







上一期讲了Lambda架构,对于实时数仓而言,Lmabda架构有很明显的不足,首先同时维护两套系统,资源占用率高,其次这两套系统的数据处理逻辑相同,代码重复开发。
能否有一种架构,只需要维护一套系统,就可以同时完成流处理、批处理任务呢?当然,那就是Kappa架构。
Kappa架构
Kappa架构是真正意义上的流批一体的处理方式。它是随着流处理引擎的逐步完善后,由LinkedIn公司提出的一种实时数仓架构。
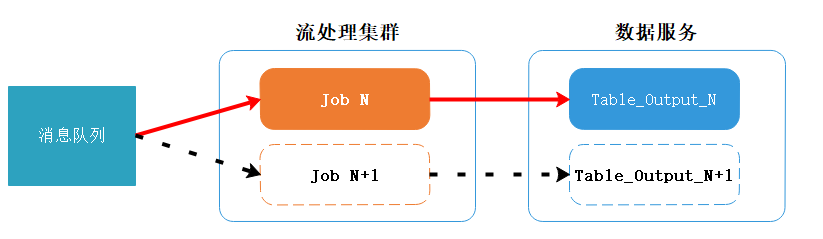
这种架构,相当于在Lambda架构上去掉了批处理层(Batch Layer),只留下单独的流处理层(Speed Layer)。通过消息队列的数据保留功能,来实现上游重放(回溯)能力。
当流任务发生代码变动时,或者需要回溯计算时,原先的Job N保持不动,先新启动一个作业Job N+1,从消息队列中获取历史数据,进行计算,计算结果存储到新的数据表中。
当计算进度赶上之前的Job N时,Job N+1替换Job N,成为最新的流处理任务。然后程序直接读取新的数据表,停止历史作业Job N,并删除旧的数据表。
当然这种架构可以进行优化,将两张输出表合并为一张,减少运维部分的工作。
与Lambda架构相比,这种架构在吞吐和性能上要低于Lambda架构,因为Lambda架构的批处理是整个吞吐与性能的核心部分。但Kappa统一了数据处理架构,减少了计算资源的浪费,降低了运维成本。而且使得代码只需要编写和维护一次,但Kappa无法解决流处理和批处理在部分处理逻辑不一致的情况。
技术选型
Kappa架构在选型上,消息队列常选择Kafka,因为它具有历史数据保存、重放的功能,并支持多消费者。而流处理集群,一般选择Flink,因为Flink支持流批一体的处理方式,并且对SQL的支持率逐渐提高,所以可以尽量减少流处理和批处理逻辑代码不一致的情况。
对于数据服务,依然是需要实时读写的数据库产品,常见的有HBase、Druid、ClickHouse等。
注意事项
但使用Kafka作为消息队列时要注意,Kafka因为消息是先存储到内存中,然后再落盘,所以可能会存在数据丢失的情况发生。如果需要金融级别的数据可靠性,使用Rabbit MQ或者Rocket MQ这种支持数据直接持久化到磁盘中的消息队列,可能是更好的选择,但相应的会牺牲数据实时性和吞吐量。
Kappa架构和Lambda架构,并没有优劣之分,只是适用场景不同而已。
流式数据模型
架构设计
数据模型设计是贯穿数据处理过程的,在实时流式数据处理中也一样。实时建模与离线建模类似,数据模型整体上分为5层(ODS、DWD、DWS、ADS、DIM)。

其中ODS数据属于操作数据层,是直接从业务系统采集来的原始数据。在这一层上,数据与离线系统是一致的。
ODS层实时进入的数据,会进行去重、清洗等任务,适度做一些维度退化工作,清洗后的数据会存放到DWD层中,DWD数据明细层的数据会回流到消息队列中,从而实时同步到下游实时任务中,同时会持久化到数据库中供离线系统使用。
一般而言,ODS和DWD层会尽可能保持与离线系统共用。
DWD层实时推送来的数据,被订阅后,汇总计算各个维度的通用指标,存储到DWS数据汇总层中,作为通用的数据模型进行使用。如果是特定业务系统的维度指标,则订阅DWD层的数据,计算后存储到ADS层中。所以DWS和ADS的区别是:是否是业务通用指标。DWS、ADS层数据会存储到实时读写的数据库系统中,供前端业务进行实时访问。
DWS、ADS的数据表类型和离线系统一样,分为事实表和维度表。但在进行指标计算时,事实数据实时进行订阅,使用到的维度表数据不会进行实时更新获取,而使用的是T-2的离线数据。且维度表数据会存储在DIM层中,在计算时进行获取。
首先是因为维度数据变化比较缓慢,其次如果维度也进行实时更新,那么当天计算出来的数据一致性就会出现问题,比如2点前的计算结果是维度未更新时的结果,2点后的计算结果是维度更新后的结果。
所以维度数据,会由离线系统定期从ODS中获取数据,计算后存放在DIM层中。那为什么维度数据的延迟为T-2?虽然最好情况是使用T-1的数据,即昨天的数据进行计算。但T-1的数据,是在0点之后通过ETL抽取到离线系统进行计算,而计算过程需要一段时间,假设凌晨2点计算完成,那2点之前的实时数据在计算时,使用的依然是T-2的旧维度数据。
所以为了保证数据一致性,T-1的维度数据虽然已经完成了计算,但不会直接使用,而是继续沿用T-2的维度数据。
数据流向
ODS、DWD层的数据会存放在消息中间件中,如Kafka。而DWD层数据在计算完成后,一般还会将数据推送到离线系统中,尽可能与离线系统实现共用。这里的计算流向是:Kafka作为ODS层,存储实时数据;实时流计算任务从ODS获取数据进行计算,计算结果作为DWD层数据,写入到Kafka中存储,供下游实时计算,并且为了与离线系统保持一致,也会推送到离线系统中进行存储。
下游的实时流计算任务,从Kafka中获取到DWD层数据后,DWS、ADS计算任务会同时开始,维度通用指标结果作为DWS层数据存放到实时读写数据库系统中,如HBase、Druid、ClickHouse等,而特定系统的维度指标结果作为ADS层数据,同样存储到实时读写的数据库系统中。
至于DIM层的数据,则由离线ETL系统定期进行计算。
对于这几层的划分,在不同业务场景中可能会做不同调整,但原理相同,大家灵活应对即可。
后话
如果有帮助的,记得点赞、关注。在公众号《数舟》中,可以免费获取专栏《数据仓库》配套的视频课程、大数据集群自动安装脚本,并获取进群交流的途径。
我所有的大数据技术内容也会优先发布到公众号中。如果对某些大数据技术有兴趣,但没有充足的时间,在群里提出,我为大家安排分享。
公众号自取:



















 485
485

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











