









笔者来聊聊MPU的理解
MPU学习与应用
1、MPU的概念以及作用
MPU:Memory Protection Unit,硬件保护单元,工作在L1 内存系统,可以控制对L1 memory的访问。
- MPU只能限制CPU的访问属性,并不能限制其他硬件的访问,比如DMA等。
- 可以将内存分成多个区域,从而分别对每个区域的保护属性进行配置。
- 每个区域可以配置基地址和size。
- 支持0,12,16个内存区域
- 内存区域支持重叠覆盖,因此区域有优先级,0号区域优先级最低,15号优先级最高。
例如一个默认的内存区域配置。

- 0xC0000000 - 0xEFFFFFFF: 数据内存区域,强排序内存区域,无法执行。
- 0xA0000000 - 0xBFFFFFFF :数据内存区域,共享的外设区域,无法执行,当做内存数据访问
- 0x80000000 - 0x9FFFFFFF :不共享设备区域,无法执行,当做内存数据访问
- 0x40000000 - 0x5FFFFFFF :可以放置指令或者数据,如果指令cache允许,则属性为常规属性,有cache,不共享。如果指令cache不允许,则配置成常规,不cahce,不共享属性。如果数据cache允许,则属性配置成常规,写通cahce,共享。如果数据cache不允许,则配置成常规,不cache,共享。该区域只有指令是运行执行。
数据cache可以配置成:写通cache,写回写分配cache。数据和外设一般是共享的。指令一般不是cache的。
内存基地址:内存基地址必须是要配置的内存size的整数倍。
内存大小:内存大小是5bit,编码从32 Byte到4GB,如下图所示。

1.1 重叠区域:
内存区域支持重叠,高优先级区域会覆盖低优先级的区域属性。
例如下图所示:
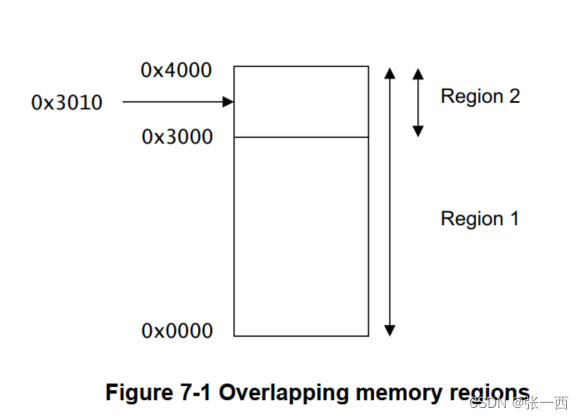
region1:16KB Size,特权和用户都可以访问读写
region2:4KB Size,特权用户可以访问读写,用户模式只读。如果用户模式进行写操作,则会造成data abort。
再比如一个栈保护例子:

region1:分配16K的栈区域,可读可写
region2:分配一个极小的size,例如32Byte,只读,这样如果栈溢出了,立马造成访问错误,data abort。发现问题。
1.2 background region
背景region,意思就是一个大的背景区域属性,所有区域又在此基础上进行重叠设置属性。
这样可以锁住一些没有被region 定义的区域。因为比较region 有限,最多只有16个,而region的size又有定义要求,必须是2的次幂,这样硬件做起来不复杂。
- 假如有cpu访问的地址在定义的MPU region之外,那么MPU会终止访问,没有被MPU映射的区域的访问会造成一个背景错误。
- 当然我们也可以定义一些region来修改这个属性,定义0-4G的背景区域。默认的region由上图开始介绍的。
- 如果定义了背景区域,CPU的访问又没有落在其他的11个区域,此时我们可以控制CPU对这个地址的访问。
- 当然你也可以不这样定义,通过system control register来修改这个行为。
1.3 TCM Region Peripheral Region
TCM Region ,需要配置成常规、No-shared的属性。
Peripheral Region,需要配置成 no cacheable and 不可执行的。
2、MPU的内存属性
-
strongly Ordered,必须是shared,强有序内存区域,访问的大小必须和要求的相符,访问的次数必须相符,不然就会出现问题。
- 比如一些强排序内存,必须按顺序、字节大小、次数访问,多访问一次数据已经被取走,无法获取到想要的结果。
- 而普通内存,CPU可以重新排序一些内存,使得访问效率更高,当然前提不影响指令序列行为
- 如果内存排序没有按照预设的想法,需要用到内存屏障去解决顺序问题,内存屏障看指令集学习。
-
Device,外设(内存映射的),可以被多个处理器共享或者不共享
-
Normal,常规内存可以被多个处理器共享或者不共享。

到外部存储器系统的所有处理器接口都具有相关联的存储缓冲器,这有助于提高对普通型存储器的访问吞吐量。
但是由于必须遵循排序规则,对其他类型内存的访问通常比对普通内存的访问具有更低的吞吐量或更高的延迟。比如: -
外设内存,如果需要读取,必须清空存储缓冲器,并且等待总线到设备的相关接口写入完成。
-
强排序内存,所有的访问操作,都需要清空缓冲器,并等待所有的总线访问接口完成。
综上所述,这两种内存的访问会导致中断的延迟更高,所有不是必须,不要把内存设置成device或者强排序,很影响性能。
3、MPU region属性
region 属性:
- 内存类型:强排序、外设和常规
- 是否共享:shared and Non-shared
- 不cahce:不caccheable
- 写通cache:如果没有命中,则写到cacahe,同时写到内存
- 写回cahce:如果没有命中,写到cache,后续再写到内存
- 读分配:如果没有命中,分配cache
- 写分配:如果没有命中,分配cache
每个region可以分配为不可访问,只读以及读写访问。每个region 可以设置不可执行。
4、MPU 错误类型
- background Fault:背景错误,没有落在定义的区域里面。
- permission Fault:权限错误,不符合设置的权限要求。
- Alignment Fault:对齐错误,不符合对齐要求,有些强序内存需要一定的内存对齐,比如LDM,STC多字节加载,需要DWORD对齐,如果出现不对齐的,则会对齐错误。SCTLR里面可以设置严格内存对齐访问,比如WORD地址访问等。
5、MPU配置代码
REGION_ENABLE EQU 1
CODE_BASE EQU 0x10000
REGION_4K_SIZE EQU 0x1000
FULL_ACCESS EQU 0x3 // read and write
NOR_NSHARE_WB EQU 0x0B // normal,not shared,writeback,write allocate
MOV r0,#0 // set the 0 region
MCR p15, 0, r0, c6, c2, 0
LDR r0,=CODE_BASE //set the base addr
MCR p15, 0, r0, c6, c1, 0
LDR r0, =0x0 : OR :(REGION_4K_SIZE << 1) :OR: REGION_ENABLE //set the 4k size
MCR p15, 0, r0, c6, c1, 2
LDR r0, =0x0 : OR :(FULL_ACESS << 8) :OR: NOR_NSHARE_WB //set the normal,no-shared
MCR p15, 0, r0, c6, c1, 4
参考
1、CortexR5手册。
















 599
599











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











