)提取各类实体(如名称、日期等)及其关系,这些信息用于构建知识图。其具体过程涉及三个函数:R(.)用于提取实体和关系,通过将原始文本分割成块提高效率;P(.)借助 LLM 为实体节点和关系边缘生成文本键值对,便于检索和文本生成;D(.)对原始文本不同片段中的相同实体和关系进行去重,减少图操作开销。
4.1.2 快速适应增量知识库
面对数据变化,LightRag 采用增量更新算法。对于新文档,依循原有图索引步骤处理后与原知识图合并,实现新数据无缝集成,同时避免重建整个索引图,降低计算开销,确保系统能提供最新信息且保持准确性和高效性。
4.1.3 Input Document 全流程介绍
1.将文件切割成块并去重,方便传递给LLM。
2.提取块中的实体与实体关系。
3.利用算法去重实体、实体关系。
4.获取实体或者关系之前的数据,和提取到新描述的数据合并。如果超出系统设置最大长度,则提交到LLM进行一次总结。
4.2 QUERY
4.2.1 双层检索机制
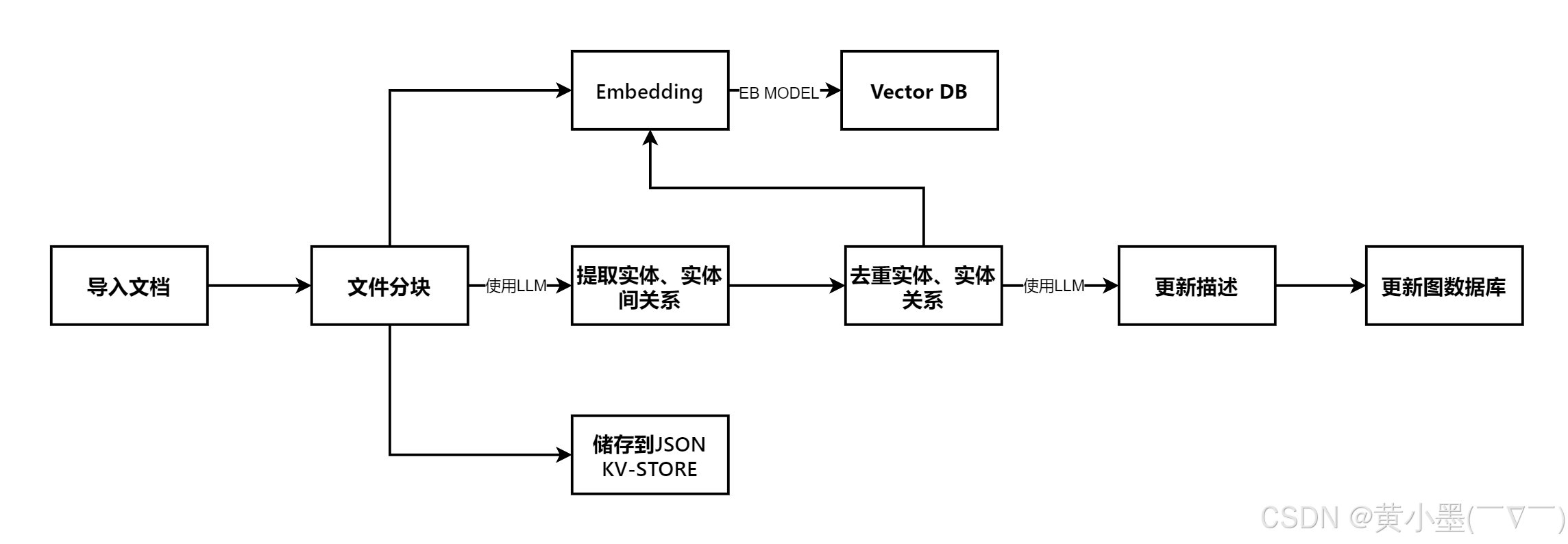
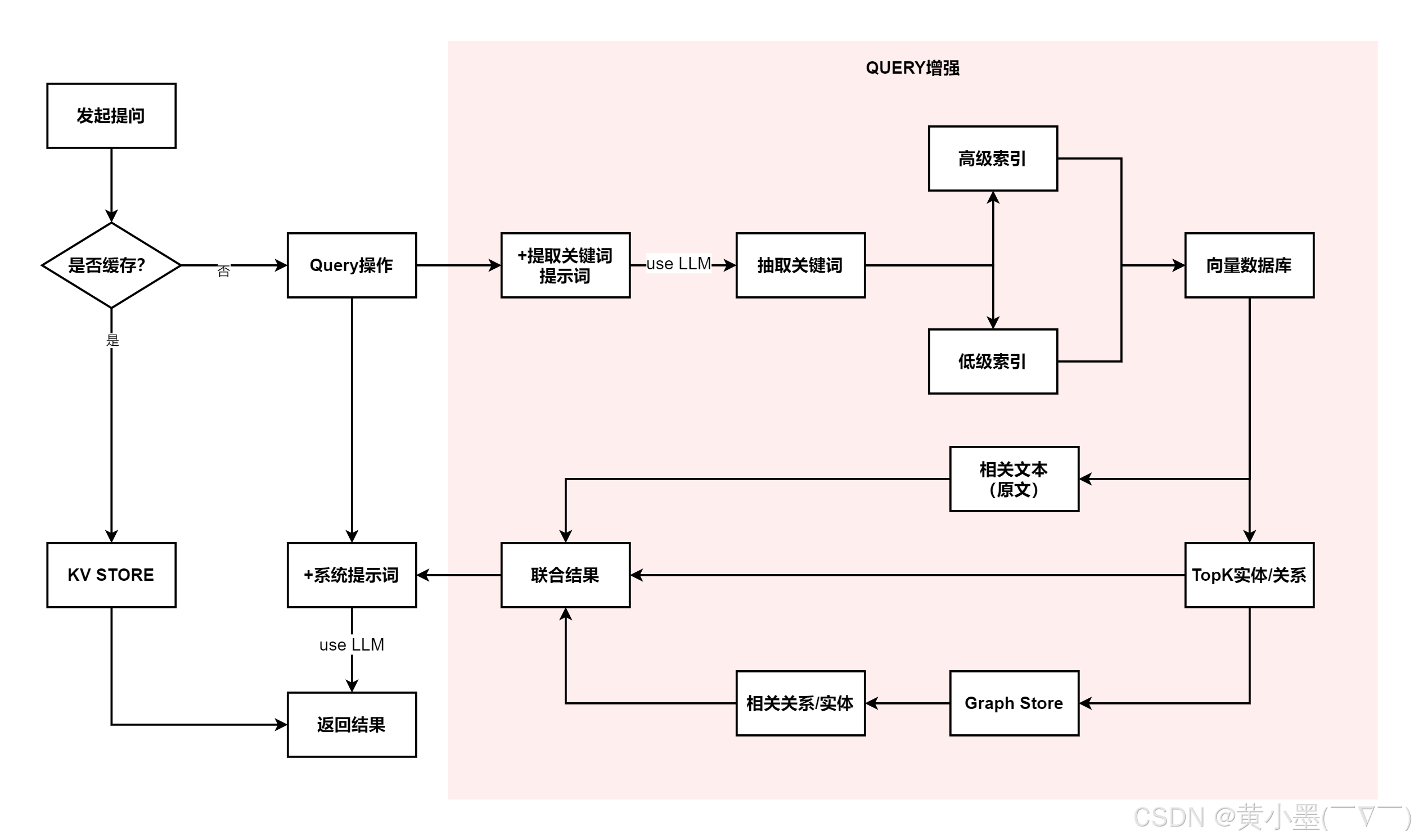
低级检索以细节为导向检索特定实体及其属性或关系信息,旨在检索图谱中指定节点或边的精确信息;高级检索处理更加概念化涵盖更广泛的主题、摘要,其并非与特定实体关联,聚合多个相关实体和关系的信息,为高级的概念及摘要提供洞察力。同时使用了图结构和向量表示使得检索算法有效地利用,有效地利用局部和全局关键词,简化搜索过程并提高结果的关联性。
下面是关键词提取示例:

4.2.2 query增强全流程介绍
介绍完 LightRag 的关键技术,就来总体的介绍一下 Query 的流程:
1、查询关键词提取:给传入的问题结合系统提示词,发给大模型分别提取局部查询关键词和全部查询关键词
2、关键词匹配:检索算法使用向量数据库来匹配局部查询关键词与候选实体,以及全局查询关键词与候选关系(与全局关键词关联)
3、增强高阶关联性: LightRAG进一步收集已检索到的实体或关系的局部子图,如实体或关系的一跳邻近节点
4、检索增强回答生成:利用已检索的信息,包括实体名、实体描述、关系描述以及原文片段,LightRAG使用通用的LLM来生成回答。
下面是一次问答 QUERY 增强的示例:

五、未来展望
之后打算研究MiniRag,以及研究大模型调优后的测试方法。
GitHub - HKUDS/MiniRAG: "MiniRAG: Making RAG Simpler with Small and Free Language Models"


















 2665
2665

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









