







1. 指数加权平均
指数加权平均是深度学习众多优化算法的理论基础,包括Momentum、RMSprop、Adam等,在介绍这些优化算法前,有必要对指数加权平均(exponentially weighted averages)做一个简单的介绍,以期对后续的优化算法的原理有所知晓。
何为指数加权平均那?
现在想求一段时间内的平均温度,给定一段时间的温度序列 ,加和平均结果为 ,每天温度的权重都是相同的。进一步,若要根据平均气温预测明天的温度,显然昨天的温度应该较30天之前的温度权重大一些,因为越早的日期对于预测明天温度所起到的作用越小,这符合我们的常规思维,因此给予每天的温度不同的权重,这就引出了统计学中常用的一种平均方法——指数加权平均,平均温度预测的指数加权平均形式如下:

可以看到,随着日期的向后推移,温度的权重以单位 进行衰减。 当
为 0 时,平均气温的计算完全忽略历史信息,随着
由 0 到 1 不断增大,历史温度的权重衰减速度不断降低。
在吴恩达的深度学习课程中,英国每日温度以及每日温度的指数加权平均示意图如下:
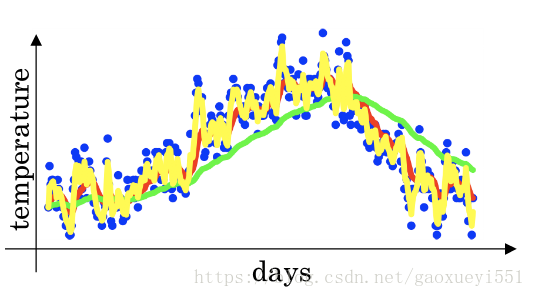
图 1 β 为0.98(绿线),0.9(红线)和0.02(黄线)时的指数加权平均值
从上图分析可得,当 β 为 0.98 时,指数加权平均减慢了对历史温度的衰减,因而纳入了更多的历史温度信息,导致绿线在上升阶段的值小于红线,且最高点滞后于红线;当 β 为 0.9 时,似乎时根据历史温度预测明天温度的最恰当的取值;当 β 为 0.02时,历史温度信息几乎没有纳入指数加权平均的计算中,更注重最近几天的温度。随着 β 值的不断减小,指数加权平均线的平滑度在不断下降(时效性增强)。
2. 指数加权平均的偏差修正
实际上,在图2中,当 β 取0.98时,得到的曲线并非绿色,而是下图的紫色曲线: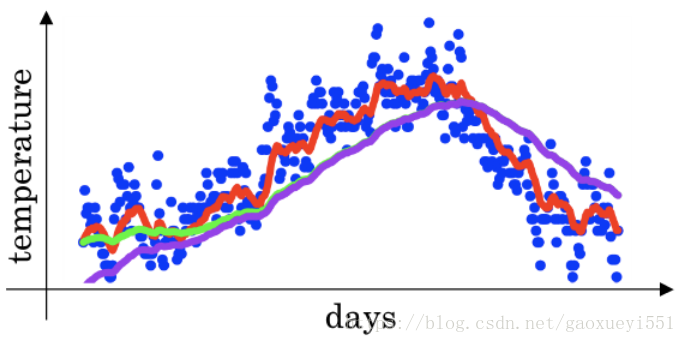
图 2 β 为0.98的实际曲线(紫线)
紫色曲线的值在开始上升的初始阶段明显小于绿色曲线,这是什么原因那? 通过指数加权的递推公式可以发现,最初几天的温度预测值不足历史温度的0.02,因而在预测前期会有一定的偏差。因此,引入偏差修正公式如下:
通过此修正公式,开始几天的平均温度预测值可以接近实际值,随着 的增大,偏差修正公式会逐渐还原为修正之前的指数加权平均公式。
在基于指数加权平均的深度学习优化算法中, 如果你对初期的偏差修正比较重视,则可采用修正的指数加权平均公式,如果对初期的偏差修正不是特别在意,可以选择马虎的度过初始阶段。总之,如果你关心初始时期的偏差,修正偏差能帮助你在早期获得更好的估测。
tensorflow中提供了tf.train.ExponentialMovingAverage来实现滑动平均模型,他使用指数衰减来计算变量的移动平均值。
tf.train.ExponentialMovingAverage.__init__(self, decay, num_updates=None, zero_debias=False, name="ExponentialMovingAverage"):
decay是衰减率
num_updates是ExponentialMovingAverage提供用来动态设置decay的参数,当初始化时提供了参数,即不为none时,每次的衰减率是:
min { decay , ( 1 + num_updates ) / ( 10 + num_updates ) }
apply()方法添加了训练变量的影子副本,并保持了其影子副本中训练变量的移动平均值操作。在每次训练之后调用此操作,更新移动平均值。
average()和average_name()方法可以获取影子变量及其名称。
在创建ExponentialMovingAverage对象时,需指定衰减率(decay),用于控制模型的更新速度。影子变量的初始值与训练变量的初始值相同。当运行变量更新时,每个影子变量都会更新为:
shadow_variable = decay * shadow_variable + (1 - decay) * variable
滑动平均的原理理解
# -*- coding: utf-8 -*-
"""
@author: tz_zs
滑动平均模型
"""
import tensorflow as tf
# 定义一个变量,用于滑动平均计算、
v1 = tf.Variable(0, dtype=tf.float32)
# 定义一个变量step,表示迭代的轮数,用于动态控制衰减率
step = tf.Variable(0, trainable=False)
# 定义滑动平均的对象
ema = tf.train.ExponentialMovingAverage(0.99, step)
# 定义执行保持滑动平均的操作, 参数为一个列表格式
maintain_average_op = ema.apply([v1])
with tf.Session() as sess:
# 初始化所有变量
init_op = tf.global_variables_initializer()
sess.run(init_op)
# 通过ema.average(v1)获取滑动平均之后变量的取值,
# print(sess.run(v1)) # 0.0
# print(sess.run([ema.average_name(v1), ema.average(v1)])) # [None, 0.0]
print(sess.run([v1, ema.average(v1)])) # [0.0, 0.0]
