






- 来源
-
定义
-
给定一张图片 用矩形框标注出目标并预测出物体类别
-
-
应用领域
-
人脸识别
-
智慧城市
-
自动驾驶
-
-
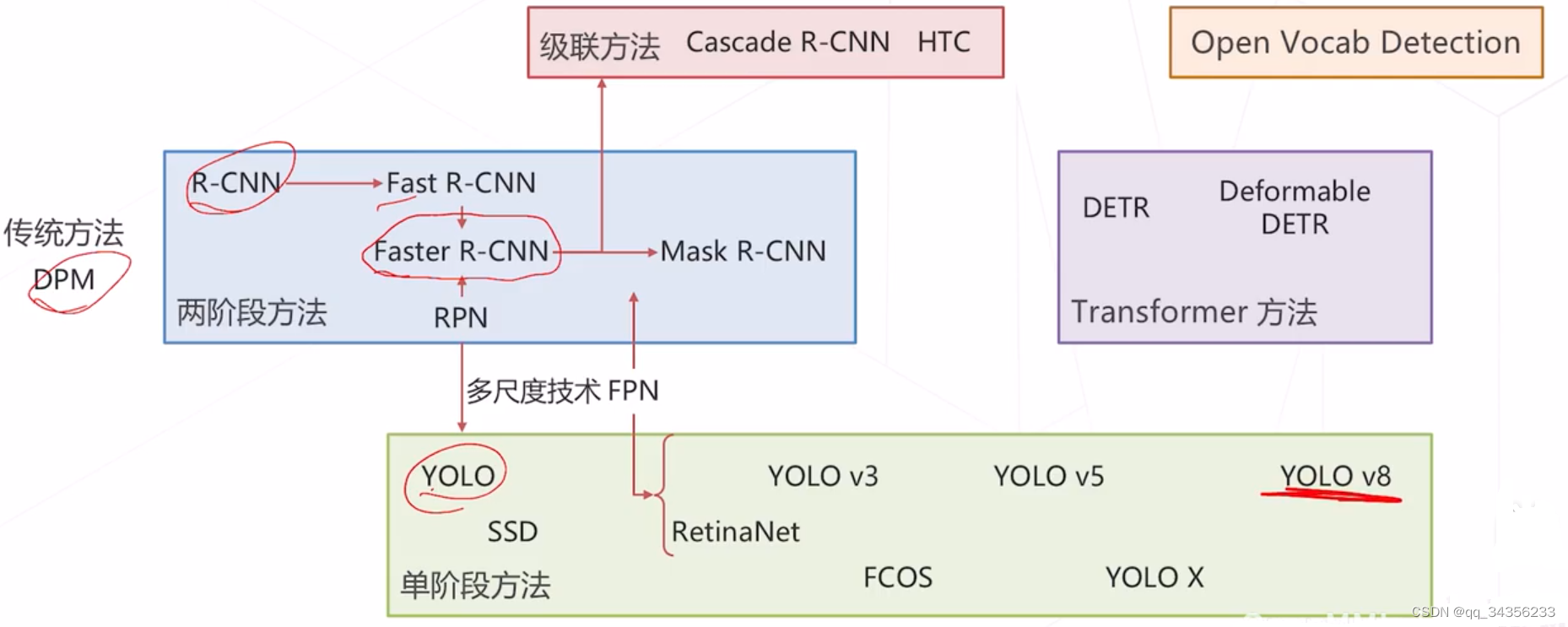
技术路线
-
两阶段方法
-
单阶段方法
-
Transformer方法
-
-
基本概念
-
边界框
-
交并比
-
滑窗
-
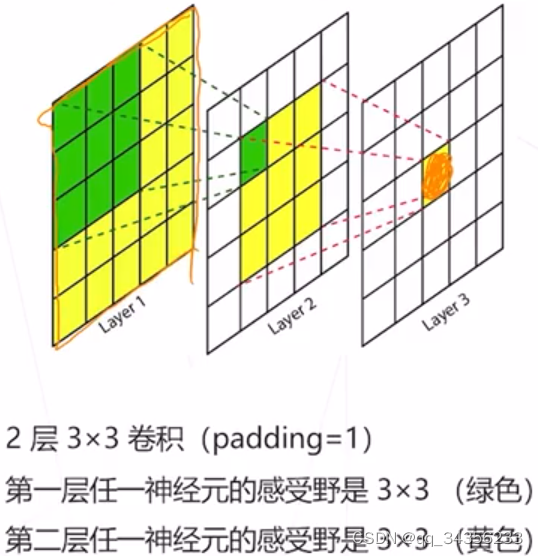
感受野
