







前述
相信看到这篇文章的同学,都已经是研究的很深入了,理论部分不加阐述,在此总结一些自己的一些看法,方便自己以后查阅。
有关chronos的内容可以在官方的开源网站找到资料,或者在github的上的仓库中找到源代码的内容,一些内容说明也可以在博客中看到。
处理器模型
chronos 它针对的处理器,是一个叫做 SimpleScalar 教学处理器,但是好像这个官网已经不在了,所以在网上找找资料,找到了一些链接:
- https://pages.cs.wisc.edu/~mscalar/ss/tutorial.html
- https://research.cs.wisc.edu/mscalar/simplescalar.html
- https://www.ecs.umass.edu/ece/koren/architecture/Simplescalar/SimpleScalar_introduction.htm
- 找了一份copy的代码:https://github.com/shatanyumi/SimpleScalar
- 南京大学,体系结构课程,https://cs.nju.edu.cn/swang/CA_16S/index.htm
啊,我不是专门做嵌入式的,可能对这个玩意儿不是很感冒,但是大概就是一个模拟软件儿,每个单元都是最简配置,配置好各个单元的参数,然后开跑,所以可以自己康康。
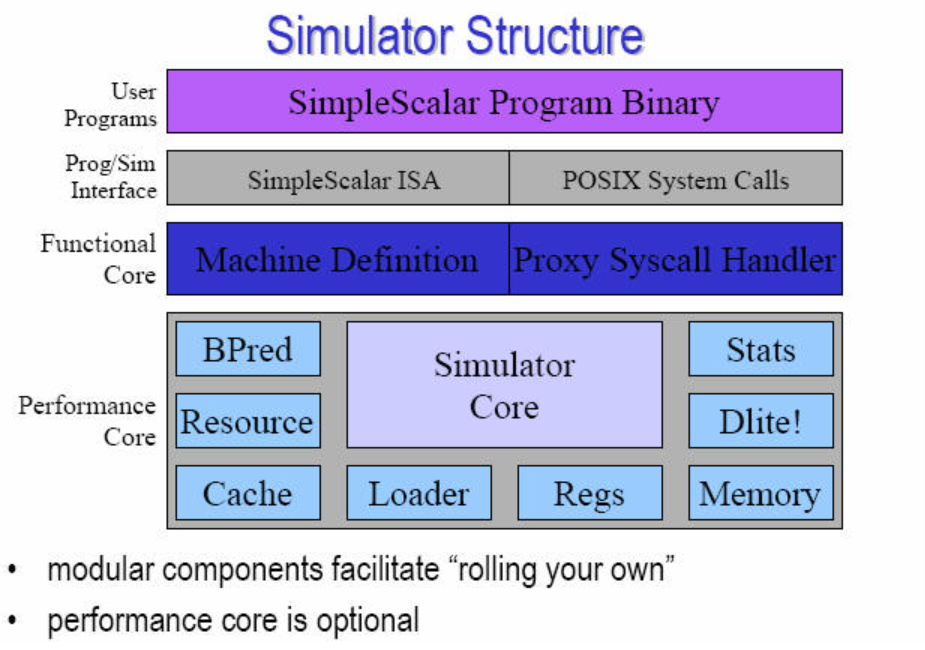
大概就是长这个样子,然后它描述的是一个叫做 PISA 的指令集,大概就是一种古老的指令集,后续可以参考来做一些移植工作。
微架构
