






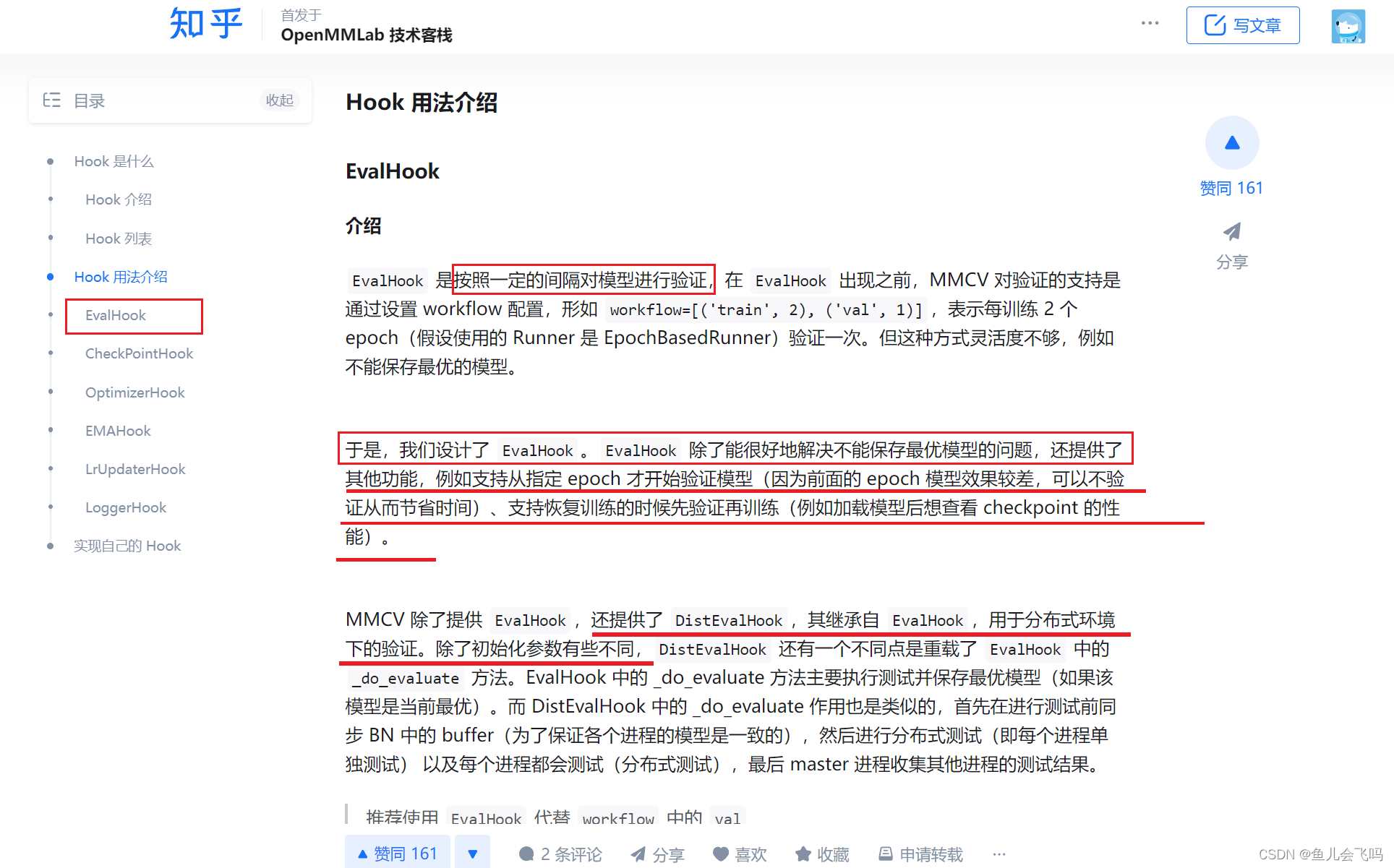
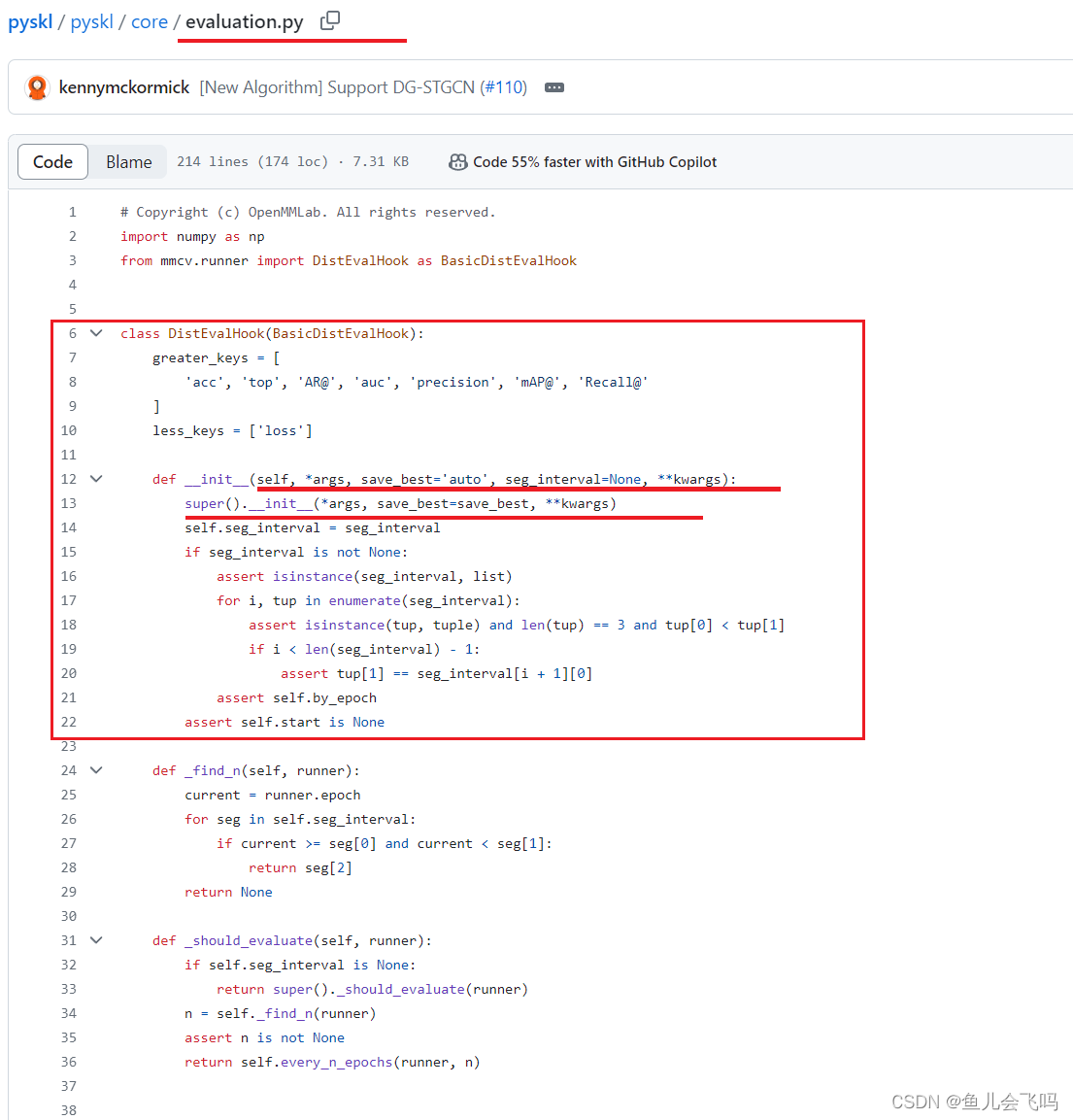
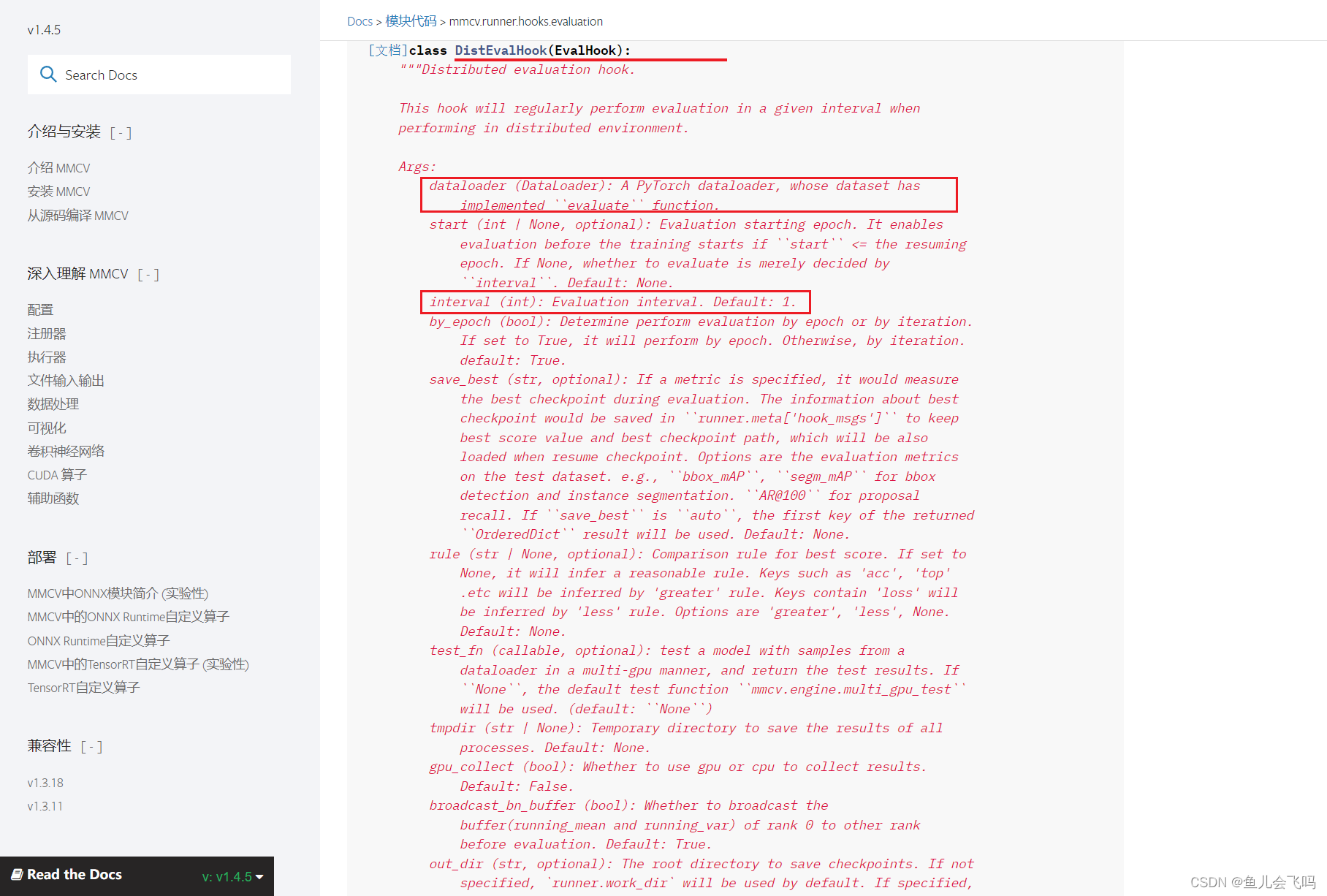
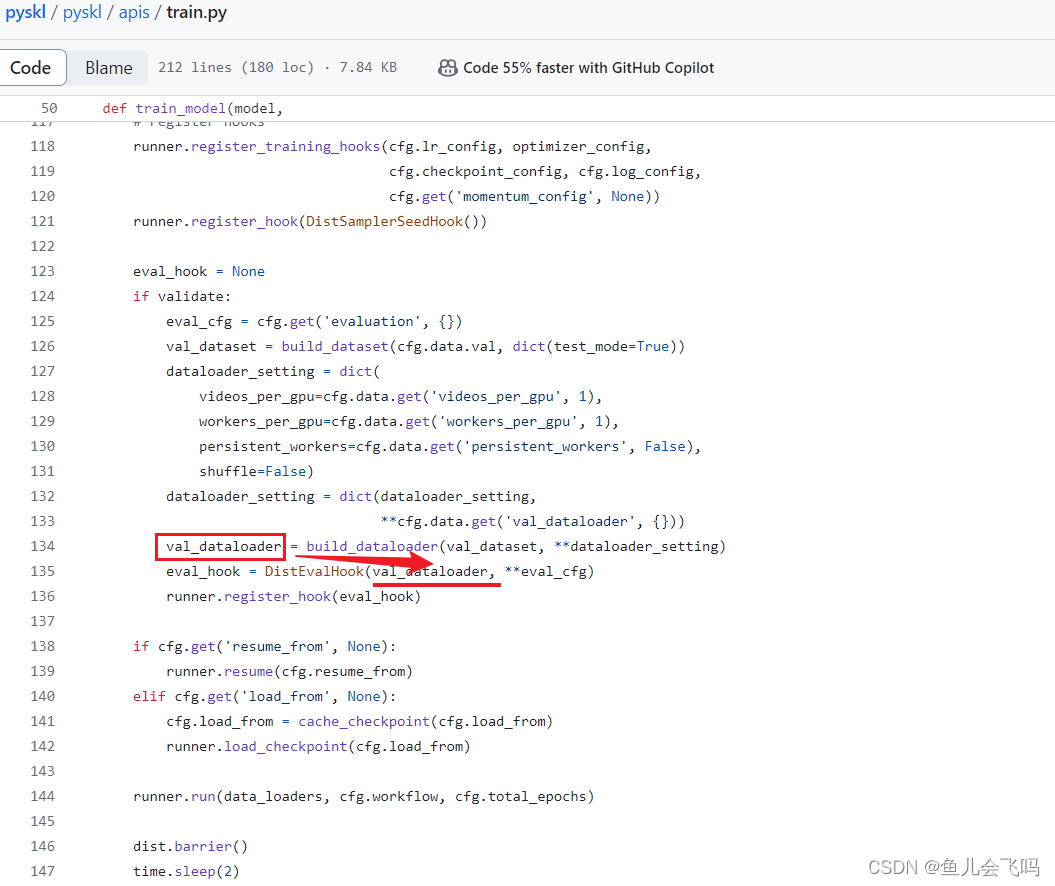