-
定义:在神经网络中 一个神经元能“看到”的原图的区域
-
中心:一般结论比较复杂
-
步长:
-
在某一层中 相邻两个神经元的感受野的距离
-
步长=这一层之前所有stride的乘积
-
-
-
-
有效感受野(Effective RF)
-
激活值对感受野内的像素求导 大小不同
-
-
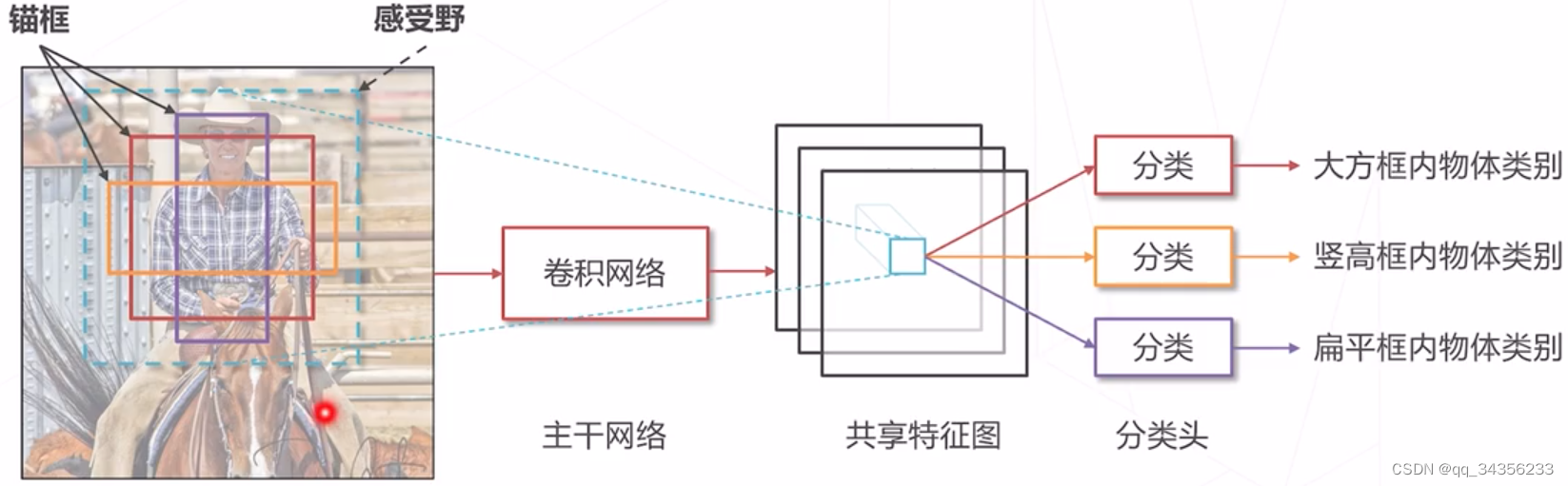
锚框:在原图上设置不同尺寸的基准框
-
生成不同尺寸的预测框
-
