










前排提示:个人笔记,不太详细,仅供参考
任务:粗略体素几何体的精细化
输入:粗略(
6
4
3
64^3
643)体素几何体content作为content,精细体素(
25
6
3
256^3
2563)几何体作为style
输出:content的精细化的体素几何体((
6
4
3
64^3
643)),风格上类似给定的style。

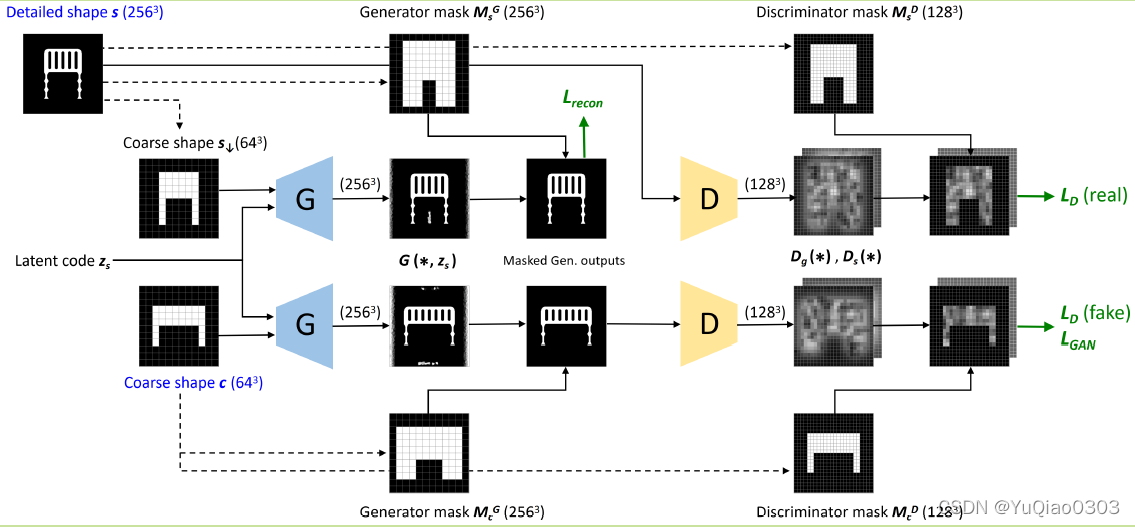
方法概述
一个粗略( 6 4 3 64^3 643)体素几何体content,最近邻上采样得到generator mask。分辨率是256.
generator输入这个content和一个latent code, 输出256的精细几何体。
精细几何体经过generator mask,滤掉一些部分。
过滤的精细几何体,经过discrininator,得到一个不知道是什么的东西。
这个东西施加discrininator mask得到不知道是什么2.
不知道是什么2直接计算Ld
- reconstruction loss 结果像style: 希望如果拿style降采样后的结果通过网络,可以生成style自己。
- Ld (discrininator的loss, discriminatior mask): 希望生成的结果中,原来有内容的体素,现在还是有内容。 用一个discrininator类似于把generator的结果处理了一番。然后判断(降采样后为空的体素,希望在content中也为空)。 (啊这?为啥不直接降采样啊????为啥要discrininator啊????)
- generator mask: 希望原来空白的地方,最后还是空白:不是loss,就是用个mask,在generate之后把空的地方筛掉。
discrininator
目的是惩罚lack of voxels,希望生成的结果中,原来有内容的体素,现在还是有内容。
可能他输出的就是,这个位置对不对,
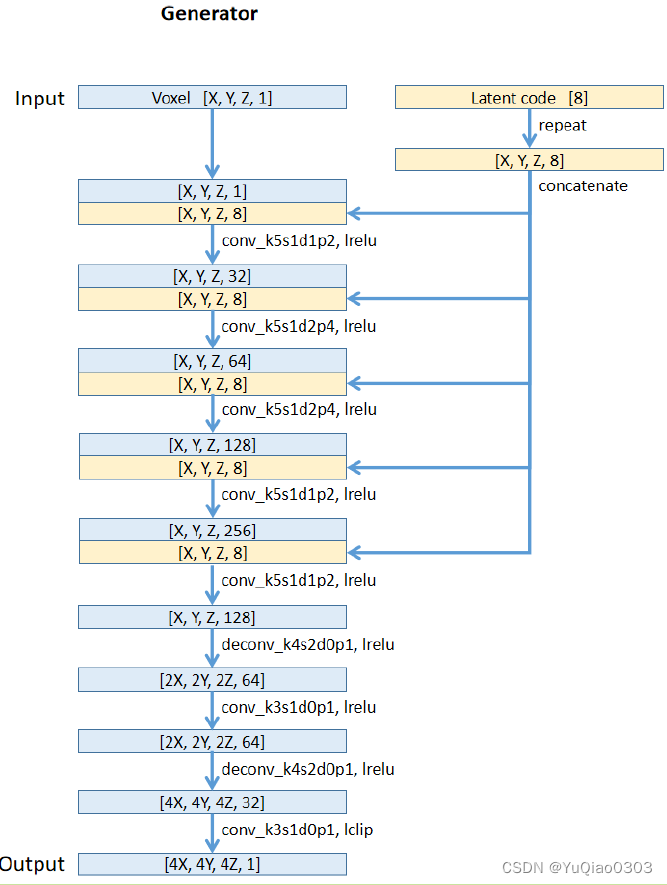
这是作者的supplement文件提供的网络结构图:
输入:体素[X,Y,Z,1] (xyz是长宽高,均为256)
输出:[X/2-8,Y/2-8,Z/2-8,1] (120?,不知道是啥)