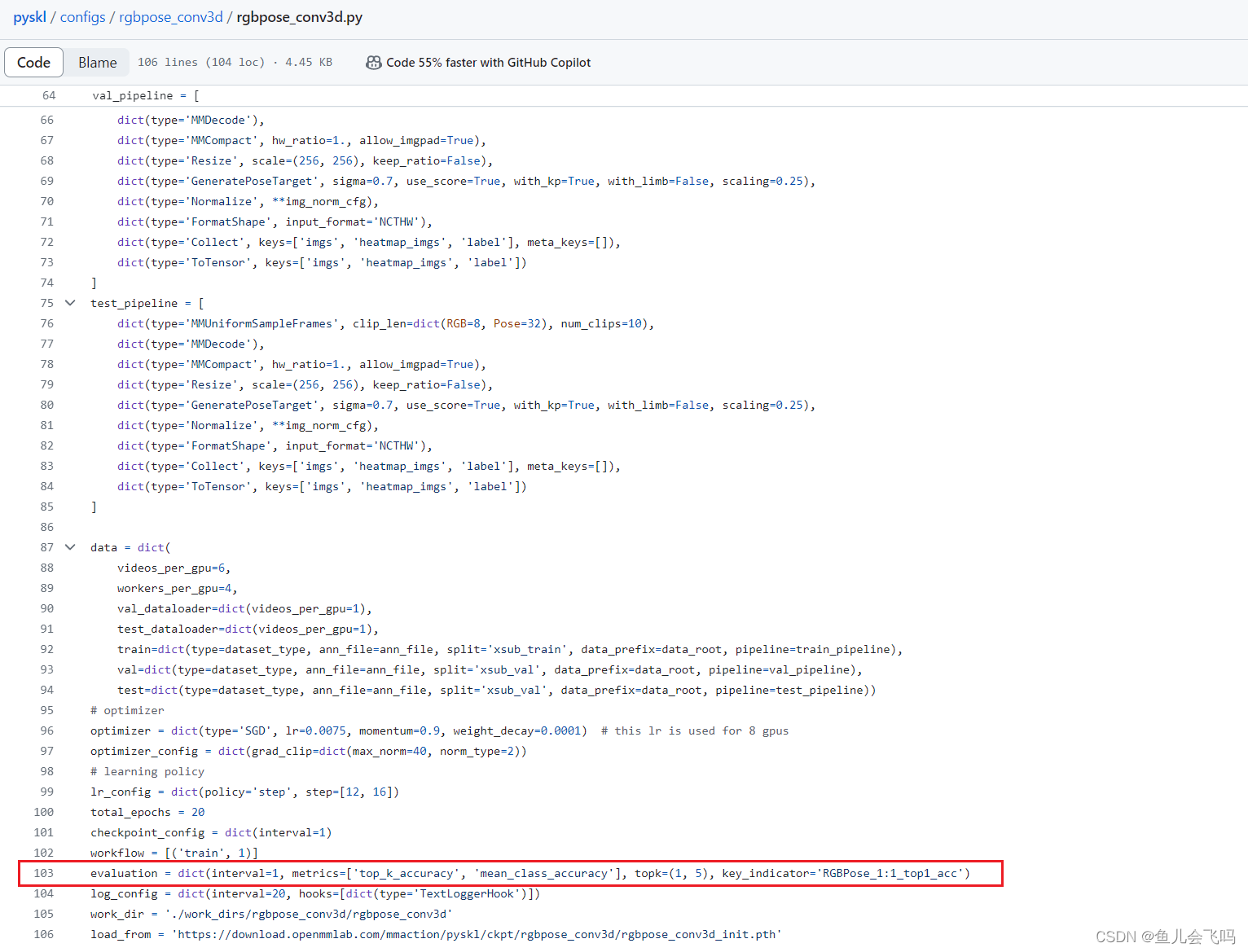
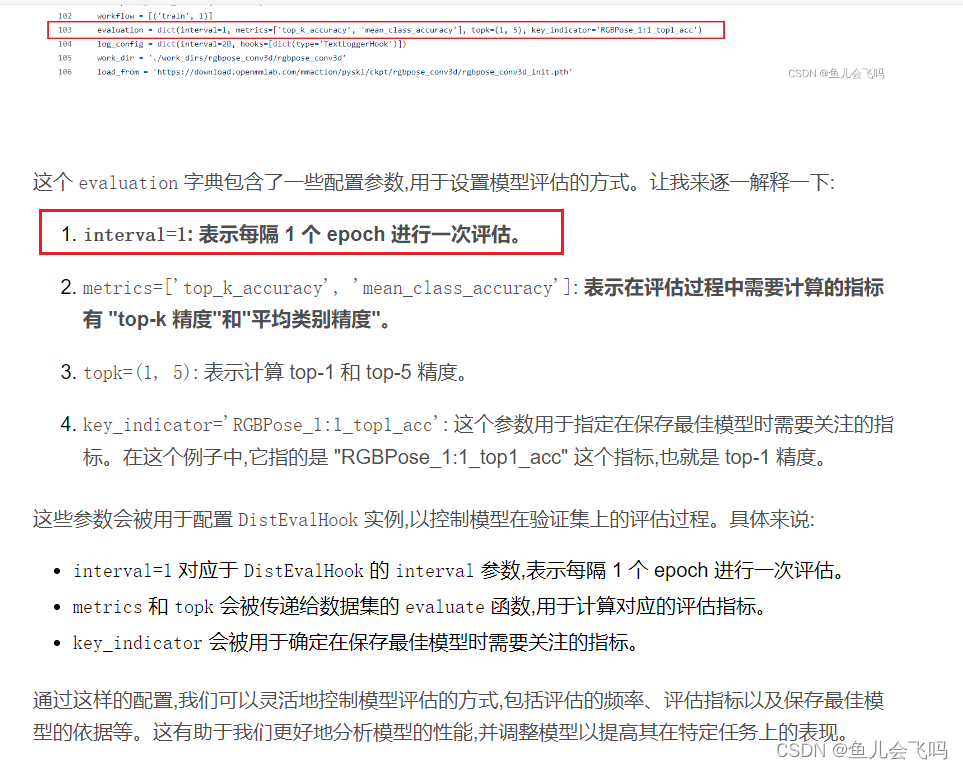
这个 evaluation 字典包含了一些配置参数,用于设置模型评估的方式。让我来逐一解释一下:
-
interval=1: 表示每隔 1 个 epoch 进行一次评估。 -
