







【论文】TOWARDS FASTER AND BETTER FEDERATED LEARNING A FEATURE FUSION APPROACH阅读笔记
TOWARDS FASTER AND BETTER FEDERATED LEARNING: A FEATURE FUSION APPROACH
Abstract
本文主要提出一种特征融合的方式,来加速并且提升联邦学习的性能。
Introduction
如今许多智能设备依赖于预训练模型,这使得机器的推断能力缺乏个性化和灵活性。与此同时,智能终端同时还产生了大量有效的隐私数据,这些数据能够提升这些模型的个性化能力。联邦学习,一种能够直接在终端上对模型进行训练的一种分布式训练算法解决了这个问题。其中以FedAvg算法为代表的的联邦学习算法有效的缓解了在信息交流上的隐私问题,但是后来也有研究表明,联邦学习仍然存在诸如:计算消耗,模型准确率。
本文提出了一种融合特征的联邦学习算法FedFusion,该算法将global模型和local模型的特征进行融合。本文的主要的三个贡献点:1. 引入特征融合机制 2. 将本地模型和全局模型的特征以一种有效的并且个性化的方式进行融合 3. 实验表明模型在准确率和泛化能力上都优于baseline并且减少了60%以上的通信量。
Related Work
主要就是Federated Learning的FedAVG算法,不多赘述
Methods