这是代码:(modelAE_GD.py)
class discriminator(nn.Module):
def __init__(self, d_dim, z_dim):
super(discriminator, self).__init__()
self.d_dim = d_dim
self.z_dim = z_dim
self.conv_1 = nn.Conv3d(1, self.d_dim, 4, stride=1, padding=0, bias=True) #in_channel, out_channel, kernal size
self.conv_2 = nn.Conv3d(self.d_dim, self.d_dim*2, 3, stride=2, padding=0, bias=True)
self.conv_3 = nn.Conv3d(self.d_dim*2, self.d_dim*4, 3, stride=1, padding=0, bias=True)
self.conv_4 = nn.Conv3d(self.d_dim*4, self.d_dim*8, 3, stride=1, padding=0, bias=True)
self.conv_5 = nn.Conv3d(self.d_dim*8, self.d_dim*16, 3, stride=1, padding=0, bias=True)
self.conv_6 = nn.Conv3d(self.d_dim*16, self.z_dim, 1, stride=1, padding=0, bias=True)
def forward(self, voxels, is_training=False):
out = voxels
out = self.conv_1(out)
out = F.leaky_relu(out, negative_slope=0.02, inplace=True)
out = self.conv_2(out)
out = F.leaky_relu(out, negative_slope=0.02, inplace=True)
out = self.conv_3(out)
out = F.leaky_relu(out, negative_slope=0.02, inplace=True)
out = self.conv_4(out)
out = F.leaky_relu(out, negative_slope=0.02, inplace=True)
out = self.conv_5(out)
out = F.leaky_relu(out, negative_slope=0.02, inplace=True)
out = self.conv_6(out)
out = torch.sigmoid(out)
return out
可以看到,输入的是长宽高为x,y,z, 通道数为1的体素;输出是长宽高分别/2-8, 通道数变为N+1(代码中的z_dim即为N+1)的体素。N是detailed shapes的数量,也就是style的数量。
结合论文和代码,XYZ均为256,所以discrininator输出的长宽高为120,通道数是N+1??N是类别。
说的是这个小区域对不对。
loss在modelAE.py 第455行:
D_out = self.discriminator(voxel_style,is_training=True)
loss_d_real = (torch.sum((D_out[:,z_vector_style_idx:z_vector_style_idx+1]-1)**2 * Dmask_style) + torch.sum((D_out[:,-1:]-1)**2 * Dmask_style))/torch.sum(Dmask_style)
loss_d_real.backward()
D_out = self.discriminator(voxel_fake,is_training=True)
loss_d_fake = (torch.sum((D_out[:,z_vector_style_idx:z_vector_style_idx+1])**2 * Dmask_fake) + torch.sum((D_out[:,-1:])**2 * Dmask_fake))/torch.sum(Dmask_fake)
loss_d_fake.backward()
self.optimizer_d.step()
generator
输入:vosel数据[X,Y,Z,1],latent code[8] (XYZ相当于长宽高)
输出:[4X,4Y,4Z,1]
还挺清楚的,但没看到mask在哪里
loss: 注意,都是二范数
符号定义
C: M coase content shapes
S: N detailed style shapes
z
s
z_s
zs: 某个detailed shape s的latent code
M
D
M^D
MD: binary discrinimator masks
M
G
M^G
MG: binary generator masks
D
g
D_g
Dg: discrininator, 输入的是generator (fake)
D
s
D_s
Ds: discrininator, 输入的是detailed style shapes (real)
Ld: discrininator loss
分为global(fake)和real(style)两支,她俩的区别只有Dg和Ds的区别。(这个在Preventing mode collapse里面解释)
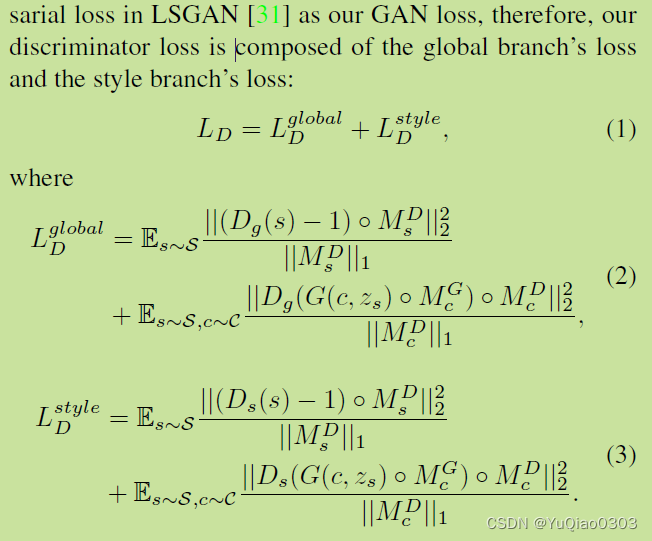
其实有点看不懂,因为感觉S应该只进入Ds ,而c应该只进入Dg。
但总之是说,经过了mask之后,我们希望对每个s输出结果是1(判定为real),而对每个generator的结果输出是0(判定为fake).
loss_d_real = (torch.sum((D_out[:,z_vector_style_idx:z_vector_style_idx+1]-1)**2 * Dmask_style) + torch.sum((D_out[:,-1:]-1)**2 * Dmask_style))/torch.sum(Dmask_style)
LGAN

