







(2014)Very Deep Convolutional Networks For Large-Scale Image Recognition
首先介绍一些小知识,VGG是Oxford Visual Geometry Group的简称,这个小组隶属于1985年成立的Robotics Research Group,这个团队研究范围很广,包括机器学习和移动机器人。
VGG网络在14年的ImageNet挑战赛中在localization和classification分别拿了第一与第二的好成绩。其最主要的贡献是使用更小的卷积核(3*3)并增加了整个模型的深度,将深度提高到了16~19层,实验表明这在一定程度上提高了模型的精度。文章最重要的部分就是讲解为什么要通过增加深度以及减小卷积核的方法来构建模型。
1. 卷积网络的配置
1.1 网络结构
- 在训练时卷积网络输入固定大小的224 × \times × 224 RGB图像,在输入前减去RGB的均值(减去数据对应维度的均值,可以消除图像中的公共部分,凸显照片中物体的差异,从而加快训练速度)。
- 在网络结构中主要使用3 × \times × 3与1 × \times × 1大小的卷积核,使用3 × \times × 3是为了获取更多的特征,使用1 × \times × 1是为了增加卷积层数,因为每层都有非线性的修正函数,因此层数增加可以增加决策函数的判别能力。
- 卷积的步长设置为1,3 × \times × 3卷积核的卷积层的padding设置为1。
- 设置有5个max-pooling层,并不是所有卷积层后面都跟着池化层,池化的大小为2 × \times × 2,步长为2。
- 模型的后面有三层是全连接层,其中第一、二层有4096个通道,第三层有1000个通道(因为有1000个物体类别)。模型的最后一层为softmax层。
- 所有的隐藏层都是用Relu这个非线性函数进行修正。网络没有使用AlexNet中提到的局部响应归一化(LRN),文中提到实验现实LRN并没有提高模型的性能。
1.2 Configuration
文章设置了6个模型(A~E),如图所示,每个模型的通道数都是从64开始,经过最大池化层后翻倍,一直到512。
其中conv<接收域的大小>-<通道的数目>,表中加粗的字体表示新添加的层。