sim-outorder.c
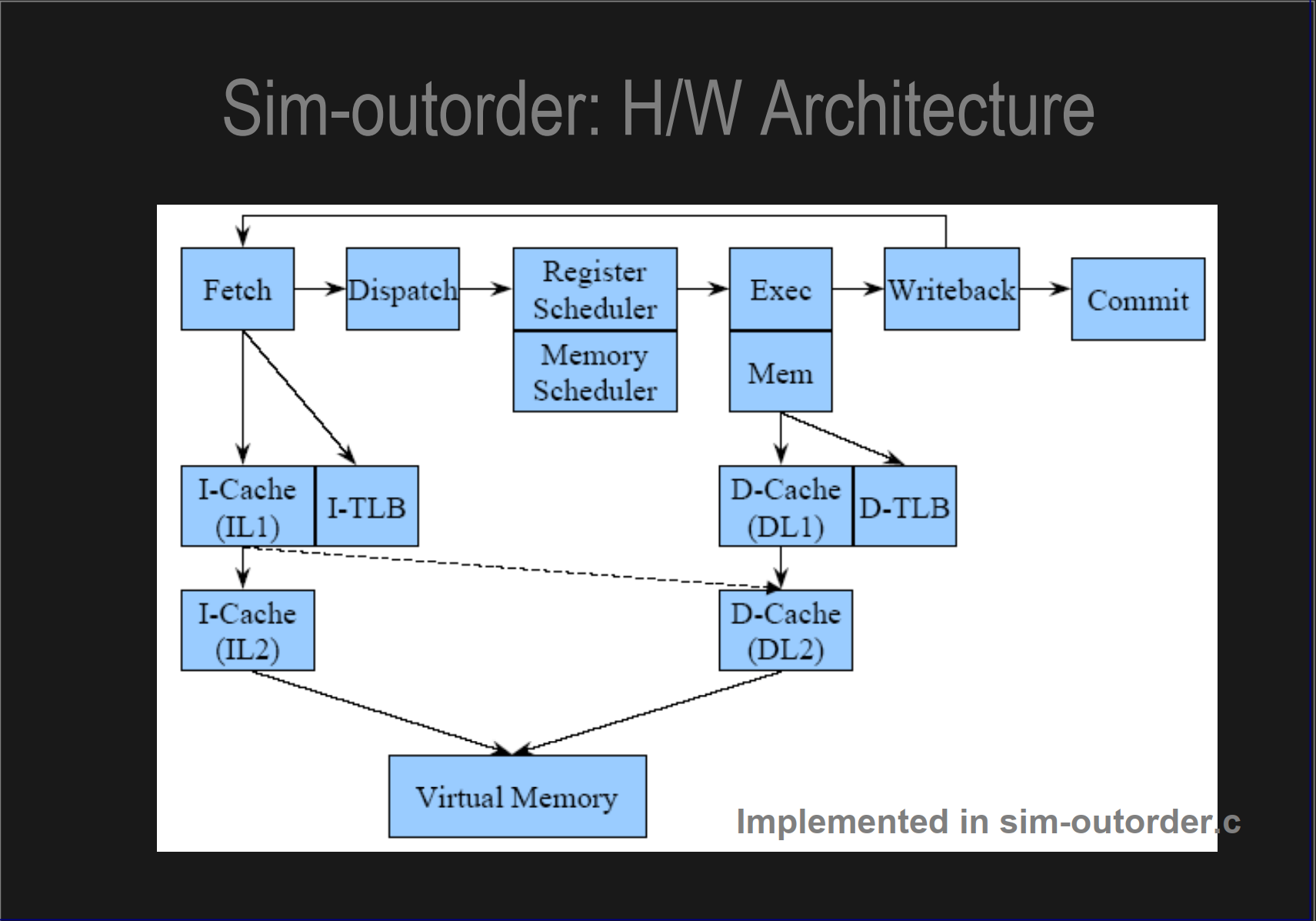
SimpleScalar的sim-outorder模拟器模拟的流水线结构,它大概做了以下的一些架构模拟:
-
指令获取(Instruction Fetch, IF): 在这个阶段,模拟器从内存中获取指令。它可能包含分支预测逻辑来猜测条件跳转指令的结果,以减少跳转指令导致的流水线停顿。
-
指令解码(Instruction Decode, ID): 指令获取后,模拟器需要解码指令,确定需要进行的操作和指令操作数。
-
寄存器读取(Register Read, RR): 解码后的指令将访问寄存器文件以获取源操作数。如果寄存器正在被之前的指令写入,寄存器重命名机制可以解决这个数据冒险问题。
-
指令发射(Instruction Issue): 发射逻辑决定哪些指令可以乱序发送到执行单元,同时保证指令间的数据依赖性和顺序一致性。
-
执行(Execute, EX): 在这个阶段,指令在相应的执行单元中执行。这包括算术运算、逻辑运算、地址计算以及其它操作。
-
内存访问(Memory Access, MEM): 访问数据缓存以加载或存储数据。如果需要的话,这个阶段也会处理缓存未命中和其他内存延迟。
-
写回(Write Back, WB): 执行完成后,结果被写回到寄存器文件,或者在乱序执行环境下,被发送到重排序缓冲区等待最终的写回。
-
提交(Commit): 当指令完成所有操作并保证按照程序顺序执行时,它会从重排序缓冲区中移除并正式修改程序状态。
各个单元参数配置