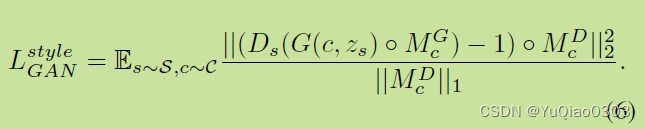
也是氛围global和style。也是一个Dg一个Ds,其他都一样。
他说的是,我希望经过generator生成的结果,经过mask以后,会被discrininator判定为1 (real).
Lr: reconstruction loss
希望generator 根据 降采样的s生成的s,和真实s完全一样。
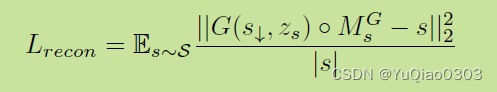
代码
看论文看不懂,看代码吧:
modelAE.py第455行:
D_out = self.discriminator(voxel_style,is_training=True)
loss_d_real = (torch.sum((D_out[:,z_vector_style_idx:z_vector_style_idx+1]-1)**2 * Dmask_style) + torch.sum((D_out[:,-1:]-1)**2 * Dmask_style))/torch.sum(Dmask_style)
loss_d_real.backward()
D_out = self.discriminator(voxel_fake,is_training=True)
loss_d_fake = (torch.sum((D_out[:,z_vector_style_idx:z_vector_style_idx+1])**2 * Dmask_fake) + torch.sum((D_out[:,-1:])**2 * Dmask_fake))/torch.sum(Dmask_fake)
loss_d_fake.backward()
self.optimizer_d.step()
preventing mode collapse
在输出层分成了N+1个branches (从补充材料看到,是N+1个通道。)
N是detailed shapes的数量,1是global branch。
训练时用weighted global loss和对应的stype-specific branch loss.
每个style的latent code是怎么求的
总结,最先开始是自己的style编号,然后让网络跟着一起优化一下。
首先这个z得是generator的forward的第2个参数z.
在modelAE.py里面可以看到,给他的是z_tensor_g.
是z_tensor和self.generator.style_codes的矩阵相乘。
而 z_tensor 看上面,是其他style是rand,自己的style是1的一个东西。
那么显然我们也可以这样弄。
self.generator.style_codes:
modelAE_GD:
style_codes = torch.zeros((self.prob_dim, self.z_dim))
self.style_codes = nn.Parameter(style_codes)
nn.init.constant_(self.style_codes, 0.0)
注意nn.Parameters意思是把它作为一个可训练的参数。
所以每次都会参与训练。
初始化为0.
Network overview说,we use an embedding module to learn an 8D latent style code for each given detailed shape.
generator/discrininator mask 怎么得到
是用coarse content shape 做最近邻上采样得到的。
对于generator mask,本文用的是256的分辨率。
对于 discirninator mask,用128的分辨率。
对generator:
可以直接上采样:strict
或者将原来的shape按一个voxe扩大之后,再上采样:loose。本文用的是loose
显存优化技术
crop, emm,就是按bounding box裁了一下。
modelAE.py
crop_voxel函数。
emm,而且好像只在test里面调用了?
只生成一半,因为假设是对称的。
0,1不好训练的问题,使用高斯filter。见4.4
那我们去代码里面看一下他的crop?
GPU与训练时间
Nvidia Telsa V100 GPU,each model takes 6 to 24 housrs depending on the category.
batch size 是1.
感觉还是,emm,有点凉。
tricks
binary不好训练,给voxel 高斯模糊一下。
代码
train
dxb = batch_index_list[idx]
mask_fake = torch.from_numpy(self.mask_content[dxb]).to(self.device).unsqueeze(0).unsqueeze(0).float()
Dmask_fake = torch.from_numpy(self.Dmask_content[dxb]).to(self.device).unsqueeze(0).unsqueeze(0).float()
input_fake = torch.from_numpy(self.input_content[dxb]).to(self.device).unsqueeze(0).unsqueeze(0).float()
z_tensor_g = torch.matmul(z_tensor, self.generator.style_codes).view([1,-1,1,1,1])
voxel_fake = self.generator(input_fake,z_tensor_g,mask_fake,is_training=False)
voxel_fake = voxel_fake.detach()
generator的输入是
input_fake,z_tensor_g,mask_fak
都是float类型,32位的。
那,确实,没有怎么,emm,节省的亚子。
算一下吧。
latent space
八维的style code,可以每一维都在上面连续的explore一下。

