






refer : https://yq.aliyun.com/articles/530060?spm=a2c4e.11153940.blogcont181452.16.413f2ef21NKngz#
http://www.datayuan.cn/article/6737.htm
https://yq.aliyun.com/articles/210393?spm=a2c4e.11153940.blogcont381482.21.77131127S0t3io
-
--
大文本数据的读写
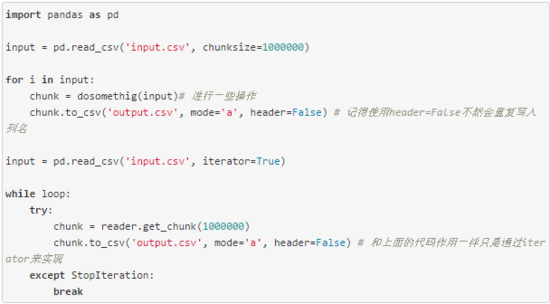
有时候我们会拿到一些很大的文本文件,完整读入内存,读入的过程会很慢,甚至可能无法读入内存,或者可以读入内存,但是没法进行进一步的计算,这个时候如果我们不是要进行很复杂的运算,可以使用read_csv提供的chunksize或者iterator参数,来部分读入文件,处理完之后再通过to_csv的mode='a',将每部分结果逐步写入文件。
to_csv, to_excel的选择
在输出结果时统称会遇到输出格式的选择,平时大家用的最多的.csv, .xls, .xlsx,后两者一个是excel2003,一个是excel2007,我的经验是csv>xls>xlsx,大文件输出csv比输出excel要快的多,xls只支持60000+条记录,xlsx虽然支持记录变多了,但是,如果内容有中文常常会出现诡异的内容丢失。因此,如果数量较小可以选择xls,而数量较大则建议输出到csv,xlsx还是有数量限制,而且 大数据 量的话,会让你觉得python都死掉了
读入时处理日期列
我之前都是在数据读入后通过to_datetime函数再去处理日期列,如果数据量较大这又是一个浪费时间的过程,其实在读入数据时,可以通过parse_dates参数来直接指定解析为日期的列。它有几种参数,TRUE的时候会将index解析为日期格式,将列名作为list传入则将每一个列都解析为日期格式
关于to_datetime函数再多说几句,我们拿到的时期格式常常出现一些乱七八糟的怪数据,遇到这些数据to_datimetime函数默认会报错,其实,这些数据是可以忽略的,只需要在函数中将errors参数设置为'ignore'就可以了。
另外,to_datetime就像函数名字显示的,返回的是一个时间戳,有时我们只需要日期部分,我们可以在日期列上做这个修改,datetime_col = datetime_col.apply(lambda x: x.date()),用map函数也是一样的datetime_col = datetime_col.map(lambda x: x.date())
把一些数值编码转化为文字
前面提到了map方法,我就又想到了一个小技巧,我们拿到的一些数据往往是通过数字编码的,比如我们有gender这一列,其中0代表男,1代表女。当然我们可以用索引的方式来完成
其实我们有更简单的方法,对要修改的列传入一个dict,就会达到同样的效果。
通过shift函数求用户的相邻两次登录记录的时间差
之前有个项目需要计算用户相邻两次登录记录的时间差,咋看起来其实这个需求很简单,但是数据量大起来的话,就不是一个简单的任务,拆解开来做的话,需要两个步骤,第一步将登录数据按照用户分组,再计算每个用户两次登录之间的时间间隔。数据的格式很单纯,如下所示
如果数据量不大的,可以先unique uid,再每次计算一个用户的两次登录间隔,类似这样
这种方法虽然计算逻辑比较清晰易懂,但是缺点也非常明显,计算量巨大,相当与有多少量记录就要计算多少次。
那么为什么说pandas的shift函数适合这个计算呢?来看一下shift函数的作用
刚好把值向下错位了一位,是不是恰好是我们需要的。让我们用shift函数来改造一下上面的代码。
上面的代码就把pandas向量化计算的优势发挥出来了,规避掉了计算过程中最耗费时间的按uid循环。如果我们的uid都是一个只要排序后用shift(1)就可以取到所有前一次登录的时间,不过真实的登录数据中有很多的不用的uid,因此再将uid也shift一下命名为uid0,保留uid和uid0匹配的记录就可以了。
-
Python数据预处理:使用Dask和Numba并行化加速
【方向】 2018-03-12 11:11:49 浏览2650 评论0
python
大数据
摘要: 本文是针对Python设计一种并行处理数据的解决方案——使用Dask和Numba并行化加速运算速度。案例对比分析了几种不同方法的运算速度,非常直观,可供参考。
如果你善于使用Pandas变换数据、创建特征以及清洗数据等,那么你就能够轻松地使用Dask和Numba并行加速你的工作。单纯从速度上比较,Dask完胜Python,而Numba打败Dask,那么Numba+Dask基本上算是无敌的存在。将数值计算分成Numba sub-function和使用Dask map_partition+apply,而不是使用Pandas。对于100万行数据,使用Pandas方法和混合数值计算创建新特征的速度比使用Numba+Dask方法的速度要慢许多倍。
Python:60.9x | Dask:8.4x | Numba:5.8x |Numba+Dask:1x
8be99f10ed908533e525b81fcd04bcdf3b27db2d