在同一位置生成多个提议框覆盖不同物体
-
-
难点
-
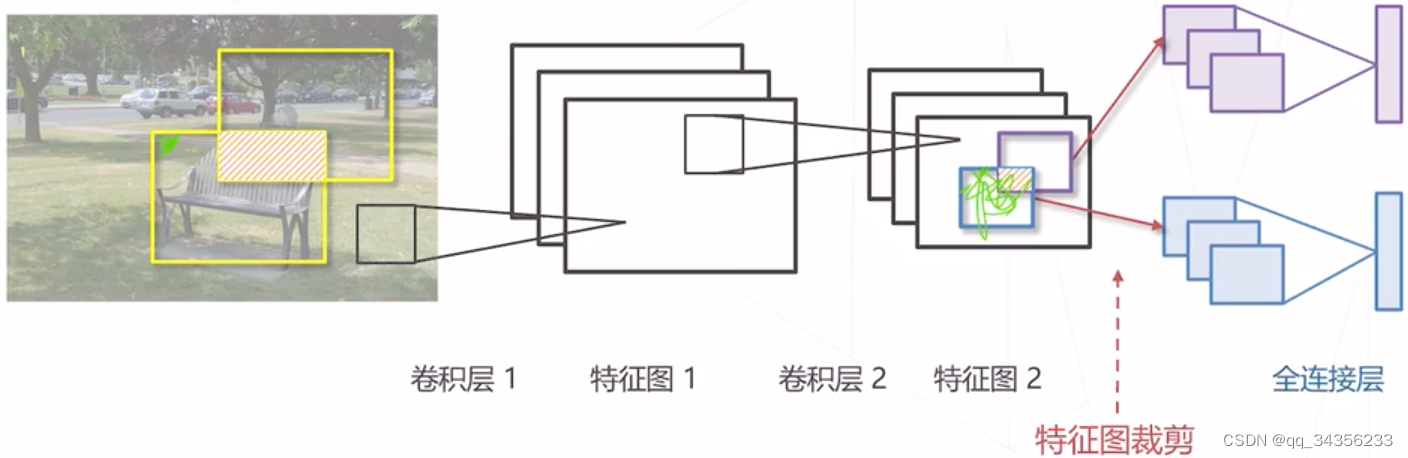
滑窗的重复计算问题
-
改进思路:特征图滑窗
-
用卷积一次性计算所有特征 再取出对应位置的特征完成分类
-
-
-
- 改进思路:在特征图上进行密集预测
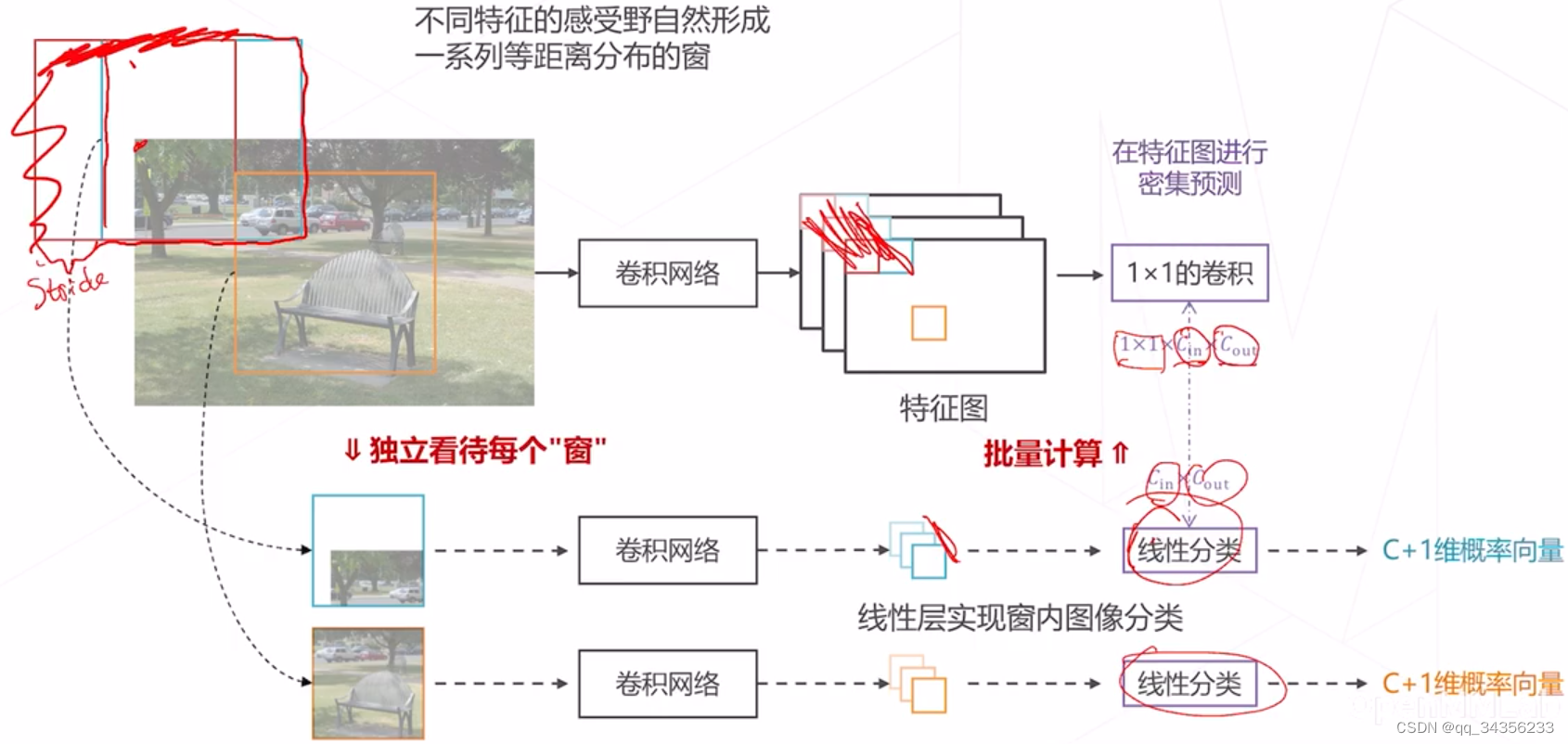
- 预测目标的尺度问题
-
图片中不同预测目标的尺寸可能存在较大差异
-
