









日期
ICCV 2020
论文标题
NeRF-SLAM: Real-Time Dense Monocular SLAM with Neural Radiance Fields
摘要
We propose a novel geometric and photometric 3D mapping pipeline for accurate and real-time scene reconstruction from monocular images. To achieve this, we leverage recent advances in dense monocular SLAM and real-time hierarchical volumetric neural radiance fields. Our insight is that dense monocular SLAM provides the right information to fit a neural radiance field of the scene in real-time, by providing accurate pose estimates and depth-maps with associated uncertainty. With our proposed uncertainty-based depth loss, we achieve not only good photometric accuracy, but also great geometric accuracy. In fact, our proposed pipeline achieves better geometric and photometric accuracy than competing approaches (up to 179% better PSNR and 86% better L1 depth), while working in real-time and using only monocular images.
引用信息(BibTeX格式)
@article{rosinol2022nerf,
title={NeRF-SLAM: Real-Time Dense Monocular SLAM with Neural Radiance Fields},
author={Rosinol, Antoni and Leonard, John J and Carlone, Luca},
journal={arXiv preprint arXiv:2210.13641},
year={2022}
}
本论文解决什么问题
结合单目稠密SLAM和层次化体素神经辐射场的3D场景重建算法,能实时地用图像序列实现准确的辐射场构建,并且不需要位姿或深度输入。
已有方法的优缺点
1、基于单目 RGB camera 的3D reconstruction, 在特定场景很难重建比如 direct sunlight,
2、对于Lidar 来说过于硬件设备相对昂贵
3、对于双目相机,能够简化深度估计但是依赖于标定参数
4、基于深度学习的方法,有optical flow 和 depth estimation 以及很多工作将深度学习应用于slam,然而,即使有了深度学习的改进,从随意拍摄的单目视频中实时构建高精度的场景3D地图目前仍很难。
5、神经辐射场(nerf) 能够进行3D场景表示具有光度精度。但是,考虑到构建NeRF所需的昂贵的体积渲染,NeRF很难推断,导致重建缓慢。此外,nerf最初要求真态估计收敛。
本文采用什么方法及其优缺点
核心思想是,使用一个单目稠密SLAM方法来估计相机位姿和稠密深度图以及它们的不确定度,用上述信息作为监督信号来训练NeRF场景表征。
算法包含Tracking和Mapping两个并行的线程,Tracking 模块使用单目稠密(dense monocular)SLAM估计稠密深度图(dense depth maps)和相机位姿,同时会输出对深度和位姿的不确定度估计,后端建图使用前端的输出信息作为监督,训练一个辐射场(radiance field),其损失函数是颜色误差和带权重的深度误差,权重值由先前的不确定度得到。
本工作提出了的场景重建方法结合了单目稠密SLAM和层次化体素神经辐射场的优点,使用Droid-SLAM,稠密的光流估计,从而估计出了深度的不确定度。把深度图,深度的不确定度和相机位姿输入到NeRF网络里进行监督(残差引入了深度)。一个线程用来Tracking,另一个线程用来监督和渲染。具体如下
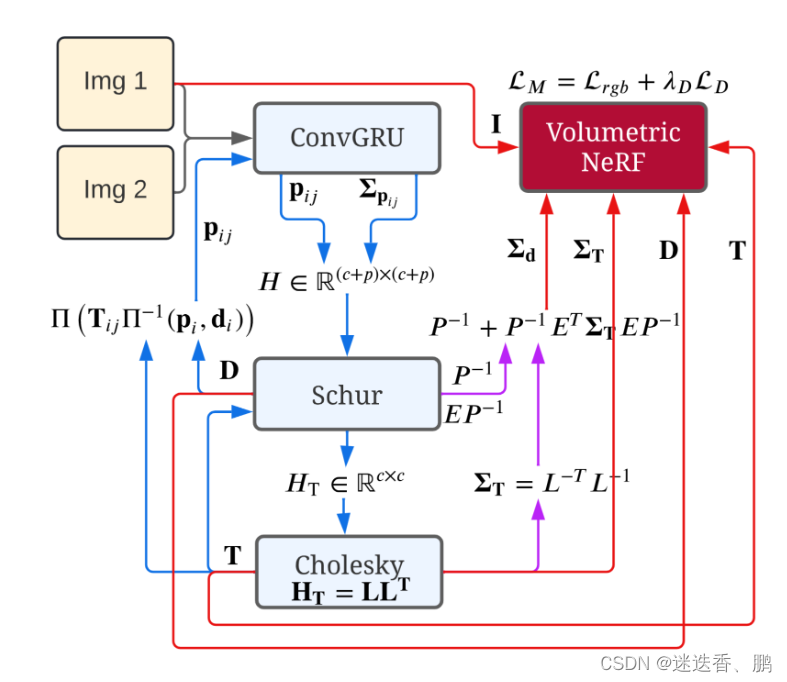
输入由连续的单目图像组成(这里表示为Img 1和Img 2)。从右上角开始,该架构使用instant-NGP的NeRF,其输入为RGB图像I,深度D来监督,其中深度由其边缘协方差∑D加权。我们从稠密单目SLAM(Droid SLAM)计算这些协方差。蓝色显示Droid SLAM的贡献和信息流,同样,粉色显示Rosinol的贡献,红色显示本文的贡献。
Tracking: Dense SLAM with Covariances