主要分为特征融合模块和FedFusion算法
Feature Fusion Modules
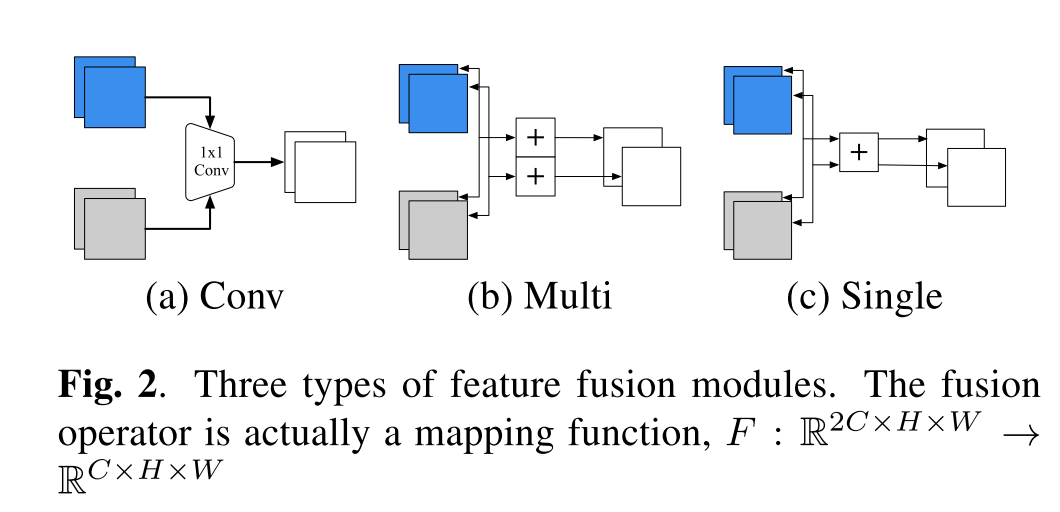
图中的蓝色特征是local模型提取的两通道特征,灰色的是global模型提取的两通道特征。图中表示了三种特征融合的方式:Conv, Multi, Single。
Conv:

其中 表示shape 为2C*C的可学习的权重矩阵。具体操作就是将global特征和local特征进行concat后进行卷积操作。
Multi:
乘法操作就是用一个lambda权重矩阵来对local和global进行一个加权求和。
Single:
加法操作是用一个标量lambda权重来对local和global进行一个加权求和。
FedFusion
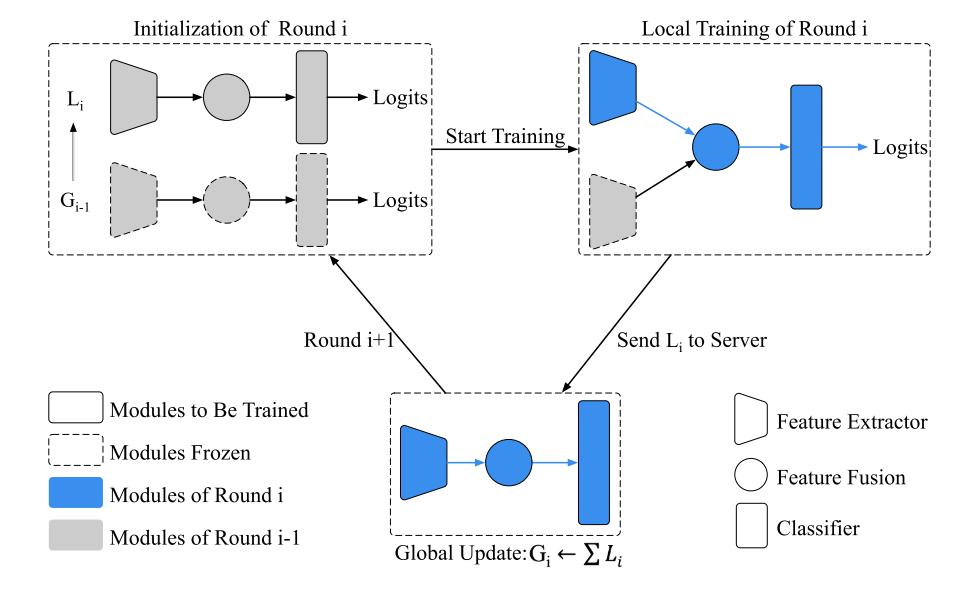
训练流程就是利用上一轮的global模型的特征来参与本轮的模型特征聚合训练。
Experiment
Experiment setup
数据集: Mnist, Cifar10
数据分割方式:
- 人工的noniid分割方式,每个节点仅包含两种类别
- 用户分割的noniid方式,每个节点包含相似的类别,但是采用不同的分布,类似multi task学习
- IID分布
Artificial Non-IID Partition
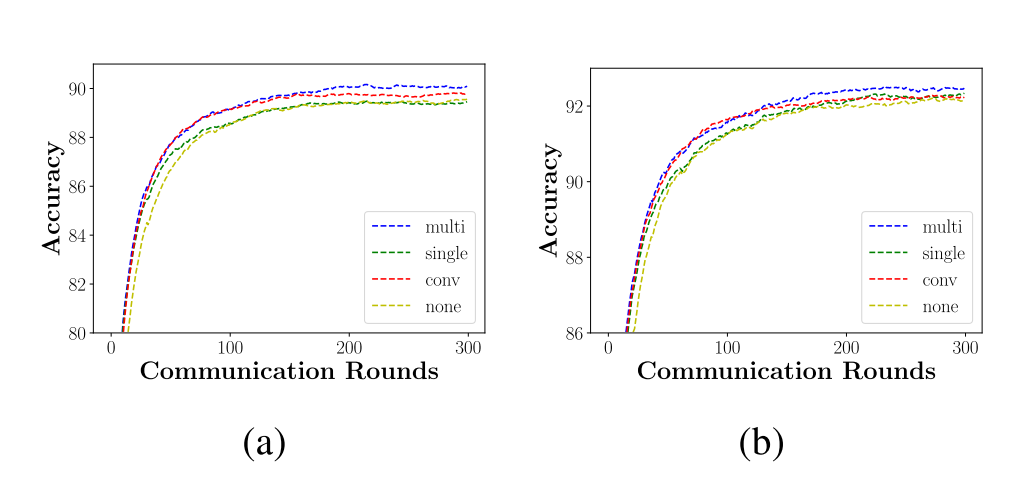