在高层特征图中 经过多次采样 位置信息逐层丢失 对于小物体的检测能力较弱 定位精度较低
-

-
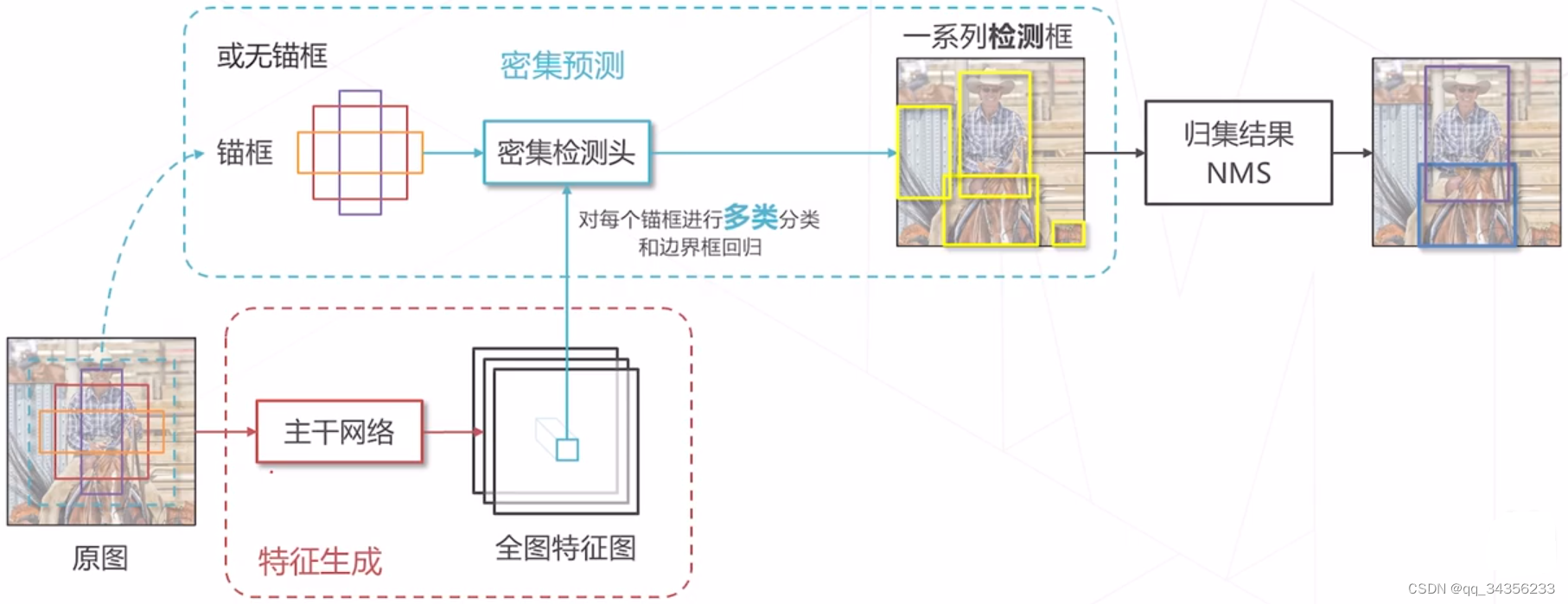
密集预测的基本思路
-
边界框回归:让模型同时预测物体类别和预测边界框相对于滑窗的偏移量
-

-
基于锚框VS无锚框
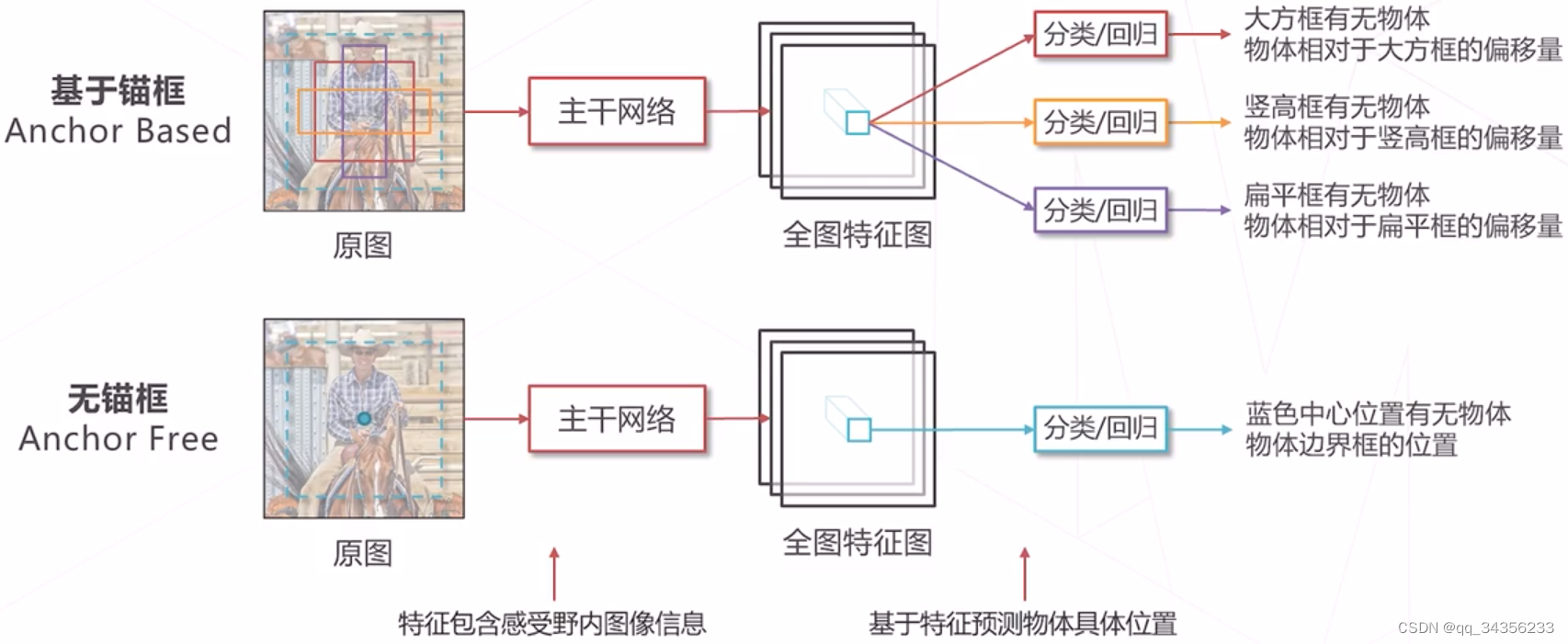
-
非极大值抑制
-
置信度:模型认可自身预测结果的程度
-
第一种:直接取模型预测物体属于特定类别的概率
