










用MLP代替掉Self-Attention
这次介绍的清华的一个工作 “Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks”
用两个线性层代替掉Self-Attention机制,最终实现了在保持精度的同时实现速度的提升。
这个工作让人意外的是,我们可以使用MLP代替掉Attention机制,这使我们应该重新好好考虑Attention带来的性能提升的本质。
Transformer中的Self-Attention机制
首先,如下图所示:

我们给出其形式化的结果:
A
=
softmax
(
Q
K
T
d
k
)
F
o
u
t
=
A
V
A = \text{softmax}(\frac{QK^T}{\sqrt{d_k}})\\ F_{out} = AV
A=softmax(dkQKT)Fout=AV
其中,
Q
,
K
∈
R
N
×
d
′
Q,K \in \mathbb{R}^{N\times d'}
Q,K∈RN×d′ 同时
V
∈
R
N
×
d
V\in \mathbb{R}^{N\times d}
V∈RN×d
这里,我们给出一个简化版本,如下图所示:
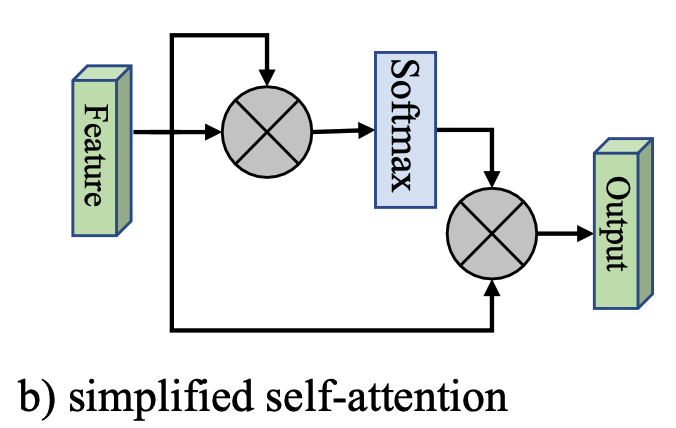
也就是将
Q
,
K
,
V
Q,K,V
Q,K,V 都以输入特征
F
F
F 代替掉,其形式化为:
A
=
softmax
(
F
F
T
)
F
o
u
t
=
A
F
A = \text{softmax}(FF^T)\\ F_{out} = AF
A=softmax(FFT)Fout=AF
然而,这里面的计算复杂度为 O ( d N 2 ) O(dN^2) O(dN2),这是Attention机制的一个较大的缺点。
外部注意力 (External Attention)
如下图所示:

引入了两个矩阵 M k ∈ R S × d M_k\in \mathbb{R}^{S\times d} Mk∈RS×d 以及 $M_v \in\mathbb{R}^{S\times d} $, 代替掉原来的 K , V K,V K,V
这里直接给出其形式化:
A
=
Norm
(
F
M
k
T
)
F
o
u
t
=
A
M
v
A = \text{Norm}(FM_k^T)\\ F_{out} = AM_v
A=Norm(FMkT)Fout=AMv
这种设计,将复杂度降低到
O
(
d
S
N
)
O(dSN)
O(dSN), 该工作发现,当
S
≪
N
S\ll N
S≪N 的时候,仍然能够保持足够的精度。
其中的 Norm ( ⋅ ) \text{Norm}(\cdot) Norm(⋅) 操作是先对列进行Softmax,然后对行进行归一化。
实验分析
首先,文章将Transformer中的Attention机制替换掉,然后在各类任务上进行测试,包括:
- 图像分类
- 语义分割
- 图像生成
- 点云分类
- 点云分割
这里只给出部分结果,简单说明一下替换后的精度损失情况。
图像分类

语义分割

图像生成

可以看到,在不同的任务上,基本上不会有精度损失。















 697
697











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