metrics=['top_k_accuracy', 'mean_class_accuracy']: 表示在评估过程中需要计算的指标有 "top-k 精度"和"平均类别精度"。 -
topk=(1, 5): 表示计算 top-1 和 top-5 精度。 -
key_indicator='RGBPose_1:1_top1_acc': 这个参数用于指定在保存最佳模型时需要关注的指标。在这个例子中,它指的是 "RGBPose_1:1_top1_acc" 这个指标,也就是 top-1 精度。
这些参数会被用于配置 DistEvalHook 实例,以控制模型在验证集上的评估过程。具体来说:
interval=1对应于DistEvalHook的interval参数,表示每隔 1 个 epoch 进行一次评估。metrics和topk会被传递给数据集的evaluate函数,用于计算对应的评估指标。key_indicator会被用于确定在保存最佳模型时需要关注的指标。
通过这样的配置,我们可以灵活地控制模型评估的方式,包括评估的频率、评估指标以及保存最佳模型的依据等。这有助于我们更好地分析模型的性能,并调整模型以提高其在特定任务上的表现。
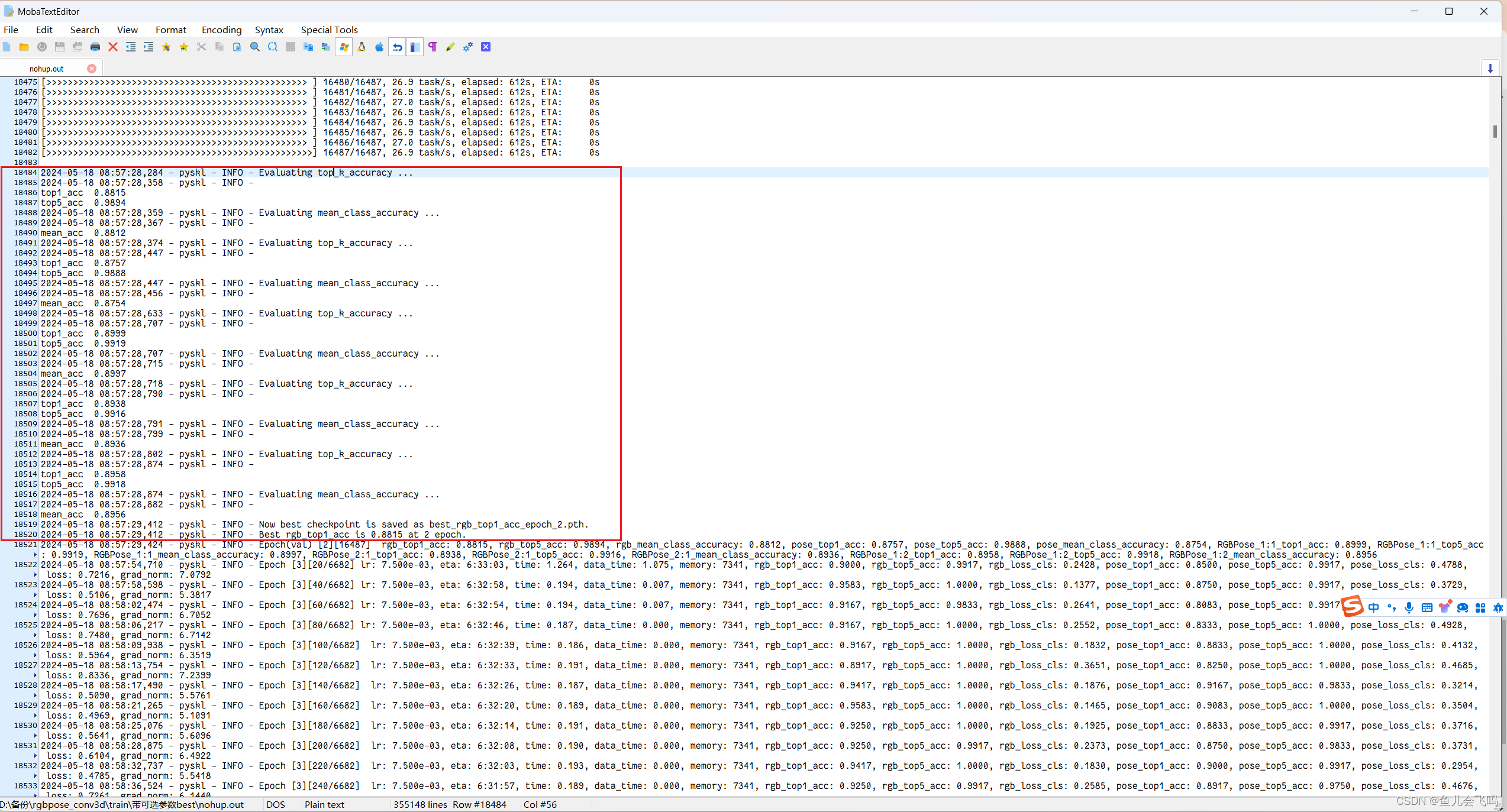