-
第二种:单独预测置信度
-
-
密集预测模型的训练
-
检测头在每个位置产生一个预测
-
该预测值必须与某个真值比较产生损失
-
但是真值在数据标注中不存在 需要基于稀疏的标注框为预测结果产生真值 该过程称为匹配
-
-
密集预测的基本范式
-
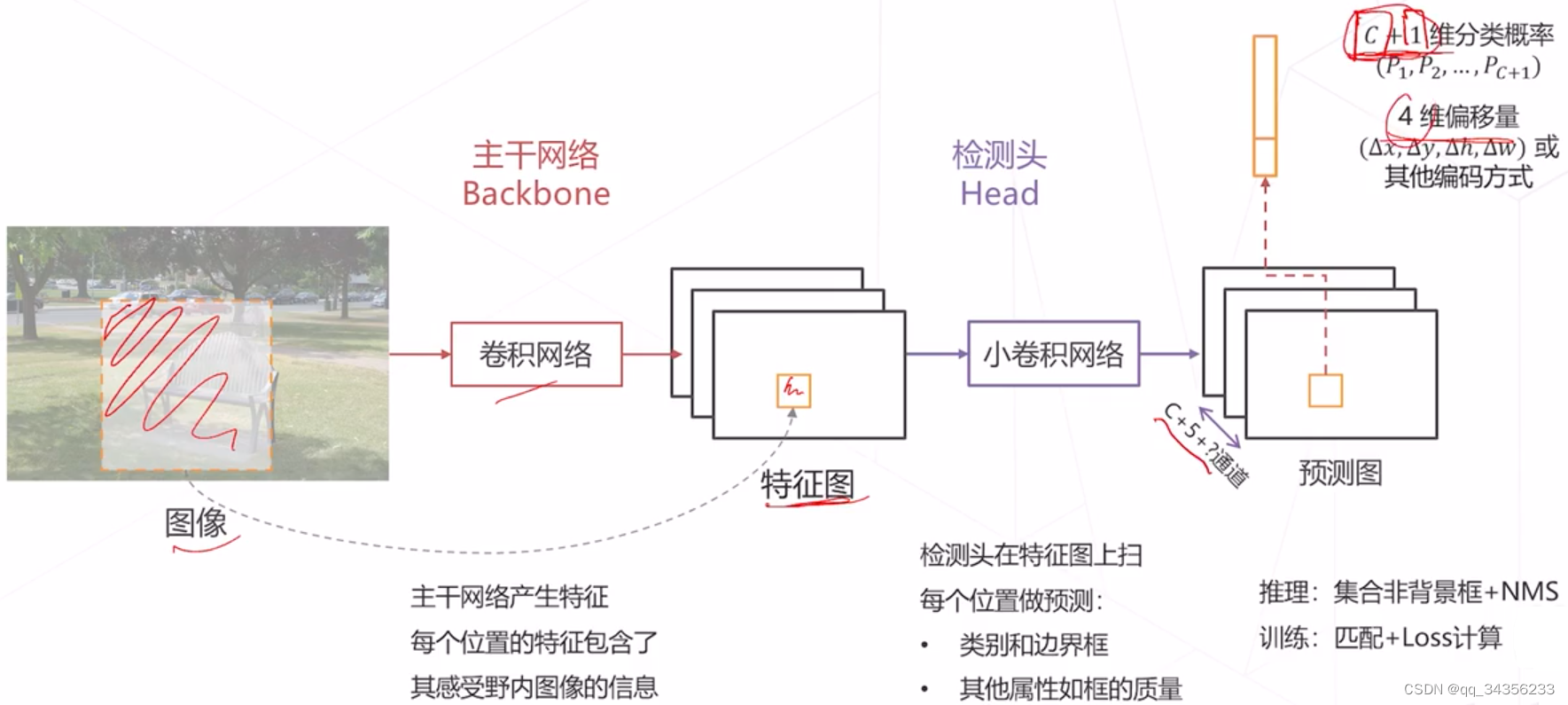
-
多尺度检测的基本思路
-
图片金字塔:将图片缩放成不同尺寸 使算法能在不同图片上检测出不同大小的物体
-

-