下边儿展示一部分相关的参数配置,就是每个部分模拟的参数,完了以后给它搞起来就可以跑。至于跟实际的芯片差距有多远,先不考虑,目前的考虑是实际测试套件的运行情况。

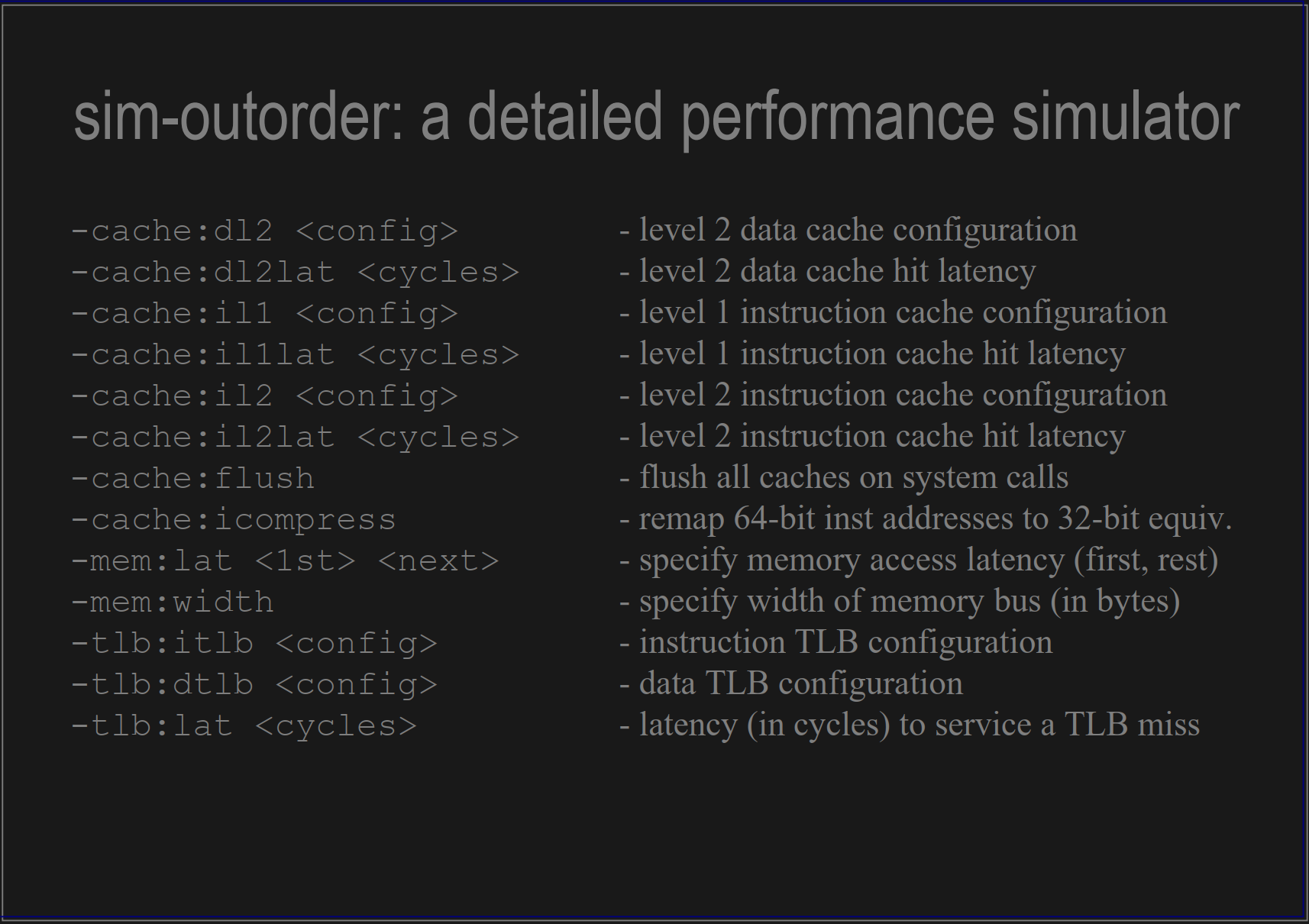

剩余的部分,在这个文件里可以详细看到:https://cs.nju.edu.cn/swang/CA_16S/simplescalar_tutorial.pdf
流程记录
大概是:ELF文件加载,进行分析,反汇编,构建特定数据结构保存每条反汇编指令的所有信息(地址,指令名称,操作数等)。
完成这些步骤过后,然后保存在一个地方,以待后续分析的时候使用。
关键文件和数据结构
首先是主目录下的 ss文件夹下边儿,描述的是simplescalar sim-outorder各个单元的运行和参数情况。主目录的其他.c .h文件则是描述的整个项目的分析过程。
ss 文件夹下面关注这几个跟二进制处理相关的文件:
- ecoff.h:二进制描述文件
- machine.def、machine.h、machine.c:指令集、各个运算单元描述文件
- my_opt.c:sim-outorder配置描述文件
- ss_isa.c、ss_isa.h、ss_machine.c、ss_machine.h、ss_readfile.c:二进制decode引擎文件
主目录下则是关注这些文件:
- common.h、common.c:通用函数描述文件
- isa.h、isa.c:decode 的时候指令描述文件
这个blog咱们看一看它是怎么处理二进制文件的,然后把它进行抽象描述,以备接下来的处理。
步骤 1 main.c 开始
涉及到处理二进制文件的,主要是以下的连个接口函数:分别是对指令集进行处理,对处理器的模拟配置进行处理。
int main(int argc, char **argv) {
...
init_isa();
...
read_opt(argc, argv);
...
}
接下来我们跟踪进入相应的文件,进行查看与描述。
步骤 2 isa.h 跟踪
首先进入 isa.h 文件,我们可以看到以下的相关代码:
#ifndef ISA_H
#define ISA_H
#include "address.h"
#include "cache.h"
这里它引用了 address.h 和 cache.h 两个头文件,它这两个头文件是用来描述地址分析、cache分析相关所需要的数据结构,在对每条指令处理的时候,需要保存一部分它们各自分析的时候所需要的信息。
接下来,是指令的类型分类,这个分类后续会用来处理 CFG 探测和构建。
仔细阅读代码,我们可以看到,它一条指令的大致类别有:计算类、内存访问类、控制流转移类,当然还有填充流水线的空指令。
// instruction types broadly in three groups:
// computation,
// memory access
// control flow transfer
enum inst_type_t {
INST_NOP = 0, // instr. doing nothing
// (1) computation
INST_ICOMP, // integer arithmetic instr.
INST_FCOMP, // floating-point arithmetic instr.