使用Droid-SLAM作为Tracking 模块,它为每个关键帧提供密集的深度图和姿势。从一连串的图像开始,Droid-SLAM首先计算出i和j两帧之间的密集光流pij,使用的架构与Raft相似。Raft的核心是一个ConvGRU,给定一对帧之间的相关性和对当前光流pij的猜测,计算一个新的流pij,以及每个光流测量的权重Σpij。
有了这些 flows 和 weights作为测量值,DroidSLAM解决了一个BA问题,其中三维几何被参数化为每个关键帧的一组反深度图。这种结构的参数化导致了解决密集BA问题的极其有效的方式,通过将方程组线性化为我们熟悉的相机/深度箭头状的块状稀疏Hessian H∈R (c+p)×(c+p) ,其中c和p是相机和点的维度,可以被表述为一个线性最小二乘法问题。
从图中可以看出,为了解决线性最小二乘问题,我们用Hessian的Schur补数来计算缩小的相机矩阵HT,它不依赖于深度,维度小得多,为R c×c。通过对HT=LLT的Cholesky因子化,其中L是下三角Cholesky因子,然后通过前置和后置求解姿势T,从而解决相机姿势的小问题。此外,给定姿势T和深度D,Droid-SLAM建议计算诱导光流,并再次将其作为初始猜测送入ConvGRU网络,如图2左侧所示,其中Π和Π-1,是the projection and back-projection函数。图2中的蓝色箭头显示了跟踪循环,并对应于Droid-SLAM。然后,受Rosinol等人的启发,我们进一步计算密集深度图和Droid-SLAM的姿势的边际协方差(图2的紫色箭头)。为此,我们需要利用Hessian的结构,我们对其进行块状分割如下:
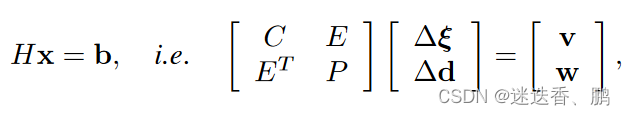
其中H是Hessian矩阵,b是残差,C是块状相机矩阵,P是对应于每个像素每个关键帧的反深度的对角矩阵。我们用∆ξ表示SE中相机姿态的谎言代数的delta更新,而∆d是每个像素反深度的delta更新。E是相机/深度对角线Hessian的块矩阵,v和w对应于姿势和深度的残差。从这个Hessian的块分割中,我们可以有效地计算密集深度Σd和姿势ΣT的边际协方差:
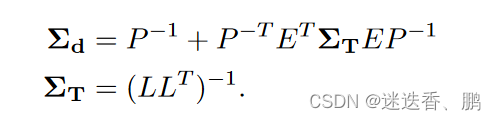
最后,鉴于跟踪模块计算出的所有信息–姿势、深度、它们各自的边际协方差以及输入的RGB图像–我们可以优化我们的辐射场参数,并同时完善相机的姿势。
Mapping: Probabilistic Volumetric NeRF
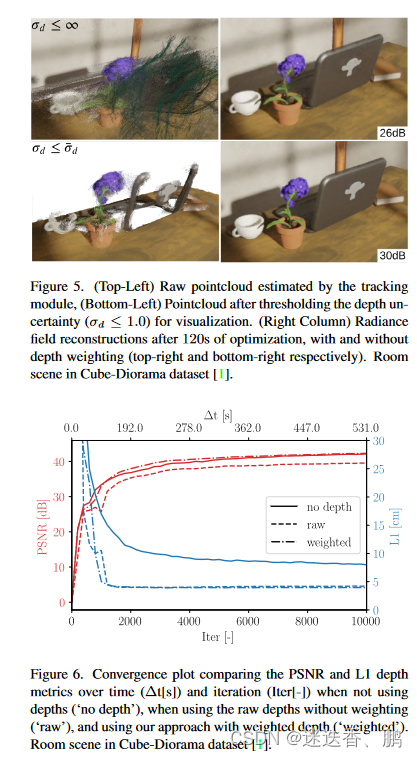
鉴于每个关键帧的密集深度图,有可能对我们的神经体积进行深度监督。不幸的是,由于其密度,深度图是非常嘈杂的,因为即使是无纹理的区域也被赋予了一个深度值。图3显示,密集的单眼SLAM所产生的点云是特别嘈杂的,并且包含大的离群值(图3的顶部图像)。根据这些深度图监督我们的辐射度场会导致有偏见的重建。