作为旧金山大学的一名数据科学硕士,会经常跟数据打交道。使用Apply函数是我用来创建新特征或清理数据的众多技巧之一。现在,我只是一名数据科学家,而不是计算机科学方面的专家,但我是一个喜欢捣鼓并使得代码运行更快的程序员。现在,我将会分享我在并行应用上的经验。
大多Python爱好者可能了解Python实现的全局解释器锁(GIL),GIL会占用计算机中所有的CPU性能。更糟糕的是,我们主要的数据处理包,比如Pandas,很少能实现并行处理代码。
Apply函数vs Multiprocessing.map
Tidyverse已经为处理数据做了一些美好的事情,Plyr是我最喜爱的数据包之一,它允许R语言使用者轻松地并行化他们的数据应用。Hadley Wickham说过:
“plyr是一套处理一组问题的工具:需要把一个大的数据结构分解成一些均匀的数据块,之后对每一数据块应用一个函数,最后将所有结果组合在一起。”
对于Python而言,我希望有类似于plyr这样的数据包可供使用。然而,目前这样的数据包还不存在,但我可以使用并行数据包构成一个简单的解决方案。
Dask
bbcc3ca9a96dc7ad7129d9047a2d58be57a4ed84
之前在Spark上花费了一些时间,因此当我开始使用Dask时,还是比较容易地掌握其重点内容。Dask被设计成能够在多核CPU上并行处理任务,此外也借鉴了许多Pandas的语法规则。
现在开始本文所举例子。对于最近的数据挑战而言,我试图获取一个外部数据源(包含许多地理编码点),并将其与要分析的一大堆街区相匹配。在计算欧几里得距离的同时,使用最大启发式将最大值分配给一个街区。
8809febd555c55a69522a58770971c8cf0c57af5
最初的apply:
Dask apply:
二者看起来很相似,apply核心语句是map_partitions,最后有一个compute()语句。此外,不得不对npartitions初始化。 分区的工作原理就是将Pandas数据帧划分成块,对于我的电脑而言,配置是6核-12线程,我只需告诉它使用的是12分区,Dask就会完成剩下的工作。
接下来,将map_partitions的lambda函数应用于每个分区。由于许多数据处理代码都是独立地运行,所以不必过多地担心这些操作的顺序问题。最后,compute()函数告诉Dask来处理剩余的事情,并把最终计算结果反馈给我。在这里,compute()调用Dask将apply适用于每个分区,并使其并行处理。
由于我通过迭代行来生成一个新队列(特征),而Dask apply只在列上起作用,因此我没有使用Dask apply,以下是Dask程序:
Numba、Numpy和Broadcasting
由于我是根据一些简单的线性运算(基本上是勾股定理)对数据进行分类,所以认为使用类似下面的Python代码会运行得更快一些。
d31908d0ecfefd263b3e5373461b34374de9adf5
Broadcasting用以描述Numpy中对两个形状不同的矩阵进行数学计算的处理机制。假设我有一个数组,我会通过迭代并逐个变换每个单元格来改变它
相反,我完全可以跳过for循环,并对整个数组执行操作。Numpy与broadcasting混合使用,用来执行元素智能乘积(对位相乘)。
Broadcasting可以实现更多的功能,现在看看骨架代码:
从本质上讲,代码的功能是改变数组。好的一方面是运行很快,甚至能和Dask并行处理速度比较。其次,如果使用的是最基本的Numpy和Python,那么就可以及时编译任何函数。坏的一面在于它只适合Numpy和简单Python语法。我不得不把所有的数值计算从我的函数转换成子函数,但其计算速度会增加得非常快。
将其一起使用
简单地使用map_partition()就可以将Numba函数与Dask结合在一起,如果并行操作和broadcasting能够密切合作以加快运行速度,那么对于大数据集而言,将会看到其运行速度得到大幅提升。
09e60c6e34586f4760449a2159928877d49958cf
d9d0d60dc749ba864cbb200bb05b60e71ff6adcf
上面的第一张图表明,没有broadcasting的线性计算其表现不佳,并行处理和Dask对速度提升也有效果。此外,可以明显地发现,Dask和Numba组合的性能优于其它方法。
上面的第二张图稍微有些复杂,其横坐标是对行数取对数。从第二张图可以发现,对于1k到10k这样小的数据集,单独使用Numba的性能要比联合使用Numba+Dask的性能更好,尽管在大数据集上Numba+Dask的性能非常好。
优化
为了能够使用Numba编译JIT,我重写了函数以更好地利用broadcasting。之后,重新运行这些函数后发现,平均而言,对于相同的代码,JIT的执行速度大约快了24%。
c9f6a34759b5b1298033c2e4ffd5d78a63994af5
可以肯定的说,一定有进一步的优化方法使得执行速度更快,但目前没有发现。Dask是一个非常友好的工具,本文使用Dask+Numba实现的最好成果是提升运行速度60倍。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









