










日期
2023.10.23
期刊
ECCV
论文标题
MVSNet: Depth Inference for Unstructured Multi-view Stereo
摘要
We present an end-to-end deep learning architecture for depth map inference from multi-view images. In the network, we first extract deep visual image features, and then build the 3D cost volume upon the reference camera frustum via the differentiable homography warping. Next, we apply 3D convolutions to regularize and regress the initial depth map, which is then refined with the reference image to generate the final output. Our framework flexibly adapts arbitrary N-view inputs using a variance-based cost metric that maps multiple features into one cost feature. The proposed MVSNet is demonstrated on the large-scale indoor DTU dataset. With simple post-processing, our method not only significantly outperforms previous state-of-the-arts, but also is several times faster in runtime. We also evaluate MVSNet on the complex outdoor Tanks and Temples dataset, where our method ranks first before April 18, 2018 without any fine-tuning, showing the strong generalization ability of MVSNet.
引用信息(BibTeX格式)
@misc{yao2018mvsnet,
title={MVSNet: Depth Inference for Unstructured Multi-view Stereo},
author={Yao Yao and Zixin Luo and Shiwei Li and Tian Fang and Long Quan},
year={2018},
eprint={1804.02505},
archivePrefix={arXiv},
primaryClass={cs.CV}
}.
本论文解决什么问题
在MVS方法中,虽然传统方法中有较高的深度估计精度,但由于存在在缺少纹理或者光照条件剧烈变化的场景中的错误匹配,传统方法的深度估计完整度还有很大的提升空间,
已有方法的优缺
1、传统的MVS方法使用hand-crafted similarity metrics and engineered regularizations(手工设计的相似性度量指标和正则化方法)求解3D 点云。但是在非朗伯体表面、无弱纹理区域的场景可以达到很好的效果,但是在弱纹理区域,人工设计的相似性指标变得不可信,因此导致重建结果不完整。
2、基于深度学习的双目立体匹配
在高光和反射的先验信息下可以得到更加鲁棒的匹配效果。
3、SurfaceNet
重建彩色体素立方体,将所有像素的颜色信息和相机参数构成一个3D代价体(the Colored Voxel Cubes),所构成的3D代价体即为网络的输入,然而受限于3D代价体巨大的内存消耗。
4、the Learned Stereo Machine (LSM)
直接利用可微分投影/反投影来实现端到端的训练,也会受限于3D代价体巨大的内存消耗
本文采用什么方法及其优缺点
而本文是在双目立体匹配的基础上,从双目三维重建扩展到了多目重建。本文区别于其他MVS方法的一个重要概念就是cost volume在MVS中的使用。
改进点如下:
1. 端到端MVS网络,每次计算一个深度图,而不是立即计算整个三维场景,这样的思路保证了大规模三维重建的可行性。