# 更新变量v1的值为5
sess.run(tf.assign(v1, 5))
# 更新v1的滑动平均值,衰减率 min { decay , ( 1 + num_updates ) / ( 10 + num_updates ) }=0.1
# 所以v1的滑动平均会被更新为 0.1*0 + 0.9*5 = 4.5
sess.run(maintain_average_op)
# print(sess.run(v1)) # 5.0
# print(sess.run([ema.average_name(v1), ema.average(v1)])) # [None, 4.5]
print(sess.run([v1, ema.average(v1)])) # [5.0, 4.5]
# 更新step的值为10000。模拟迭代轮数
sess.run(tf.assign(step, 10000))
# 跟新v1的值为10
sess.run(tf.assign(v1, 10))
# 更新v1的滑动平均值。衰减率为 min { decay , ( 1 + num_updates ) / ( 10 + num_updates ) }得到 0.99
# 所以v1的滑动平均值会被更新为 0.99*4.5 + 0.01*10 = 4.555
sess.run(maintain_average_op)
print(sess.run([v1, ema.average(v1)])) # [10.0, 4.5549998]
# 再次更新滑动平均值,将得到 0.99*4.555 + 0.01*10 =4.60945
sess.run(maintain_average_op)
print(sess.run([v1, ema.average(v1)])) # [10.0, 4.6094499]
————————————————
# -*- coding: utf-8 -*-
"""
@author: tz_zs
"""
import tensorflow as tf
v1 = tf.Variable(10, dtype=tf.float32, name="v")
for variables in tf.global_variables(): # all_variables弃用了
print(variables) # <tf.Variable 'v:0' shape=() dtype=float32_ref>
ema = tf.train.ExponentialMovingAverage(0.99)
print(ema) # <tensorflow.python.training.moving_averages.ExponentialMovingAverage object at 0x00000218AE5720F0>
maintain_averages_op = ema.apply(tf.global_variables())
for variables in tf.global_variables():
print(variables) # <tf.Variable 'v:0' shape=() dtype=float32_ref>
# <tf.Variable 'v/ExponentialMovingAverage:0' shape=() dtype=float32_ref>
with tf.Session() as sess:
tf.global_variables_initializer().run()
sess.run(tf.assign(v1, 1))
sess.run(maintain_averages_op)
————————————————
# -*- coding: utf-8 -*-
"""
滑动平均值的存储和加载(持久化)
"""
import tensorflow as tf
v1 = tf.Variable(10, dtype=tf.float32, name="v1")
for variables in tf.global_variables(): # all_variables弃用了
print(variables) # <tf.Variable 'v1:0' shape=() dtype=float32_ref>
ema = tf.train.ExponentialMovingAverage(0.99)
print(ema) # <tensorflow.python.training.moving_averages.ExponentialMovingAverage object at 0x00000218AE5720F0>
maintain_averages_op = ema.apply(tf.global_variables())
for variables in tf.global_variables():
print(variables) # <tf.Variable 'v1:0' shape=() dtype=float32_ref>
# <tf.Variable 'v1/ExponentialMovingAverage:0' shape=() dtype=float32_ref>
saver = tf.train.Saver()
