









Page 121~Page 123
比较好的推文可以参考这篇,讲的比西瓜书详细
关于svm的推导不准备赘述了,这里只注重结论,
超平面 wTx+ b = 0
对于线性可分的情况,超平面其实是我们需要求的东西
支持向量 就是离超平面最近的向量,可以是一个可以是多个
根据相关公式推导:最终要求的最优的超平面其实只要优化
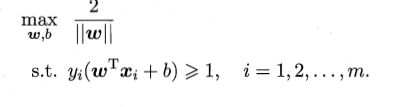
凸函数: 对于一元函数f(x),我们可以通过其二阶导数f″(x) 的符号来判断。如果函数的二阶导数总是非负,即f″(x)≥0 ,则f(x)是凸函数对于多元函数f(x),我们可以通过其Hessian矩阵(Hessian矩阵是由多元函数的二阶导数组成的方阵)的正定性来判断。如果Hessian矩阵是半正定矩阵,则是f(x)凸函数, 凸函数是强对偶函数。
SVM步骤:
- 构造拉格朗日函数
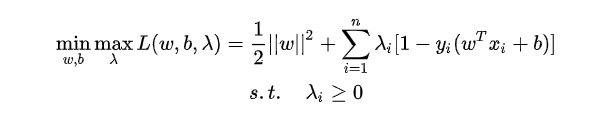
- 通过强对偶性转化:先求最小化 w,b带入原式中,
a:转化
原来的最小最大问题可以转化为最大最小问题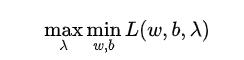
b:求偏导,带入原函数
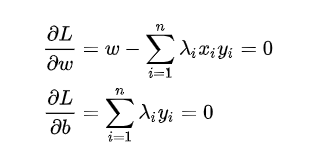
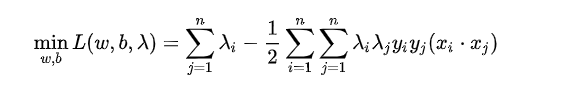
- SMO算法求解
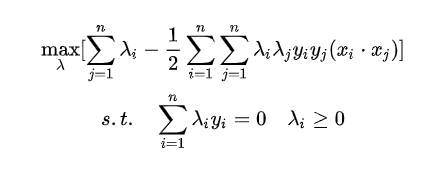
SMO(Sequential Minimal Optimization),序列最小优化算法,其核心思想非常简单:每次只优化一个参数,其他参数先固定住,仅求当前这个优化参数的极值。我们来看一下 SMO 算法在 SVM 中的应用。
多次迭代求解出 λ \lambda λi, - 带入2中解出w,b
- 建立超平面使用决策函数sign(.)分类
? 如果遇到了不能够完全线性可分的样本
采用软间隔,
多引入一项
ϵ
\epsilon
ϵ,然后重走上述过程,其中优化函数多加一向做正则化
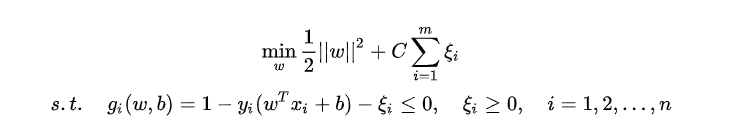
非线性分类的SVM
将当前维线性不可分样本映射到更高维空间中,让样本点在高维空间线性可分,我们用 x 表示原来的样本点,用f(x) 表示 x 映射到特征新的特征空间后到新向量。那么分割超平面可以表示为:
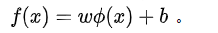
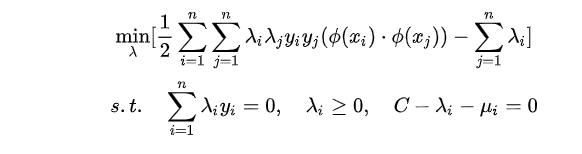
只有一定不同,原来是两个向量乘,现在变成两个向量的映射乘,

? 为什么要使用核函数而不是直接扩充维度
核函数的引入一方面减少了我们计算量,另一方面也减少了我们存储数据的内存使用量。















 287
287











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









