







“Most text classification and document categorization systems can be deconstructed into the following four phases: Feature extraction, dimension reductions, classifier selection, and evaluations.”
大多数文本分类和文档分类系统可以分解为以下四个阶段:特征提取、降维、分类器选择和评估。
“In this paper, we discuss the structure and technical implementations of text classification systems in terms of the pipeline illustrated in Figure 1。”
在本文中,我们根据图1所示的流程图来讨论文本分类系统的结构和技术实现。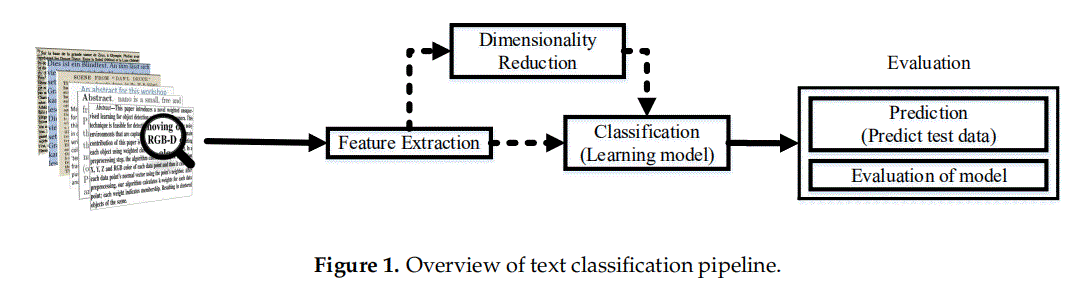
(I) Feature Extraction 特征提取
“The common techniques of feature extractions are Term Frequency-Inverse Document Frequency (TF-IDF), Term Frequency (TF) [9], Word2Vec [10], and Global Vectors for Word Representation (GloVe) [11].”
常用的特征提取技术有,TF-IDF、TF[9]、Word2Vec[10]和GloVe[11]。
“In Section 2, we categorize these methods as either word embedding or weighted word techniques.”
在第2节中,我们将这些方法分类为词嵌入和词加权技术。
(II) Dimensionality Reduction 降维
“As text or document data sets often contain many unique words, data pre-processing steps can be lagged by high time and memory complexity.”
由于文本或文档数据集通常包含许多独特的单词,数据预处理步骤可能会由于较高的时间和空间复杂度而受限。
“A common solution to this problem is simply using inexpensive algorithms. However, in some data sets, these kinds of cheap algorithms do not perform as well as expected. In order to avoid the decrease in performance, many researchers prefer to use dimensionality reduction to reduce the time and memory complexity for their applications. Using dimensionality reduction for pre-processing could be more efficient than developing inexpensive classifiers.”
这个问题的一个常见解决方案是简单地使用廉价的算法。然而,在某些数据集中,这些廉价算法的性能并没有预期的那么好。为了避免性能下降,许多研究人员倾向于使用降维来降低其应用程序的时间和空间复杂度。使用降维进行预处理比开发廉价的分类器更有效。
“In Section 3, we outline the most common techniques of dimensionality reduction, including Principal Component Analysis (PCA), Linear Discriminant Analysis (LDA), and non-negative matrix factorization (NMF). We also discuss novel techniques for unsupervised feature extraction dimensionality reduction, such as random projection, autoencoders, and t-distributed stochastic neighbor embedding (t-SNE).”
在第3节中,我们概述了最常见的降维技术,包括主成分分析(PCA)、线性判别分析(LDA)和非负矩阵分解(NMF)。我们也讨论了无监督特征提取降维的新技术,如随机投影、自动编码器和t分布随机邻域嵌入(t-SNE)。
(III) Classification Techniques 分类技术
“In Section 4, we discuss the most popular techniques of text classification. First, we cover traditional methods of text classification, such as Rocchio classification. Next, we talk about ensemble-based learning techniques such as boosting and bagging, which have been used mainly for query learning strategies and text analysis [12-14].”
在第4节中,我们将讨论最流行的文本分类技术。首先,我们介绍传统的文本分类方法,如Rocchio分类。接下来,我们将讨论基于集成学习技术,如boosting和bagging,它们主要用于查询学习策略和文本分析 [12-14]。
“One of the simplest classification algorithms is logistic regression (LR) which has been addressed in most data mining domains [15-18].”
logistic回归(LR)是最简单的分类算法之一,它在大多数数据挖掘领域都得到了应用[15-18]。
(IV) Evaluation 评估
“In Section 5, we outline the following evaluation methods for text classification algorithms: Fβ Score[29], Matthews Correlation Coefficient (MCC)[30], receiver operating characteristics (ROC)[31], and area under the ROC curve (AUC)[32].”
在第5节中,我们概述了以下文本分类算法的评价方法:Fβ 分数[29],马修斯相关系数(MCC)[30],ROC[31],ROC曲线下面积(AUC)[32]。
“Information retrieval systems [33] and search engine [34,35] applications commonly make use of text classification methods. Extending from these applications, text classification could also be used for applications such as information filtering (e.g., email and text message spam filtering) [36]. Next, we talk about adoption of document categorization in public health [37] and human behavior [38]. Another area that has been helped by text classification is document organization and knowledge management. Finally, we will discuss recommender systems which are extensively used in marketing and advertising.”
信息检索系统[33]和搜索引擎[34,35]的应用通常都采用文本分类方法。从这些应用程序扩展开来,文本分类也可用于信息过滤(例如电子邮件和文本信息垃圾过滤)等应用程序[36]。接下来,我们将讨论在公共卫生[37]和人类行为[38]中采用的文档分类。文本分类帮助的另一个领域是文档组织和知识管理。最后,我们将讨论在市场营销和广告中广泛应用的推荐系统。