// (2) memory access
INST_LOAD,
INST_STORE,
// (3) control flow transfer
INST_COND,
INST_UNCOND,
INST_CALL,
INST_RET,
// (4) trap instr such as syscall, break, etc
INST_TRAP
};
然后是对每条指令的有用信息,进行统计,分别是:原指令、指令类别、指令汇编名称。它们具体的用法,可以在相应的具体的每个分析步骤中看到。
// each instruction type has the following fields useful for analysis
typedef struct {
int opcode; // inst opcode
int type; // inst type
char *name; // inst name
} isa_t;
最后是每条指令的详细的信息,依次可以看到的是:地址相关的、指令编号、指令大小、操作数、操作寄存器、立即数寄存器值、控制指令跳转target、抽象数据cache状态入口、抽象数据cache状态结束、一条指令的抽象寄存器状态、当前指令各cache的状态情况。这些个信息,在后续的Chronos中用到的算法需要的一些信息相关,在那个部分可以找到是如何使用这些信息的。
/* decoded instruction type */
typedef struct {
addr_t addr;
addr_t r_addr;
int op_enum; /* continuous numbered opcode
(orginal non-contenuous) */
int size;
int num_in, num_out; /* number of input/output operands */
int *in, *out; /* input/output operands (registers) */
int imm; /* Immediate integer value. For base
* indexing and immediate addressing
* mode */
addr_t target; /* target addr for control transfer inst */
acs_p** acs_in; /* abstract data cache state at the entry
* point of the instruction */
acs_p** acs_out; /* abstract data cache state at the exit
* point of the instruction */
ric_p* abs_reg; /* Abstract register value at entry point
* of an instruction */
ACCESS_T data_access; /* data access classification(hit/not known)
* for load/store instructions */
ACCESS_T inst_access; /* Instruction access classification */
ACCESS_T l2_inst_access; /* L2 Instruction access classification */
ACCESS_T u1_data_access; /* unified D/I cache access classification */
ric_p mod_addr;
} de_inst_t;
#endif
步骤 3 isa.c 跟踪
接下来跟踪 isa.c 这个文件,看看它是怎么做到的。从 main 函数进入到的接口 init_isa() ,它这样写确实没毛病,但是看起来有点呆,而且进去只有一个又是调用,而且还没有头文件引用。只能说能看就行。
isa_t *isa 这个文件,它在后续的代码中,会在代码里反复引用它,别的地方通过 extern 的方式进行链接。
#include <stdio.h>
#include "isa.h"
isa_t *isa; // info of the instruction types of the ISA
int num_isa; // number of instruction types of the ISA
// initiate ISA info
void init_isa()
{
// if SimpleScalar is used, call this to init SimpleScalar ISA info
init_isa_ss();
// dump_isa();
}
紧接着是一个 inline 函数,其实我搞不懂为啥要用这些奇技淫巧,貌似有的地方还会导致出现符号错误,所以在本地运行的时候,我选择把inline 函数都给他删除了,然后改个名字。
这个函数,是为了返回指令的类型字段,方便做 CFG 块的时候,进行查询,相当于是一个工具函数。
// return (decoded) instruction type
inline int
inst_type(de_inst_t *inst)
{
return isa[inst->op_enum].type;
}
然后紧接着是一个关于指令 latency 计算的函数,貌似这个 fu 变量没用,然后就是调用 sim-outorder 相关的计算 latency 的接口。
int max_inst_lat(de_inst_t *inst)
{
int fu;
return ss_max_inst_lat(inst);
}
最后是一个用来 debug 的函数,查看所有的指令,是否成功 decode,在 main 刚进来的时候可以看到,可以打开这个开关,所以可以在本地运行的时候打开来观察指令 decode 情况。
// dump functions for debug usage
//==============================================================================