两次随机的人工noniid采样方式的实验结果。实验结果表明,multi操作的融合方式效果最好,conv融合方式收敛相对快一点点,但是最后效果不如multi,none和single都很一般。
论文的解释是,multi操作可以让模型选择对本地数据有效的feature maps进行融合。而single操作是标量,不能对featuremap的特定某些channel进行选择。
User-Specific Non-IID Partition
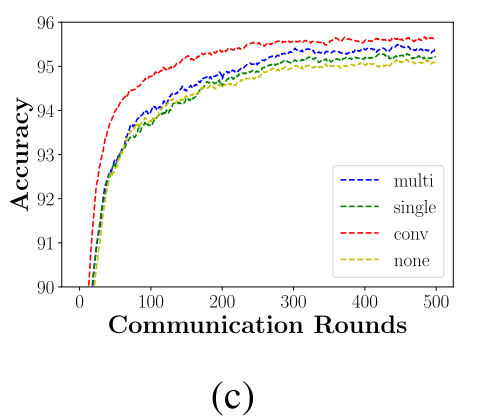
在准确率方面,fedfusion比fedavg更很高,其中conv的收敛速度更快准确率也更高。
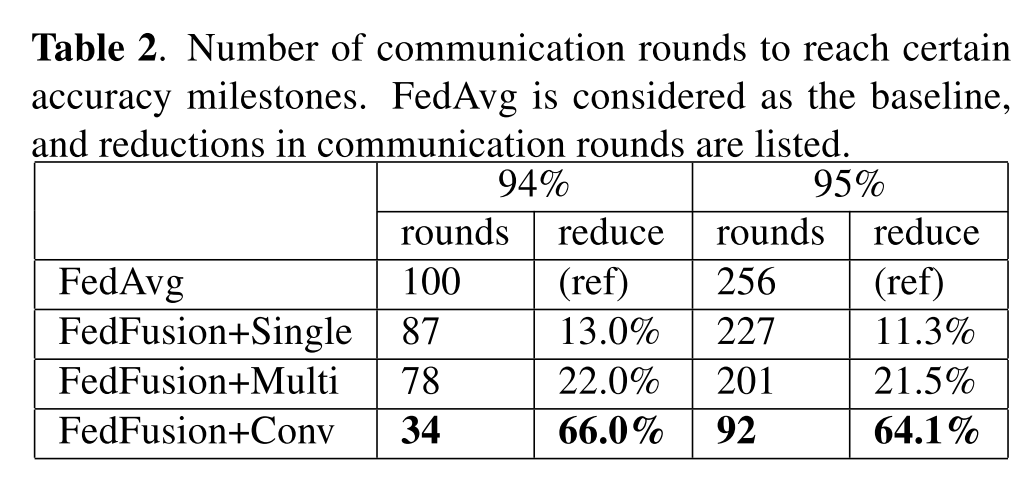
上图展示了FedAvg 和FedFusion在通信量上的减少程度。从结果上来看,在User specific这种noniid场景下,conv的融合方式效果更好。这是因为,在user specific这种noniid模式下,数据的类别是相似的,只是采用了不同的分布。而conv的融合方式拥有更强的整合来自local和global模型的feature map。也就是说不同节点之间的数据分布的知识。
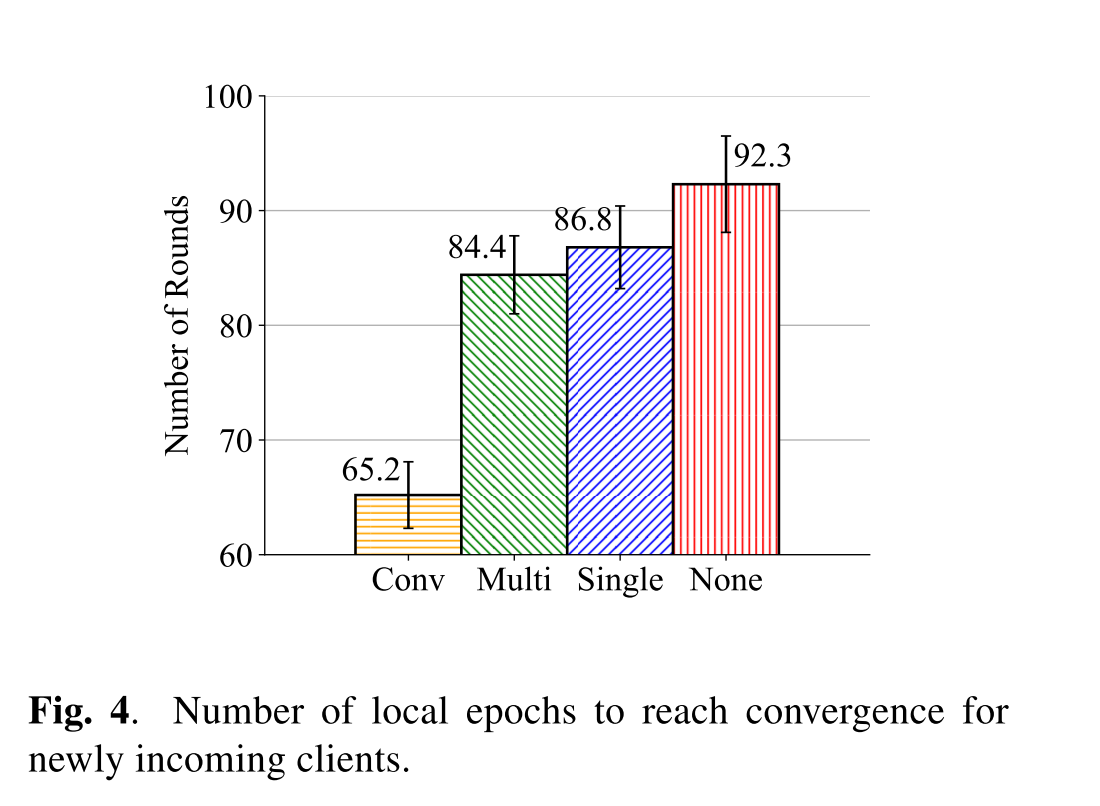
