







基于BP神经网络的深度非负矩阵分解用于图像聚类。
摘要
深度非负矩阵分解(DNMF)是一种用于非负多层特征提取的有前途的方法。大多数DNMF算法都是通过反复运行单层NMF来构建分层结构。它们必须通过微调策略消除累积误差,然而这样做非常耗时。为了解决现有DNMF算法的缺点,本文提出了一种基于反向传播神经网络(BPNN)的新颖深度自编码器。它可以自动产生一个称为BPNN基于DNMF(BP-DNMF)的深度非负矩阵分解。实验证明,所提出的BP-DNMF算法在收敛性上表现出色。与一些最先进的DNMF算法相比,实验结果表明我们的方法在聚类性能上具有优越性,并且计算效率也很高。
介绍
非负矩阵分解(NMF)旨在找到两个因子W和H,使得 X ≈ W H X ≈ WH X≈WH,其中 X X X 是图像数据矩阵, W W W 和 H H H 是非负矩阵,分别称为基图像矩阵和特征矩阵。NMF可以学习基于部分的图像数据表示,并展现了处理分类和聚类任务的能力。然而,NMF及其变种仅仅是单层分解方法,因此无法揭示数据的底层分层特征结构。深度学习中的实证结果表明,基于多层特征的方法优于基于浅层的学习方法。因此,一些研究人员提出了基于单层NMF算法的深度NMF模型。Cichocki等人提出了一种用于盲源分离的多层NMF算法。他们采用了单层稀疏NMF来生成深度NMF结构,迭代规则为 H i ≈ W i H i − 1 , i = 1 , 2 , . . . , L H_i ≈ W_iH_{i-1},i = 1,2,...,L Hi≈WiHi−1,i=1,2,...,L,其中 H 0 = X H_0 = X H0=X。最终的分解形式为 X ≈ W 1 W 2 . . . W L H L X ≈ W_1W_2...W_LH_L X≈W1W2...WLHL。但是该DNMF算法存在较大的重构误差,且其性能受到负面影响。最近,一些改进的DNMF方案采用了精调技术。例如,Lyu等人将单层正交NMF扩展为深层结构。他们的更新规则为 W i ≈ W i H i , i = 1 , 2 , . . . , L W_i ≈ W_iH_i,i = 1,2,...,L Wi≈WiHi,i=1,2,...,L,其中 W 0 = X W_0 = X W0=X。最终的深度分解形式为 X ≈ W 1 H 1 H 2 . . . H L X ≈ W_1H_1H_2...H_L X≈W1H1H2...HL。这种正交DNMF方法使用精调步骤来减小分解的总误差,并在面部图像聚类中显示出有效性。Trigeorgis等人提出了一种半DNMF模型,其深层分解形式为 X ≈ W 1 ± W 2 ± . . . W L ± H L ± X ≈ W_1^\pm W_2^\pm ...W_L^\pm H_L^\pm X≈W1±W2±...WL±HL±,其中 ± \pm ± 表示矩阵的元素没有限制, ′ + ′ '+' ′+′ 表示矩阵是非负的。半DNMF模型也通过两个阶段解决,即预训练和精调,并且可以学习面部图像的隐藏表示以进行聚类和分类。类似的深度NMF模型已经被提出用于高光谱解混、人脸图像聚类等。可以看出,大多数DNMF方法需要使用精调策略来减小模型的整体重构误差。然而,这会导致计算复杂度高。此外,现有的DNMF算法中没有利用深度神经网络(DNN)获得分层特征结构的优势,也无法充分利用DNN在聚类中的优势。
为了解决基于单层NMF的DNMF方法的问题,本文提出了一种基于反向传播神经网络(BPNN)的新型DNMF方法(BP-DNMF)。我们利用标记的原始图像数据上的RBF来获得一个分块对角相似矩阵,该矩阵用作BPNN的输入。同时,原始数据被设置为网络的目标输出。我们的模型可以被看作是一个深度自编码器。特别地,我们的自编码器自动产生了一个具有深层分层结构的DNMF,用于图像数据表示。所提出的BP-DNMF方法具有很高的计算效率,因为它直接避免了精调步骤。在面部图像上的实验表明,我们的BP-DNMF算法具有快速的收敛速度。最后,在面部图像聚类的评估结果表明,我们的方法取得了竞争性的性能。
深度NMF的框架
本节将简要介绍深度NMF模型的框架。大多数DNMF算法通过递归利用某些单层NMF生成层次特征结构,并得到以下深度分解:

初始分解(1)被称为预训练阶段,然而由于累积误差,它具有较大的重构误差。因此,有必要通过精调策略减小DNMF模型的整体误差。具体而言,通过微调前一阶段获得的所有矩阵,以最小化以下目标函数:
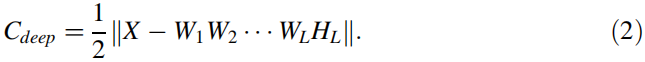
采用梯度下降法得出了微调阶段的更新规则,如下图所示:
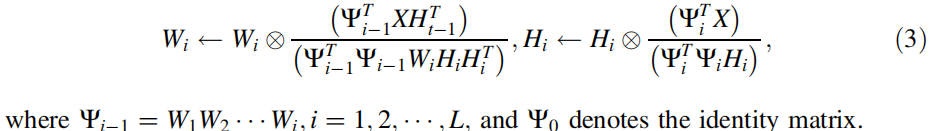
提出的BP-DNMF方法
本节将介绍基于BP神经网络的自编码器。所提出的自编码器能够在图像数据上自动创建一个深度的非负矩阵分解,从而避免了精调阶段的高计算复杂度。最终,所提出的BP-DNMF方法被应用于分层特征提取和图像聚类。
3.1 自编码器
假设
X
=
X
1
,
X
2
,
.
.
.
,
X
c
X = X_1, X_2, ... , X_c
X=X1,X2,...,Xc 是训练数据矩阵,其中
X
i
X_i
Xi 是第
i
i
i 类的数据矩阵,c 是类别数,总数据数量为
n
=
Σ
i
=
1
c
n
i
n = Σ^c_{i=1} n_i
n=Σi=1cni,其中
n
i
n_i
ni 是第
i
i
i 类的数据数量。所提出的自编码器由两部分组成:从数据到相似性矩阵和从相似性矩阵到数据。
数据 X 到相似性矩阵 H:我们利用径向基函数(RBF)在训练数据上生成一个块对角相似性矩阵 H。相似性矩阵的生成准则是:如果两个数据属于同一类别,它们具有较高的相似性;否则它们的相似性较低。具体而言,相似性矩阵 H = d i a g ( H 1 , H 2 , . . . , H c ) ∈ R m × n H = diag(H_1, H_2, ... , H_c) ∈ R^{m×n} H=diag(H1,H2,...,Hc)∈Rm×n,其中 H i ∈ R n i × n i , i = 1 , . . . , c H_i ∈ R^{n_i×n_i},i = 1, ... , c Hi∈Rni×ni,i=1,...,c。这里 H i H_i Hi 是一个大小为 n i × n i n_i×n_i ni×ni 的矩阵, H s , l i = k ( x s i , x s l ) H_{s,l}^i = k(x_s^i, x_s^l) Hs,li=k(xsi,xsl) 是数据 x i x_i xi 和 x j x_j xj 的相似性, k ( x , y ) = e x p ( − ∣ ∣ x − y ∣ ∣ 2 / t ) k(x, y) = exp(-||x - y||^2/t) k(x,y)=exp(−∣∣x−y∣∣2/t) 是径向基函数, t > 0 t > 0 t>0。可以看出,矩阵 H H H 具有数据 X X X 的良好聚类特征。
相似性矩阵 H H H 到数据 X X X:我们利用输入 H H H 和目标 X X X 建立并优化一个多层 BP 神经网络的结构。BPNN 的结构首先通过设置层数 L L L、每层神经元数量等确定。权重矩阵 W i ( i = 1 , . . . , L ) W_i (i = 1, ... , L) Wi(i=1,...,L) 的初始化遵循标准正态分布 N ( 0 , 1 ) N(0, 1) N(0,1)。激活函数和偏置分别设为 f ( x ) = p 1 / L ⋅ x ( p > 0 ) f(x) = p^{1/L} \cdot x(p>0) f(x)=p1/L⋅x(p>0) 和零。因此,网络的损失函数可以表示为 E = 1 / 2 ∥ X − p ⋅ W L ⋅ W L − 1 . . . ⋅ W 1 H ∥ F 2 E = 1/2 \left \| X - p \cdot W_L \cdot W_{L-1}... \cdot W_1H\right \|^2_F E=1/2∥X−p⋅WL⋅WL−1...⋅W1H∥F2。权重矩阵使用梯度下降法进行更新。我们的 BPNN 的优过程如下所示。
1. 前向传播
- 构建深度神经网络的结构,包括总层数 L L L 和每层中的神经元数量;
- 设置网络的输入和输出目标,分别为 a 0 = H j a_0 = H_j a0=Hj 和 X j ( j = 1 , 2 , . . . , n ) X_j(j=1,2,...,n) Xj(j=1,2,...,n),其中 H j H_j Hj 和 X j X_j Xj 分别是 H H H 和 X X X 的第 j j j 列;
- 初始化权重矩阵 W i ( i = 1 , 2 , . . . , L ) W_i (i = 1, 2, ..., L) Wi(i=1,2,...,L),使其元素符合标准正态分布 N ( 0 , 1 ) N(0, 1) N(0,1),并设置偏置 b i = 0 b_i = 0 bi=0;
- 对于第 i i i 层,计算其输入 z i = W i ⋅ a i − 1 z_i = W_i \cdot a_{i-1} zi=Wi⋅ai−1 和输出 a i = f ( z i ) = p 1 / L ⋅ z i ai = f(zi) = p^{1/L} \cdot z_i ai=f(zi)=p1/L⋅zi,其中 i = 1 , 2 , . . . , L i = 1, 2, ..., L i=1,2,...,L。

3.2 分层特征提取
假设
y
y
y 是一个查询样本,
h
i
h_i
hi 是其在第
i
i
i 层的隐藏特征,其中
i
=
1
,
2
,
.
.
.
,
L
i = 1, 2, ..., L
i=1,2,...,L。那么我们可以通过以下公式计算特征
h
i
h_i
hi:
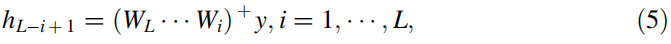
其中, A + A⁺ A+ 表示矩阵 A A A 的伪逆。















 2709
2709











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