参考资料:
[9] Salton, G.; Buckley, C. Term-weighting approaches in automatic text retrieval. Inf. Process. Manag. 1988, 24, 513–523.
[10] Goldberg, Y.; Levy, O. Word2vec explained: Deriving mikolov et al.’s negative-sampling word-embedding method. arXiv 2014, arXiv:1402.3722.
[11] Pennington, J.; Socher, R.; Manning, C.D. Glove: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; Volume 14, pp. 1532–1543.
[12] Mamitsuka, N.A.H. Query learning strategies using boosting and bagging. In Machine Learning: Proceedings of the Fifteenth International Conference (ICML’98); Morgan Kaufmann Pub.: Burlington, MA, USA, 1998; Volume 1.
[13] Kim, Y.H.; Hahn, S.Y.; Zhang, B.T. Text filtering by boosting naive Bayes classifiers. In Proceedings of the 23rd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Athens, Greece, 24–28 July 2000; pp. 168–175.
[14] Schapire, R.E.; Singer, Y. BoosTexter: A boosting-based system for text categorization. Mach. Learn. 2000, 39, 135–168.
[15] Harrell, F.E. Ordinal logistic regression. In Regression Modeling Strategies; Springer: Berlin/Heidelberg, Germany, 2001; pp. 331–343.
[16] Hosmer, D.W., Jr.; Lemeshow, S.; Sturdivant, R.X. Applied Logistic Regression; John Wiley & Sons: Hoboken, NJ, USA, 2013; Volume 398.
[17] Dou, J.; Yamagishi, H.; Zhu, Z.; Yunus, A.P.; Chen, C.W. TXT-tool 1.081-6.1 A Comparative Study of the Binary Logistic Regression (BLR) and Artificial Neural Network (ANN) Models for GIS-Based Spatial Predicting Landslides at a Regional Scale. In Landslide Dynamics: ISDR-ICL Landslide Interactive Teaching Tools; Springer: Berlin/Heidelberg, Germany, 2018; pp. 139–151.
[18] Chen, W.; Xie, X.; Wang, J.; Pradhan, B.; Hong, H.; Bui, D.T.; Duan, Z.; Ma, J. A comparative study of logistic model tree, random forest, and classification and regression tree models for spatial prediction of landslide susceptibility. Catena 2017, 151, 147–160.
[29] Lock, G. Acute mesenteric ischemia: Classification, evaluation and therapy. Acta Gastro-Enterol. Belg. 2002, 65, 220–225.
[30] Matthews, B.W. Comparison of the predicted and observed secondary structure of T4 phage lysozyme. Biochim. Biophys. Acta (BBA)-Protein Struct. 1975, 405, 442–451.
[31] Hanley, J.A.; McNeil, B.J. The meaning and use of the area under a receiver operating characteristic (ROC) curve. Radiology 1982, 143, 29–36.
[32] Pencina, M.J.; D’Agostino, R.B.; Vasan, R.S. Evaluating the added predictive ability of a new marker: From area under the ROC curve to reclassification and beyond. Stat. Med. 2008, 27, 157–172.
[33] Jacobs, P.S. Text-Based Intelligent Systems: Current Research and Practice in Information Extraction and Retrieval; Psychology Press: Hove, UK, 2014.
[34] Croft, W.B.; Metzler, D.; Strohman, T. Search Engines: Information Retrieval in Practice; Addison-Wesley Reading: Boston, MA, USA, 2010; Volume 283.
[35] Yammahi, M.; Kowsari, K.; Shen, C.; Berkovich, S. An efficient technique for searching very large files with fuzzy criteria using the pigeonhole principle. In Proceedings of the 2014 Fifth International Conference on Computing for Geospatial Research and Application,Washington, DC, USA, 4–6 August 2014; pp. 82–86.
[36] Chu, Z.; Gianvecchio, S.; Wang, H.; Jajodia, S. Who is tweeting on Twitter: Human, bot, or cyborg? In Proceedings of the 26th Annual Computer Security Applications Conference, Austin, TX, USA, 6–10 December 2010; pp. 21–30.
[37] Gordon, R.S., Jr. An operational classification of disease prevention. Public Health Rep. 1983, 98, 107.
[38] Nobles, A.L.; Glenn, J.J.; Kowsari, K.; Teachman, B.A.; Barnes, L.E. Identification of Imminent Suicide Risk Among Young Adults using Text Messages. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, Montreal, QC, Canada, 21–26 April 2018; p. 413.















 1320
1320











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