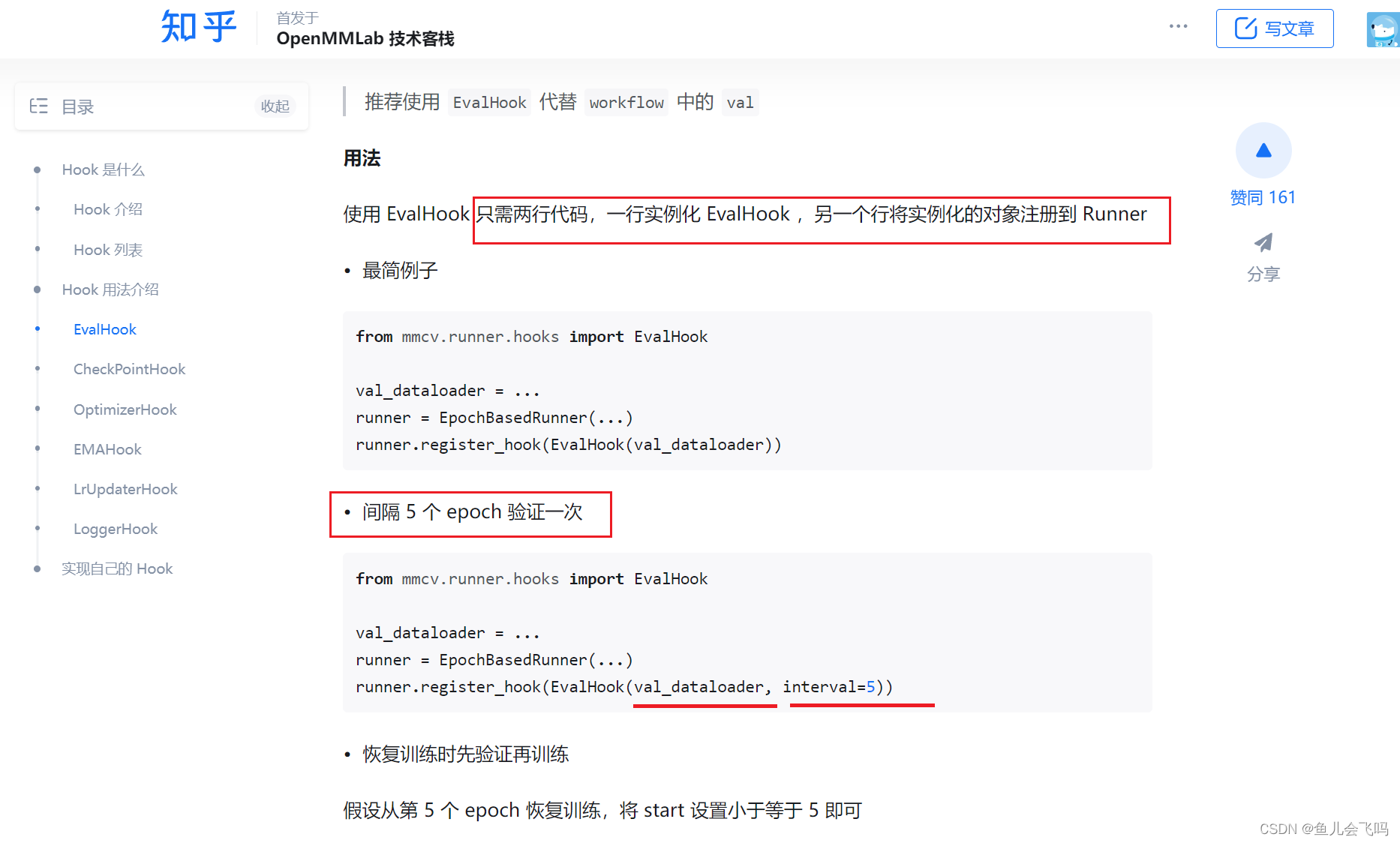
评估模型并不一定需要等到所有训练轮次结束之后再进行,在训练过程中就可以进行定期评估。这样做有以下几个好处:
-
可以及时了解模型在训练过程中的性能情况,及时发现问题并调整训练策略。
-
可以保存训练过程中表现最好的模型,而不是仅仅保存最终的模型。这对于训练过程不稳定的模型很有帮助。
-
可以根据评估结果决定是否提前结束训练,或者调整超参数等,提高训练效率。
-
对于一些训练时间较长的大型模型来说,分阶段评估比一次性评估更加实用。
在训练过程中进行定期评估,而不是等到所有轮次训练结束之后再评估,确实是一种很好的做法。这种边训练边评估的方式可以让模型训练更加高效和灵活。
是不是每训练一个轮次就开始评估一下,然后第二个轮次训练完之后,再评估一下?