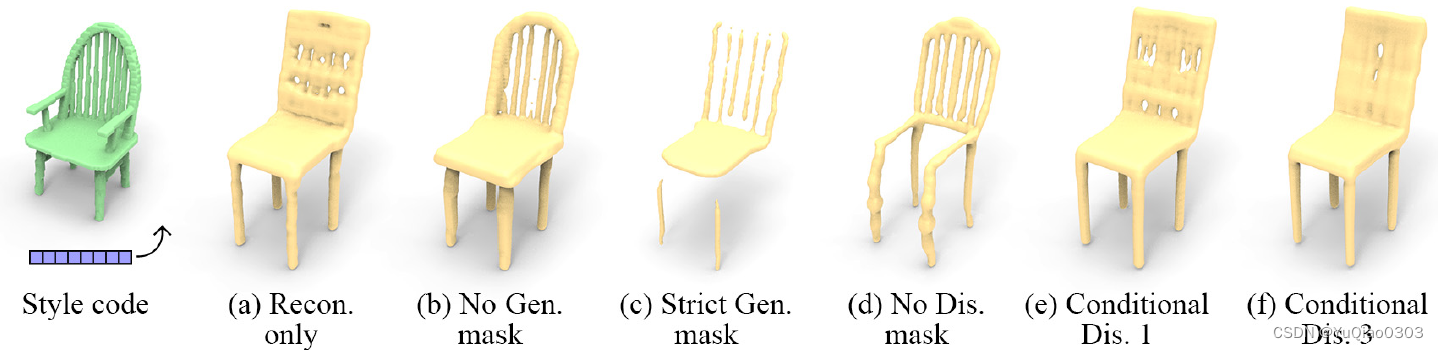
消融实验
masks
其中Conditional的意思是,generator和discrininator masks都不要了,在discrininator中用conditional GAN, 把coarse voxels作为condition。那个数字就是他的感受野。

高斯模糊
模糊得越厉害,越像style,但会过于模糊了。
作者说,如果渐进式训练,先用较大的模糊值,然后再用较小的σ,也许会更好。

奇异的截断线性函数模拟sigmoid:
在modelAE_GD.py里面第128行左右,用这个代替了sigmoid:
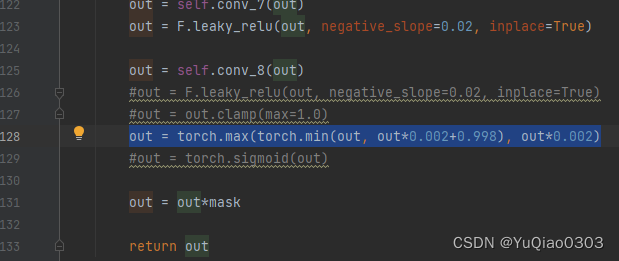
out = torch.max(torch.min(out, out0.002+0.998), out0.002)。
该函数是,
在0-1之间 为 y = x (斜率为1)
在其他位置斜率为0.002.
在0和1两点可以接上。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