对于泛化能力的影响,当有新的节点加入的时候,Fedfusion只需要60多个local epoch就能达到拟合,拥有相比于其他几种方式更好的初始化。
IID Partition
作者认为IID的分布也需要进行评估,因为如果不能处理IID分布的策略,其有效性是值得怀疑的。
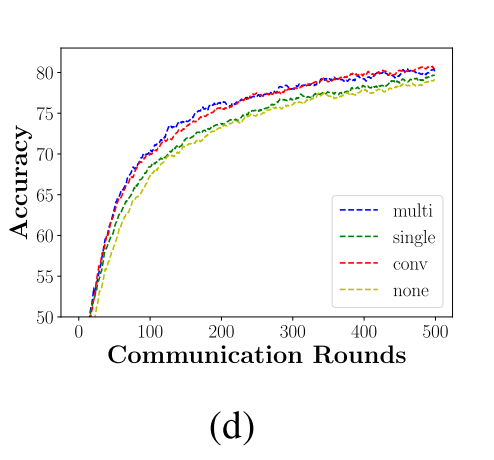
采用multi和conv的融合方式可以在最少的通信消耗情况下达到更好的准确率。就最终的收敛的准确率而言,相比其他的方式有很多提升。
关于三种融合方式做个总结:
multi操作,主要是对local的feature map和global的feature map做出了更灵活的选择,并且更可解释。权重向量的每个channel代表着global feature map对应channel的权重。当数据的类别之间出现gap,multi操作可以选择最有效的feature map进行融合。conv 操作在整合global和local模型的知识上更有效。如果节点上的数据拥有相似的类别,只是不同的分布的话,conv融合方式会更好。single融合方式有微小的提升。
Conclusion
利用feature map的融合,减少了通信量,同时增加了模型效果,同时还提升了新节点的泛化能力。

















 1493
1493

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