通常情况下,我们不会在每训练一个轮次就立即进行评估。这样做可能会带来以下问题:
-
过于频繁的评估会降低训练效率,因为评估本身也需要耗费一定的计算资源和时间。
-
单个轮次的训练可能无法充分反映模型的整体性能,需要评估更多训练轮次累积的效果。
-
模型在训练初期通常会有较大的波动,频繁评估可能会得到不太可靠的结果。
通常情况下,我们会根据一定的周期(如每5个或10个轮次)进行一次评估。这样可以兼顾训练效率和评估效果。
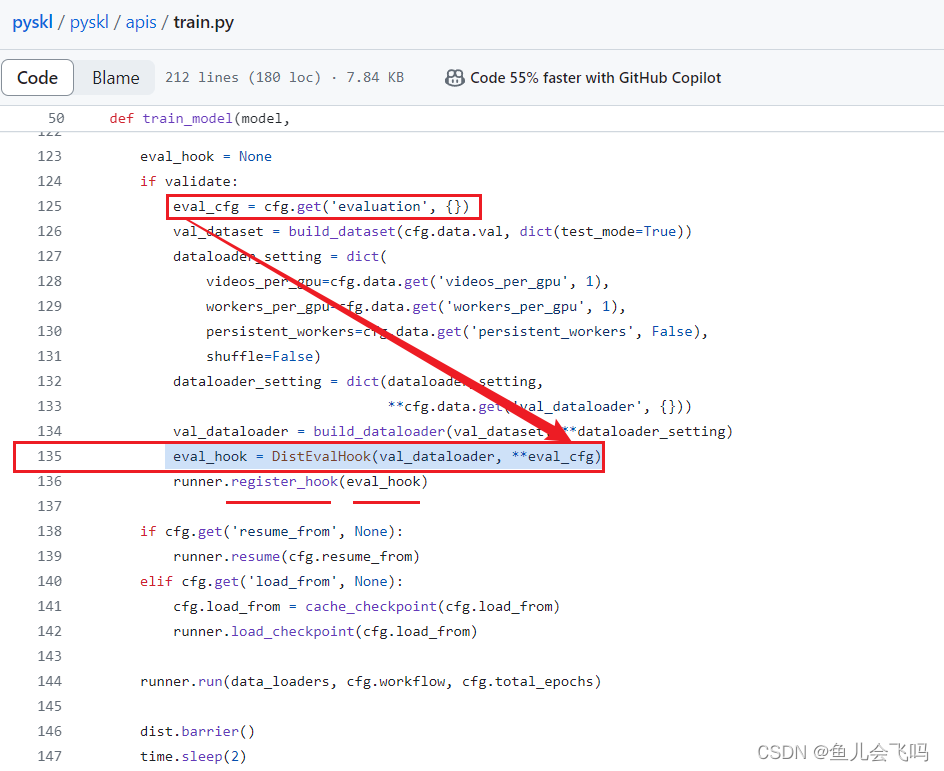
比如,在上面提到的 DistEvalHook 中,seg_interval 参数就是用来控制评估周期的。它定义了多个评估区间,比如在前100个轮次,每10个轮次评估一次;在100个轮次以后,每20个轮次评估一次。这种方式可以较好地平衡训练和评估的需求。
所以,我们一般不会在每个训练轮次之后立即进行评估,而是根据一定的周期进行评估。这样可以提高训练的整体效率和评估的可靠性。
https://zhuanlan.zhihu.com/p/448600739
mmcv.runner.hooks.evaluation — mmcv 1.4.5 文档
https://github.com/kennymckormick/pyskl/blob/main/configs/rgbpose_conv3d/rgbpose_conv3d.py

















 967
967

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