void dump_isa()
{
int i;
for (i = 0; i < num_isa; i++)
printf("%3d: %-10s type %x\n", i, isa[i].name, isa[i].type);
}
接着跟踪接口调用,我们会进入到 ss 文件夹下边的 ss_isa.h ss_isa.c两个文件,然后在里边做进一步的 decode。
步骤 4 ss_isa.h 跟踪
我们先看看 ss_isa.h 的作用是什么,查看代码:
#ifndef ISA_SS_H
#define ISA_SS_H
/*
* configure the instruction decode engine
*/
#define DNA (0)
/* general register dependence decoders */
#define DGPR(N) (N)
#define DGPR_D(N) ((N) &~1)
/* floating point register dependence decoders */
#define DFPR_L(N) (((N)+32)&~1)
#define DFPR_F(N) (((N)+32)&~1)
#define DFPR_D(N) (((N)+32)&~1)
/* miscellaneous register dependence decoders */
#define DHI (0+32+32)
#define DLO (1+32+32)
#define DFCC (2+32+32)
#define DTMP (3+32+32)
#elif defined(TARGET_ALPHA)
/* general register dependence decoders, $r31 maps to DNA (0) */
#define DGPR(N) (31 - (N)) /* was: (((N) == 31) ? DNA : (N)) */
/* floating point register dependence decoders */
#define DFPR(N) (((N) == 31) ? DNA : ((N)+32))
/* miscellaneous register dependence decoders */
#define DFPCR (0+32+32)
#define DUNIQ (1+32+32)
#define DTMP (2+32+32)
#endif
可以看到,它这里是 sim-outorder 的寄存器相关的内容,后边儿的 TARGET_ALPHA 架构是没法用的,所以我们直接查看上边的内容即可。
大概是说,寄存器相关的 decoder 描述值,取值的时候,是什么个与或的逻辑,这个地方我也没看清楚是啥意思。然后问了一下 ChatGPT 跟我的猜想大概相同,不同的架构处理寄存器的值时不同的,寄存器它的描述数字是如何通过操作数转换的,就是这个。

步骤 5 ss_isa.c 跟踪
首先看一下相关的引用和数据结构,可以看到这个地方会用到一个 machine.h 里的内容,然后在看数据结构。
确实,*isa,num_isa 在这个地方处理了,我感觉它的数据都太过于分散了,所以重写代码的时候,我宁愿把所有的数据处理到一个地方。然后就是在 decode 的时候,会用到 machine.c 和 machine.h 中的内容,因为这些都是描述指令的,以及指令在具体的哪个处理单元U上运行的,相对应的运行时间也是保守使用指令在每个U上的最坏执行情况的最大 latency 来查询的。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include "../common.h"
#include "../isa.h"
#include "ss_isa.h"
#include "machine.h"
extern isa_t *isa;
extern int num_isa;
// BEGIN: from machine.h in SimpleScalar 3.0
// -----------------------------------------------------------------------------
#if 0
char *md_op2name[OP_MAX] = {
NULL, /* NA */
#define DEFINST(OP, MSK, NAME, OPFORM, RES, FLAGS, O1, O2, I1, I2, I3) NAME,
#define DEFLINK(OP, MSK, NAME, MASK, SHIFT) NAME,
#define CONNECT(OP)
#include "machine.def"
};
/* enum md_opcode -> opcode flags, used by simulators */
unsigned int md_op2flags[OP_MAX] = {
NA, /* NA */
#define DEFINST(OP, MSK, NAME, OPFORM, RES, FLAGS, O1, O2, I1, I2, I3) FLAGS,
#define DEFLINK(OP, MSK, NAME, MASK, SHIFT) NA,
#define CONNECT(OP)
#include "machine.def"
};
#endif
extern char *md_op2name[];
extern unsigned int md_op2flags[];
// -----------------------------------------------------------------------------
// END: from machine.h in SimpleScalar 3.0
然后,就是接着我们跟踪进来的接口函数,我看仔细看一下它在干嘛。可以看到,它根据 machined.def 文件内的规则,对每条指令进行指令二进制编码到汇编名称,以及编号的映射。然后对每条指定都进行相应的类型标记。方便后续操作的查询。
// initiate SimpleScalar ISA info by reading its machine.def file