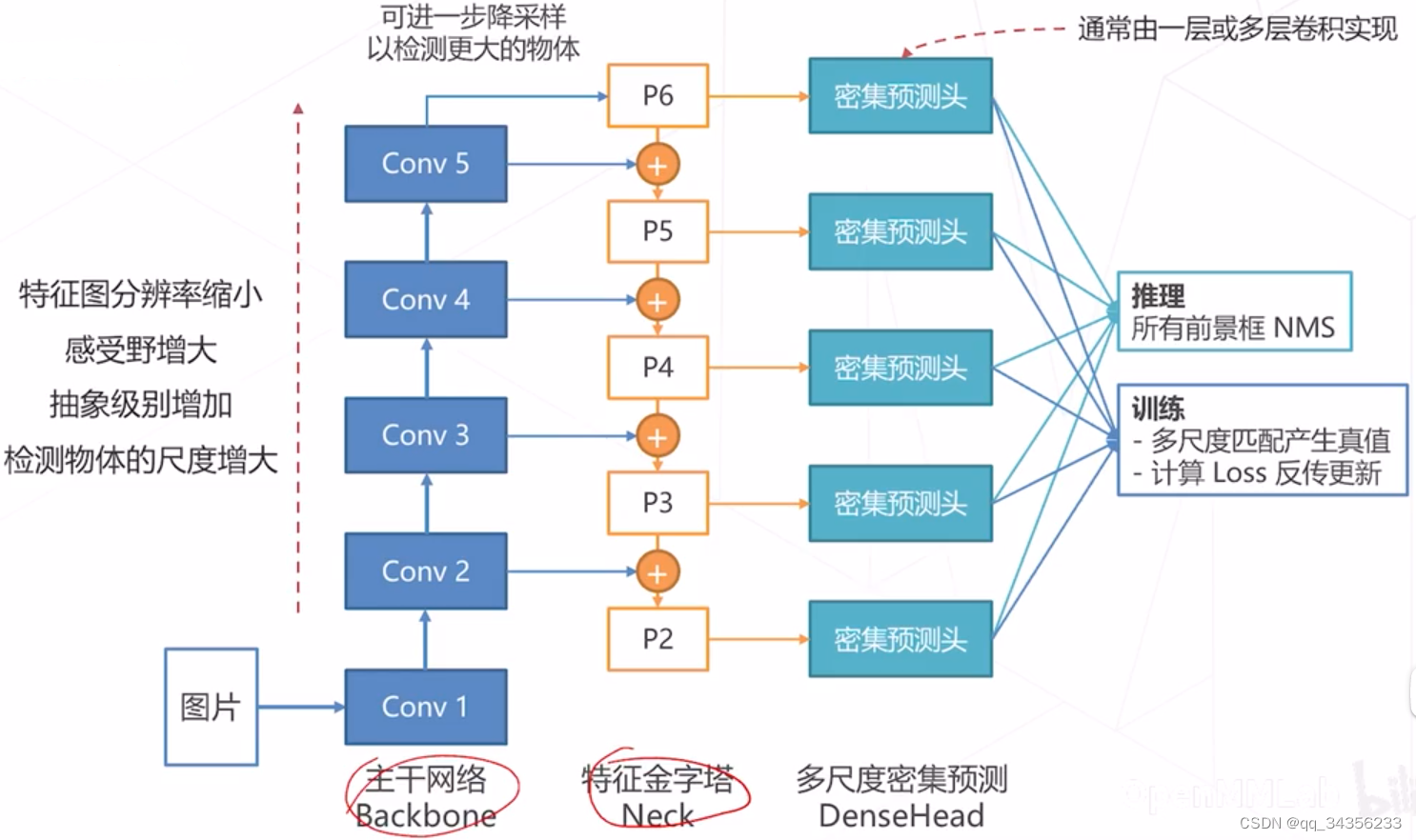
基于层次化特征:基于主干网络产生的多级特征图产生预测结果
-
劣势:底层特征抽象级别不够 预测物体比较困难
-
优势:计算成本低
-
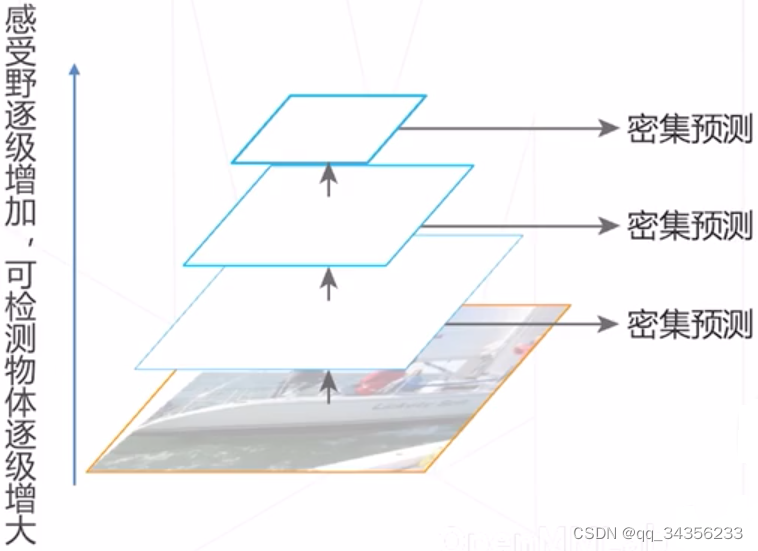
-
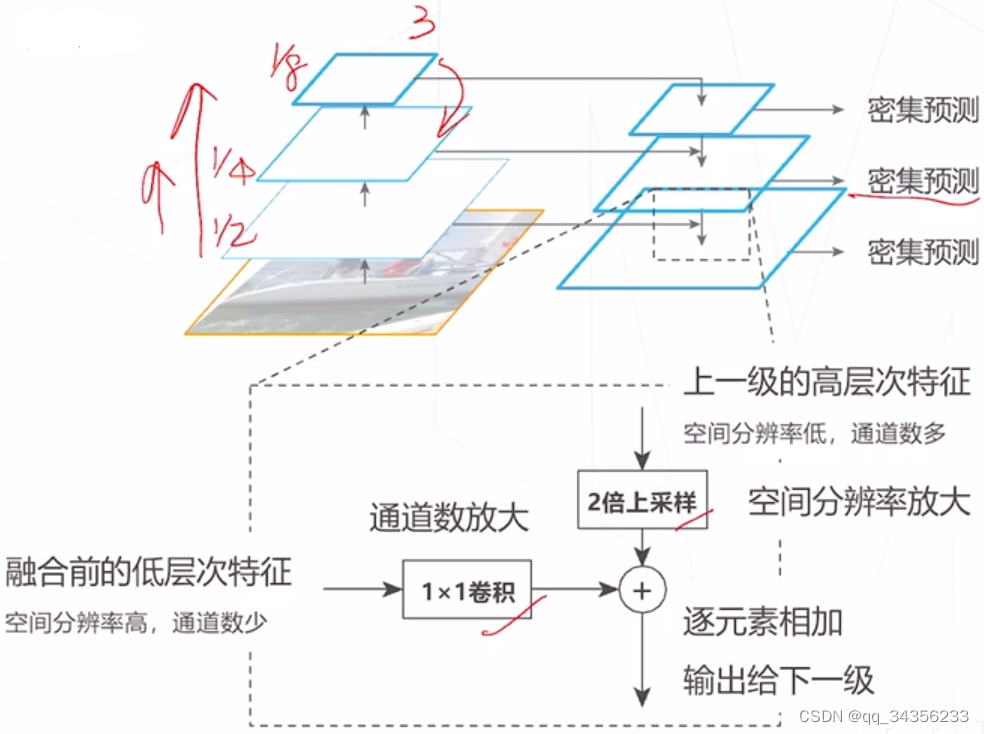
特征金字塔网络(Feature Pyramid Network):高层次特征包含足够抽象语义信息 将高层特征融入底层特征补充低层特征的语义信息