2. 使用可微的单应性warping(Differentiable Homography warping),来得到一个cost volume,保证了深度学习中的端到端的训练。
3. 为了适应多个输入,提出了一种差异化度量,可以将多个特征放入一个cost feature里。这个cost volume经过多尺度的3D卷积然后回归得到初始的视差图,最后经过优化得到最终的视差图。
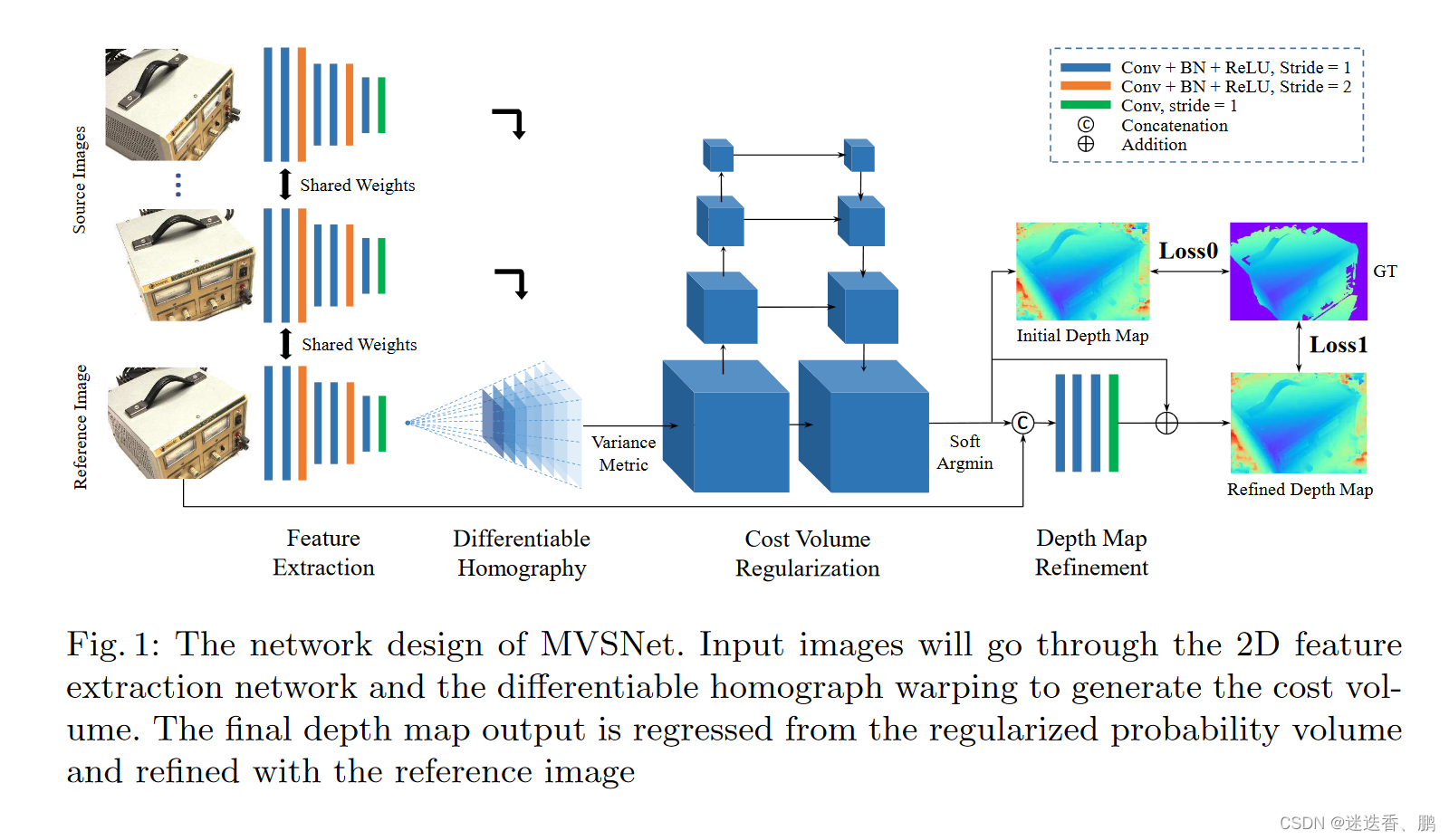
1.特征提取:
本文使用输入一张reference image(参考图) 和几张source images(待映射图),然后使用8个2D卷积提取feature maps,在第3层和第6层把strides设置为2,让特征图经过两次缩放,形成3个尺寸的特征图。对于每个尺寸,都使用了两个卷积,去提取更高级的图片特征。除了最后一层卷积,其他层都带有BN正则化以及ReLU激活,相比较使用原图来进行匹配,使用深度学习得到的多维特征图的匹配结果会好很多。
2.Cost Volume:
(1) Differentiable Homography warping
将得到的feature maps,通过{K,R,T}变换到参考平面得到不同的feature volume。其中,一个feature maps含有多个深度值,每个深度值(d)对应一个feature ,对应着一个的单应性变换矩阵(H)。公式为
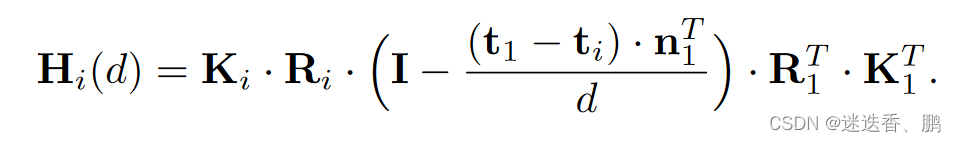
(2) Cost Metric
这里使用的构建cost volume的方法是使用方差,这个过程是将上文得到的feature volume变换成cost volume,聚合多张feature volume{Vi}至一个cost volume C。提出了一个N-view的相似性度量的cost metric的M。这里的使用这里的M组成了cost volume C,M就是这里的方差。方差越小,说明在该深度上置信度越高。
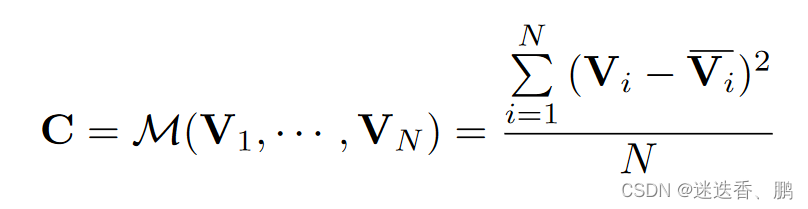
作者发现现有的方法使用均值去得到多个patch之间的相似性,但是作者发现均值并不能提供特征的相似性表示,这里选择方差度量利用多视图之间的特征差异。并且作者实验发现方差的精度要比均值高。
(3)Cost Volume Regularization