print(saver) # <tensorflow.python.training.saver.Saver object at 0x0000026B7E591940>
with tf.Session() as sess:
tf.global_variables_initializer().run()
sess.run(tf.assign(v1, 1))
sess.run(maintain_averages_op)
print(sess.run([v1, ema.average(v1)])) # [1.0, 9.9099998]
print(saver.save(sess, "/path/to/model.ckpt")) # 持久化存储____会返回路径 /path/to/model.ckpt
#################################################################################################
print("#####" * 10)
print("加载")
#################################################################################################
var2 = tf.Variable(0, dtype=tf.float32, name="v2") # <tf.Variable 'v2:0' shape=() dtype=float32_ref>
print(var2)
saver2 = tf.train.Saver({"v1/ExponentialMovingAverage": var2})
with tf.Session() as sess2:
saver2.restore(sess2, "/path/to/model.ckpt")
print(sess2.run(var2)) # 9.91 所以,成功加载了v1的滑动平均值
————————————————
附录2:移动平均法相关知识(转)
来源地址:http://wiki.mbalib.com/wiki/%E7%A7%BB%E5%8A%A8%E5%B9%B3%E5%9D%87%E6%B3%95
移动平均法又称滑动平均法、滑动平均模型法(Moving average,MA)
什么是移动平均法?
移动平均法是用一组最近的实际数据值来预测未来一期或几期内公司产品的需求量、公司产能等的一种常用方法。移动平均法适用于即期预测。当产品需求既不快速增长也不快速下降,且不存在季节性因素时,移动平均法能有效地消除预测中的随机波动,是非常有用的。移动平均法根据预测时使用的各元素的权重不同
移动平均法是一种简单平滑预测技术,它的基本思想是:根据时间序列资料、逐项推移,依次计算包含一定项数的序时平均值,以反映长期趋势的方法。因此,当时间序列的数值由于受周期变动和随机波动的影响,起伏较大,不易显示出事件的发展趋势时,使用移动平均法可以消除这些因素的影响,显示出事件的发展方向与趋势(即趋势线),然后依趋势线分析预测序列的长期趋势。
移动平均法的种类
移动平均法可以分为:简单移动平均和 加权移动平均 。
一、简单移动平均法
简单移动平均的各元素的权重都相等。简单的移动平均的计算公式如下: Ft =( At-1 + At-2 + At-3 + … + At-n ) /n 式中,
· Ft-- 对下一期的预测值;
· n-- 移动平均的时期个数;
· At-1-- 前期实际值;
· At-2 , At-3 和 At-n 分别表示前两期、前三期直至前 n 期的实际值。
二、加权移动平均法
加权移动平均 给固定跨越期限内的每个变量值以不同的权重。其原理是:历史各期产品需求的数据信息对预测未来期内的需求量的作用是不一样的。除了以 n 为周期的周期性变化外,远离目标期的变量值的影响力相对较低,故应给予较低的权重。 加权移动平均法 的计算公式如下:
Ft = w1At-1 + w2At-2 + w3At-3 + … + wnAt-n 式中,
· w1-- 第 t-1 期实际销售额的权重;
· w2-- 第 t-2 期实际销售额的权重;
· wn-- 第 t-n 期实际销售额的权
· n-- 预测的时期数; w1 + w2 + … + wn = 1
在运用加权平均法时,权重的选择是一个应该注意的问题。经验法和试算法是选择权重的最简单的方法。一般而言,最近期的数据最能预示未来的情况,因而权重应大些。例如,根据前一个月的利润和生产能力比起根据前几个月能更好的估测下个月的利润和生产能力。但是,如果数据是季节性的,则权重也应是季节性的。
移动平均法的优缺点
使用移动平均法进行预测能平滑掉需求的突然波动对预测结果的影响。但移动平均法运用时也存在着如下问题:
1 、 加大移动平均法的期数(即加大 n 值)会使平滑波动效果更好,但会使预测值对数据实际变动更不敏感;
2 、 移动平均值并不能总是很好地反映出趋势。由于是平均值,预测值总是停留在过去的水平上而无法预计会导致将来更高或更低的波动;
3 、 移动平均法要由大量的过去数据的记录。

















 4248
4248

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