-
融合方法:特征求和
-
-
多尺度密集预测的主流范式
-
单阶段算法
-
主流方法
-
RPN(Region Proposal Network)
-
YOLO
-
SSD(Single Shot Multibox Detector)
-
RetinaNet
-
-
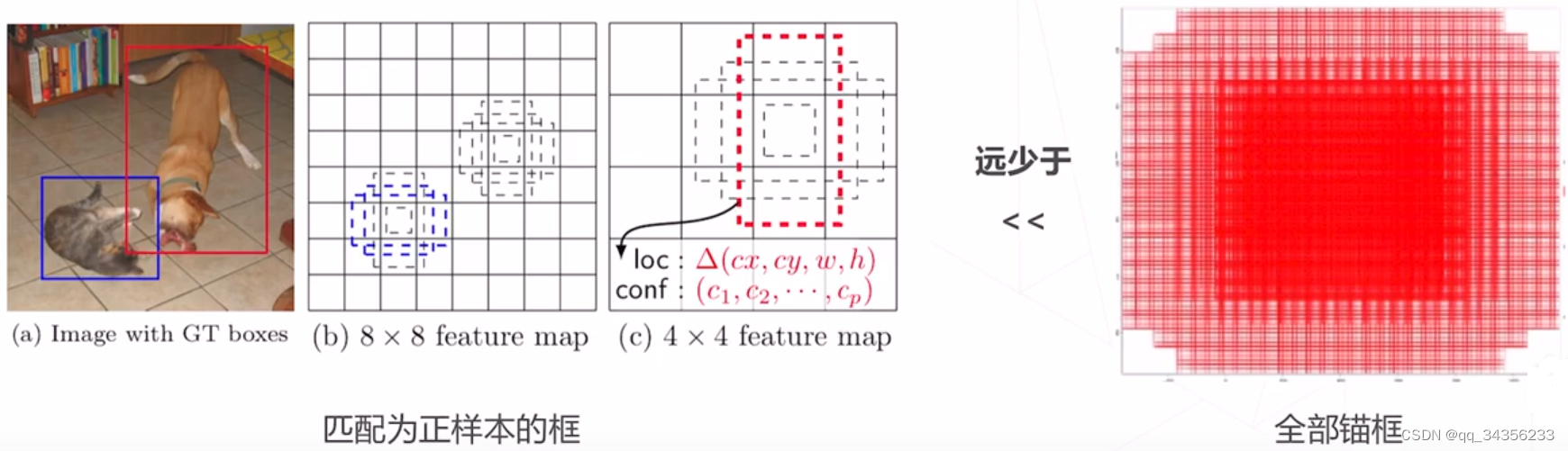
问题:正负样本不均衡
-
预测数量 = 尺度数 x 位置数 x 锚框数
-
在这些预测中 只有少量锚框的真值为正样本 大部分锚框的真值为背景
-
-
-
无锚框算法
-
主流方法
-
FCOS(Fully Convolutional One-Stage)
-
CenterNet
-
-
主流范式
-















 2812
2812











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