得到的cost volume带有很多噪声的,比如存在非朗伯曲面或者遮挡等。所以应该结合平滑度对深度图进行约束,因此在cost volume C的基础上,去生成一个probability volume P,用于深度图的推断。这里选择使用多尺度的UNet结构的3D CNN来进行正则化,采用编码-解码的架构。过程中,使用较小的内存,去合并周边的信息。为了进一步减少内存的消耗,在第一个3D卷积之后我们把32通道的cost volume减少到8个通道,并且在第2层和第3层缩小得图片的尺寸。最后的3D卷积层输出一个单通道的volume,最后我们利用深度方向的softmax操作进行概率归一化。
3.Depth Map:
(1). Initial Estimation
由于argmax操作不能得到亚像素精度,因此使用下式来估计图。
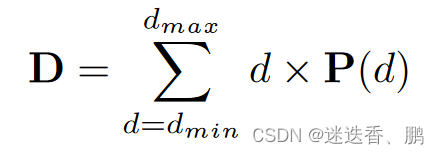
这里定义深度估计d帽为ground truth与周围相邻深度的相似性,使用4个相邻假设深度的概率和去度量估计的质量。
4.Depth map Refinment:
由于正则化过程中的大的感受野,导致了重建的边缘过于平滑,这一点和一些分割很类似。这里使用了深度图的残差学习网络,把3通道的RGB图和initial的深度图concat到一起成4 channel,然后经过卷积变成了1 channel。然后再add-wise。
为了防止在预先深度的上的bias,我们把初始深度调整到[0-1],最后优化结束后又给变回来。
5.Loss:
这里使用了混合监督的方式 ,具体损失使用的是L1 smooth做深度图的回归估计。
使用的数据集和性能度量
1、
数据集:The DTU dataset
评估指标:the accuracy、the completeness 、the f-score
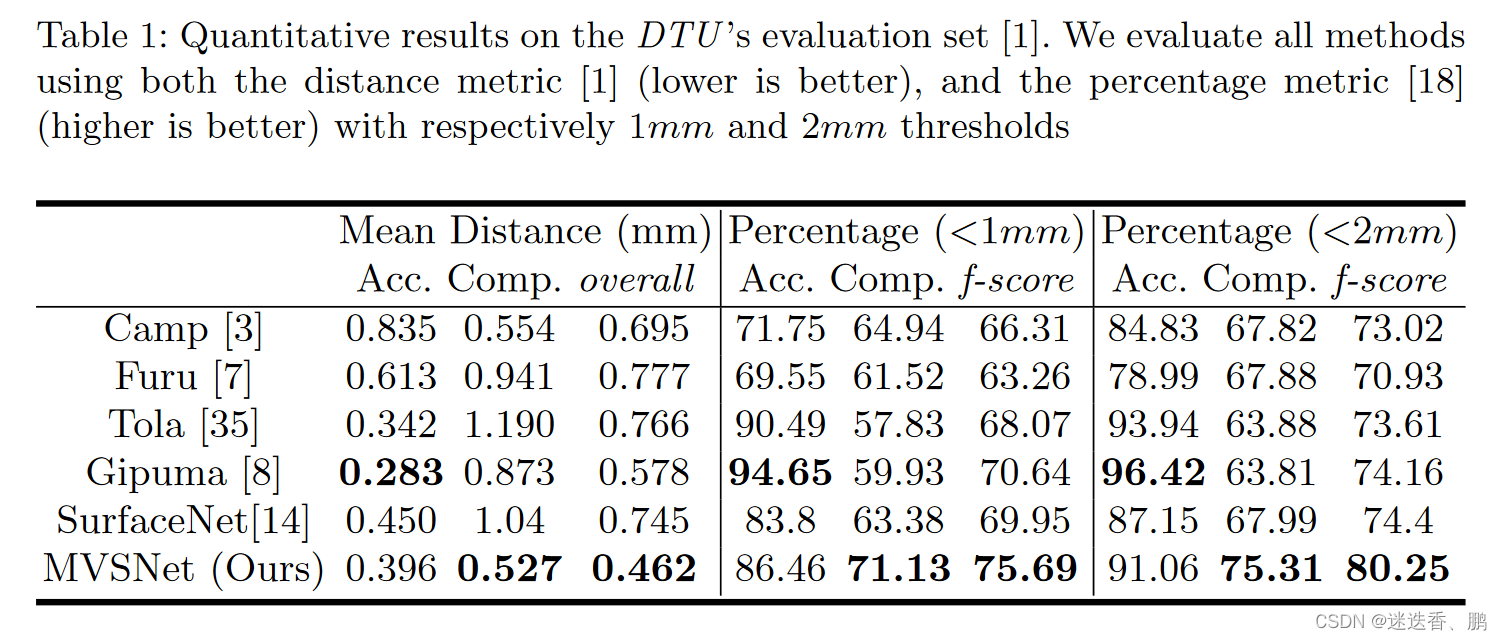

2、
Tanks and Temples dataset
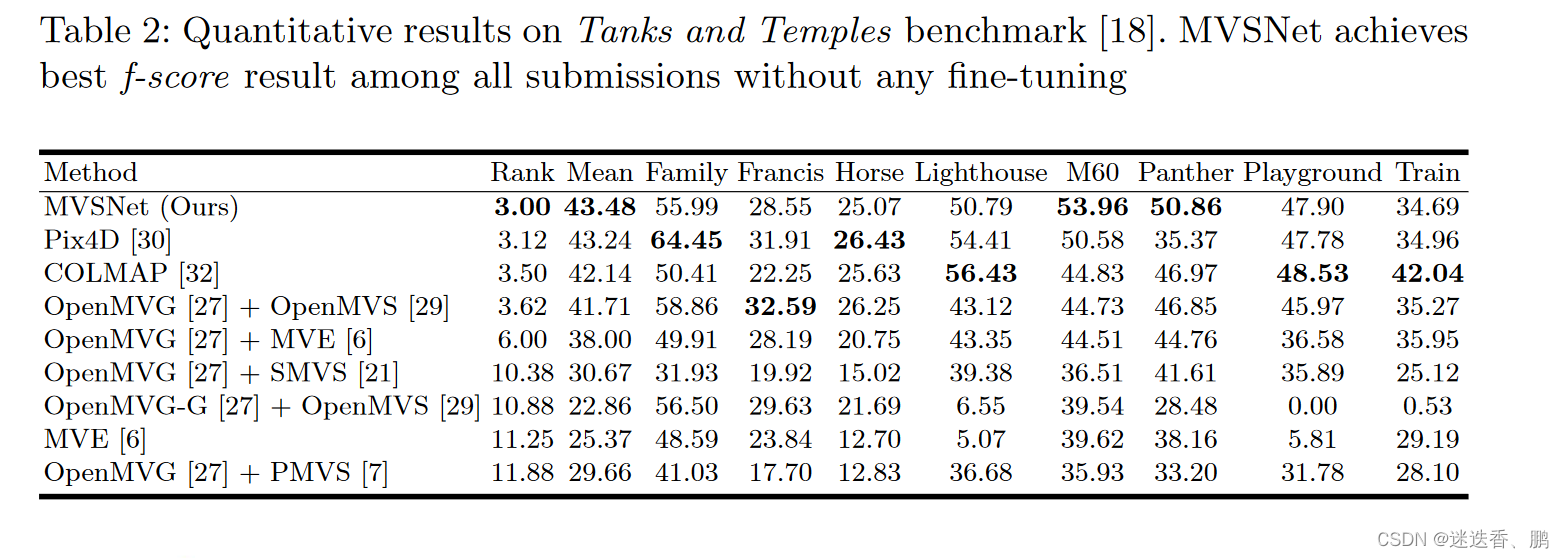
















 206
206











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