void init_isa_ss()
{
int i, len;
num_isa = OP_MAX - 1;
isa = (isa_t *)calloc(OP_MAX - 1, sizeof(isa_t));
CHECK_MEM(isa);
for (i = 1; i < OP_MAX - 1; i++)
{
isa[i].opcode = i;
if (md_op2name[i] != NULL)
{
len = strlen(md_op2name[i]) + 1;
isa[i].name = (char *)malloc(len);
CHECK_MEM(isa[i].name);
strcpy(isa[i].name, md_op2name[i]);
}
if (md_op2flags[i] & F_ICOMP)
isa[i].type = INST_ICOMP;
else if (md_op2flags[i] & F_FCOMP)
isa[i].type = INST_FCOMP;
else if (md_op2flags[i] & F_LOAD)
isa[i].type = INST_LOAD;
else if (md_op2flags[i] & F_STORE)
isa[i].type = INST_STORE;
else if (md_op2flags[i] & F_COND)
isa[i].type = INST_COND;
else if (md_op2flags[i] & F_CALL)
isa[i].type = INST_CALL;
else if ((md_op2flags[i] & (F_CTRL | F_UNCOND | F_DIRJMP)) == (F_CTRL | F_UNCOND | F_DIRJMP))
isa[i].type = INST_UNCOND;
else if ((md_op2flags[i] & (F_CTRL | F_UNCOND | F_INDIRJMP)) == (F_CTRL | F_UNCOND | F_INDIRJMP))
isa[i].type = INST_RET;
else if (md_op2flags[i] & F_TRAP)
isa[i].type = INST_TRAP;
else
{
fprintf(stderr, "%s: unidentified instruction type!\n", isa[i].name);
exit(1);
}
}
}
紧接着是 decode 每条指令的函数,这个函数的调用是在 ss/ss_readfile.c 中,我不得不承认,写这个代码的人确实有点不够意思,它的引用做的太拉垮了,这种乱链接程序的行为是可耻的,能写出来功能代码确实牛逼,但是写的好混乱,仿佛在看*山。
它的处理逻辑大概是这样的,每条指令,根据之前定义好的翻译规则,处理出来汇编名称,指令类型,指令地址这些都保存在 *isa 这个数据结构中,然后整个程序的指令都在它这个数据结构里边儿,后续方位 isa 的地址,就可以拿到所有处理后的程序指令。
// decode the raw instr into decoded instr
void decode_inst(de_inst_t *de_inst, md_inst_t inst)
{
int op, type, offset, i, incr;
int in[3], out[2];
int num_in = 0, num_out = 0;
char *inst_format;
enum md_opcode mop;
// get inst opcode and from the opcode get its type info
MD_SET_OPCODE(mop, inst);
op = MD_OP_ENUM(mop);
de_inst->op_enum = op;
de_inst->size = sizeof(md_inst_t);
type = isa[op].type;
/* Get the instruction format */
inst_format = MD_OP_FORMAT(op);
/* sudiptac ::: Set the immediate field. Needed for
* address analysis */
while (*inst_format)
{
switch (*inst_format)
{
case 'o':
case 'i':
#ifdef _DEBUG
printf("Immediate value = %d\n", IMM);
#endif
de_inst->imm = IMM;
break;
case 'H':
#ifdef _DEBUG
printf("Immediate value = %d\n", SHAMT);
#endif
de_inst->imm = SHAMT;
break;
case 'u':
#ifdef _DEBUG
printf("Immediate value = %u\n", UIMM);
#endif
de_inst->imm = UIMM;
break;
case 'U':
#ifdef _DEBUG
printf("Immediate value = %d\n", UIMM);
#endif
de_inst->imm = UIMM;
break;
default:
/* Do nothing */
;
/* sudiptac: Default code may need to be
* modified */
}
inst_format++;
}
// if inst is a ctr transfer, compute the target addr
if (type == INST_COND)
{
offset = ((int)((short)(inst.b & 0xffff))) << 2;
de_inst->target = de_inst->addr + sizeof(md_inst_t) + offset;
}
else if ((type == INST_UNCOND) || (type == INST_CALL))