Rosinol等人的研究表明,深度估计的不确定性是一个很好的信号,可以为经典的TSDF体积融合的深度值加权。受这些结果的启发,我们使用深度不确定性估计来加权深度损失,我们用它来监督我们的神经体积。图1显示了输入的RGB图像,其相应的深度图的不确定性,所产生的点云(在用σd≤1.0对其不确定性进行阈值化以实现可视化),以及我们使用不确定性加权的深度损失时的结果。鉴于不确定性感知的损失,我们将我们的映射损失表述为:
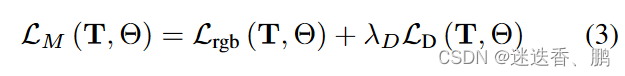
我们对姿势T和神经参数Θ进行最小化,给定超参数λD来平衡深度和颜色监督(我们将λD设置为1.0)。特别是,我们的深度损失是由以下公式给出的。
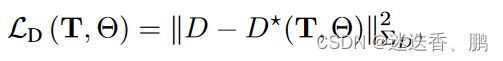
其中,D是渲染的深度,D、ΣD是由跟踪模块估计的密集深度和不确定性。我们将深度D渲染为预期的射线终止距离。每个像素的深度都是通过沿着像素的射线取样的三维位置来计算的,在样本i处评估密度σi,并将得到的密度进行alpha合成,与标准的体积渲染类似:
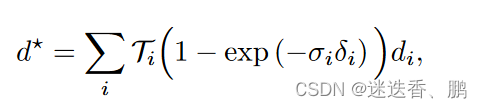
颜色的渲染损失如下:
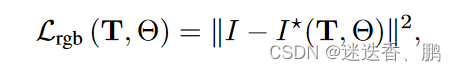
Architecture
我们的管道由一个跟踪线程和一个映射线程组成,两者都是实时和并行运行的。追踪线程不断地将关键帧活动窗口的BA重投影误差降到最低。映射线程总是优化从跟踪线程收到的所有关键帧,并且没有一个有效帧的滑动窗口。这些线程之间的唯一通信发生在追踪管道生成新关键帧时。在每一个新的关键帧上,跟踪线程将当前关键帧的姿势与它们各自的图像和估计的深度图,以及深度的边际协方差,发送到映射线程。只有跟踪线程的滑动优化窗口中当前可用的信息被发送到映射线程。跟踪线程的有效滑动窗口最多包括8个关键帧。只要前一个关键帧和当前帧之间的平均光流高于一个阈值(在我们的例子中是2.5像素),跟踪线程就会生成一个新的关键帧。最后,映射线程还负责渲染,以实现重建的交互式可视化
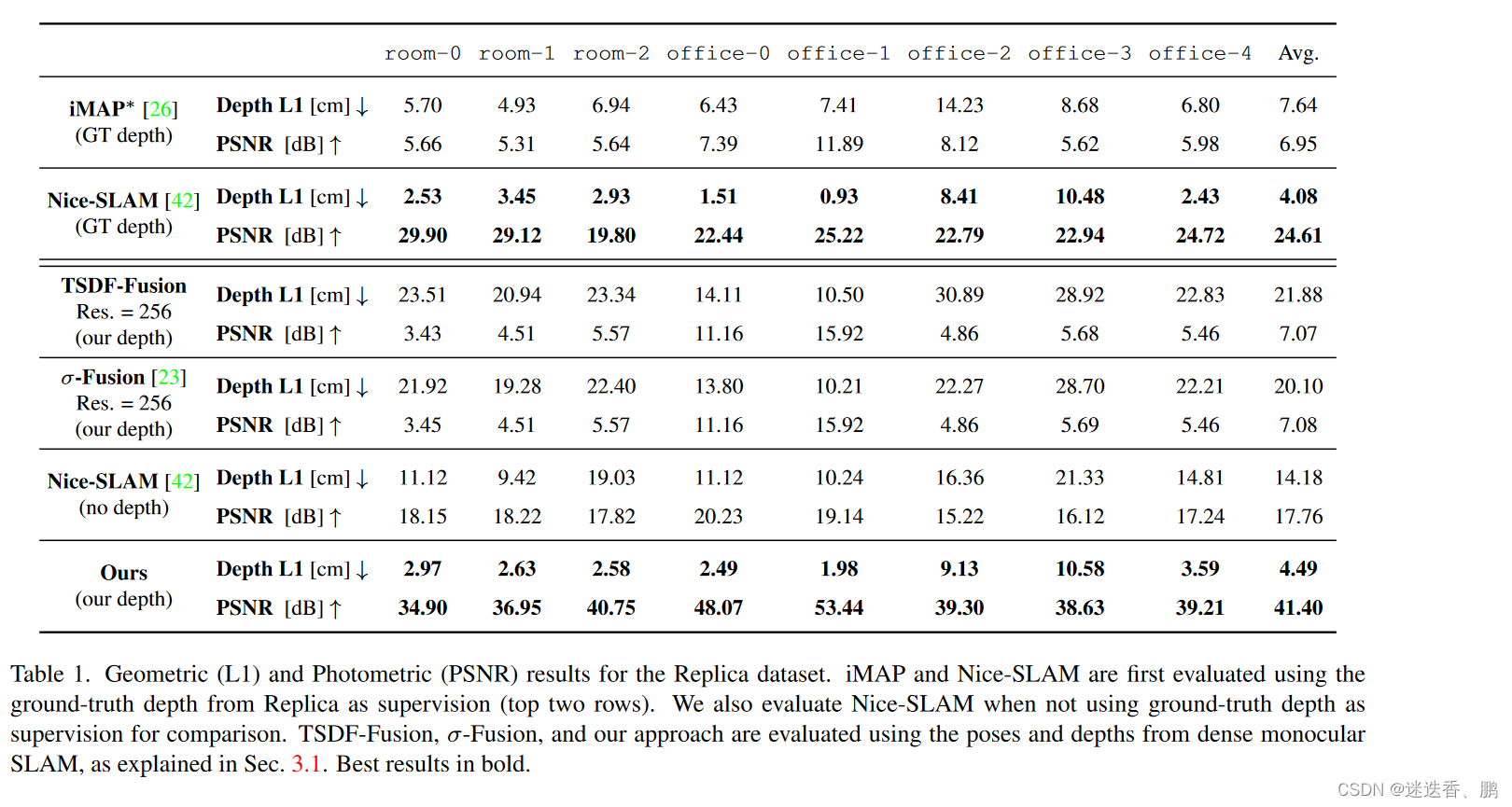
使用的数据集和性能度量
the Cube-Diorama
the Replica dataset
















 106
106











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