{
offset = (inst.b & 0x3ffffff) << 2;
de_inst->target = (de_inst->addr & 0xf0000000) | offset;
}
// decode the input/output info
switch (op)
{
#define DEFINST(OP, MSK, NAME, FMT, FU, CLASS, O1, O2, IN1, IN2, IN3) \
case OP: \
in[0] = IN1; \
in[1] = IN2; \
in[2] = IN3; \
out[0] = O1; \
out[1] = O2; \
break;
#include "machine.def"
#undef DEFINST
default:
in[0] = in[1] = in[2] = NA;
out[0] = out[1] = NA;
}
incr = 0;
for (i = 0; i <= 2; i++)
{
if (in[i] != NA)
{
num_in++;
// incr = 1;
}
}
incr = 0;
for (i = 0; i <= 1; i++)
{
if (out[i] != NA)
{
num_out++;
// incr = 1;
}
}
if (!strcmp(isa[op].name, "lb") || !strcmp(isa[op].name, "lh") ||
!strcmp(isa[op].name, "lw") || !strcmp(isa[op].name, "lhu") ||
!strcmp(isa[op].name, "lwl") || !strcmp(isa[op].name, "lwr") ||
!strcmp(isa[op].name, "l.d") || !strcmp(isa[op].name, "l.s"))
{
if (in[2] != NA)
num_in = 2;
else
num_in = 1;
}
if (!strcmp(isa[op].name, "sb") || !strcmp(isa[op].name, "sh") ||
!strcmp(isa[op].name, "sw") || !strcmp(isa[op].name, "swl") ||
!strcmp(isa[op].name, "swr") || !strcmp(isa[op].name, "s.d") ||
!strcmp(isa[op].name, "s.s"))
{
if (in[2] != NA)
num_in = 3;
else
num_in = 2;
}
de_inst->in = (int *)calloc(num_in, sizeof(int));
CHECK_MEM(de_inst->in);
de_inst->num_in = 0;
if (!strcmp(isa[op].name, "lb") || !strcmp(isa[op].name, "lh") ||
!strcmp(isa[op].name, "lw") || !strcmp(isa[op].name, "lhu") ||
!strcmp(isa[op].name, "lwl") || !strcmp(isa[op].name, "lwr") ||
!strcmp(isa[op].name, "l.d") || !strcmp(isa[op].name, "l.s"))
{
for (i = 0; i < num_in; i++)
de_inst->in[de_inst->num_in++] = in[i + 1];
}
else if (!strcmp(isa[op].name, "sb") || !strcmp(isa[op].name, "sh") ||
!strcmp(isa[op].name, "sw") || !strcmp(isa[op].name, "swl") ||
!strcmp(isa[op].name, "swr") || !strcmp(isa[op].name, "s.d") ||
!strcmp(isa[op].name, "s.s"))
{
for (i = 0; i < num_in; i++)
de_inst->in[de_inst->num_in++] = in[i];
}
else
{
for (i = 0; i <= 2; i++)
{
// if (in[i] != NA)
de_inst->in[de_inst->num_in++] = in[i];
}
}
de_inst->out = (int *)calloc(num_out, sizeof(int));
CHECK_MEM(de_inst->out);
de_inst->num_out = 0;
for (i = 0; i <= 1; i++)
{
// if (out[i] != NA)
de_inst->out[de_inst->num_out++] = out[i];
}
}
然后是对每条指令的最大 latency进行处理,首先是在 machine.c 中,对每个处理单元 U,没每条指令都有一个标定的latency的范围,下面的接口就是返回的每个 U 的最大处理延迟。
int ss_inst_fu(de_inst_t *inst)
{
return MD_OP_FUCLASS(inst->op_enum);
}
extern range_t fu_lat[];
int ss_max_inst_lat(de_inst_t *inst)
{
int fu;
fu = ss_inst_fu(inst);
return fu_lat[fu].hi;
}
总结
大概通过上述过程,就可以把一个可运行的二进制文件,进行decode成每条指令,一条一条的包含程序所有信息内存数据结构内保存,并且对指令进行了一定的加工。
然后即使好像在编译的时候,是不能够开起很多宏和C库的的,只能对某段程序进行分析,所以相对而言这样的指令翻译够用。















 112
112











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