表2说明尽管从A~E模型深度一直在增加,但是其参数的个数并没有增加很多。在OverFeat那篇论文中模型权重大小为144M。

1.3 关于模型中创新点的意义
在AlexNet中网络第一层卷积核的大小为11
×
\times
× 11,步长为4;在OverFeat文章中使用的改进的AlexNet的网络模型第一层的卷积核的大小为7
×
\times
× 7,步长为2。
在本文中提到在整个网络中使用更小的接收域3
×
\times
× 3,步长为1。两个3
×
\times
× 3的卷积层(中间没有池化层)相当于一个5
×
\times
× 5的卷积层;三个3
×
\times
× 3的卷积层相当于一个7
×
\times
× 7的卷积层。
1. 为什么使用7 × \times × 7来代替3 × \times × 3呢?
reason 1: 使用3
×
\times
× 3代替7
×
\times
× 7意味着卷积层多了2层,而每一个卷积层中都有非线性修正函数,这就相当于多使用了修正,因此会使得最后的决策函数有更强的决策能力。但是要注意,修正层并不是越多越能提高模型准确性。
reason 2: 使用三个3
×
\times
× 3比一个7
×
\times
× 7有更少的参数。假设输入输出都是C个channel。则第一种的参数个数为3
×
\times
× (3
×
\times
× 3
×
\times
× C
×
\times
× C)=27
C
2
C^2
C2;第二种为
7
2
C
2
7^2C^2
72C2=49
C
2
C^2
C2。
2. 为什么使用1 × \times × 1大小的卷积核。
实际上1 × \times × 1相当于在相同维度空间中的一个线性投影,其输入输出的channel并没有发生改变。刚刚在上面的叙述中也提到了这主要是为了增加决策函数的决策能力。
2. Classification Framework
2.1 Training
- Batch-size=256,momentum=0.9,使用权重衰减( L 2 L_2 L2penalty multipier设置为 5 ⋅ 1 0 − 4 5·10^{-4} 5⋅10−4),在前两个全连接层中使用Dropout(ratio=0.5),学习率初始化为 1 0 − 2 10^{-2} 10−2,当准确度停止增长时减少十分之一,文章中提到训练时学习率一共减少了3次,在进行370K次(74 epochs)迭代后停止学习。尽管与AlexNet相比VGG具有更大的参数量,但是却需要很少的迭代次数,这是由于VGG使用了更小的卷积核与更深的层数实现了隐式的正则化,并且在特定的层使用了预训练。
- 如何初始化网络参数:在训练层数较少的模型A(表1中A到E的模型)时直接随机初始化,较深的模型则选择将前1~4层的卷积层和最后的三个全连接层使用训练好的模型A的参数,中间的卷积层采用随机初始化。对于随机初始化的参数我们使其服从正态分布( μ \mu μ=0, σ \sigma σ=0.1),偏差直接初始化为0。
- 介绍模型架构的时候提到过模型在训练时输入的图像是固定大小的为224
×
\times
× 224,用于训练的图片都是从每张图像中随机裁剪的。
**如何获得固定大小的图像呢?**在文章中有一节专门介绍了方法,需要注意的是文章中在测试集和训练集上采用的方法是不同的,我们先来看训练集。
设S为经过各向同性处理过的训练图像中的最小边,假设我们需要得到224 × \times × 224大小的图像,那么S一定不能小于224。如果S=224,那么我们就直接使用整张图像,如果S远大于224那么我们就进行裁剪,经过裁剪后得到的图像可能只包含对象的一部分。
如何确定S的大小?
文章中提到了两个方法。第一个:固定S,这也就意味着输入的图像只有单一的尺度。在文章中使用了两个固定大小的尺寸,一个是256,一个是384;当使用S=384大小的输入图像训练模型时,为了加快训练速度使用S=256时的权重进行了预训练,并使用了一个更小的初始学习率0.001。
第二个方法是将S设置为多尺度训练,在训练时随机的从给定的范围[ S m i n , S m a x S_{min},S_{max} Smin,Smax]取S,在文章中将 S m i n S_{min} Smin设置为256, S m a x S_{max} Smax设置为512。这个想法主要是来源于现实中图像的大小也是不一致的现象。同样的,为了加快训练速度,使用已经训练的单尺度模型的参数,在其上进行微调。
2.2 Testing
在进行测试时,使用Q来表示图像的尺度,Q并不需要等于S,文章对于每个S都使用不同的Q来提高其性能。在测试时我们最后三层网络是全连接层,实际上相当于第一层变为了卷积核为7 × \times × 7大小的卷积层,后两层变为了卷积核为1 × \times × 1大小的卷积层全连接网络可以应用于整张图像(未裁剪),最后有几个通道数就意味着有几个类,对原始图像和经过裁剪、反转的图像得到的结果进行平均,这样就的到了一张图像的最终分数。
在AlexNet中通过对图像裁剪(翻转,中心加四个角,共10张图像),每张图像都需要网络计算,因此效率比较低。在OverFeat论文中使用大量的裁剪图像可以提高准确度,因为与全连接网络相比,输入的图像采样更加精细。由于不同的卷积边界条件,多裁剪图像评估是密集评估的补充:当将ConvNet应用于裁剪图像时,卷积特征图用零填充,而在密集评估的情况下,相同裁剪图像的填充自然会来自于图像的相邻部分(由于卷积和空间池化),这大大增加了整个网络的感受野,因此捕获了更多的上下文。文章提到在实践中多裁剪图像的计算时间增加并不足以证明准确性的潜在收益。但是文章还是在3个尺度上使用了裁剪图像,每个尺度上50个裁剪图像,评估了VGG网络。在OverFeat中在4个尺度上使用了144个裁剪图像。
3. Classification Experiment
文章使用的数据集为ILSVRC,训练集有1.3M 张图像,验证集有50K张图像,测试集有
00K张图像,并且测试集中每张图像都有类标签。使用的评价准则是top-1与top-5。
3.1 Single Scale Evaluation
测试集图像的大小设置规则如下,对于固定尺寸的图像Q=S,对于变换尺寸的图像Q=0.5(
S
m
i
n
+
S
m
a
x
S_{min} + S_{max}
Smin+Smax),其中S
∈
\in
∈[
S
m
i
n
,
S
m
a
x
S_{min},S_{max}
Smin,Smax]。
我们前面提到使用三个3
×
\times
× 3的卷积核代替一个7
×
\times
× 7的卷积核可以提高准确度,但是也不能盲目去替换追求效率,文章还使用了三个1
×
\times
× 1的卷积核代替了一个3
×
\times
× 3的卷积核,实验结果表明效果更差了,因此可以看出我们应该使用合适的卷积核大小,而不是盲目追求小的卷积核。
下表中展示了单一尺度的测试实验结果。

我们可以看出:1.使用LRN效果更差了;2.深度越深效果越好;训练集使用不同的输入图像的大小效果越好。
3.2 Multi-scale Evalution
考虑到训练和测试尺度之间的巨大差异会导致性能下降,用固定S训练的模型在三个测试图像尺度上进行了评估,接近于训练一次:Q = {S−32, S, S+32}。同时,训练时的尺度抖动允许网络在测试时应用于更广的尺度范围,所以用变量S
∈
\in
∈[
S
m
i
n
,
S
m
a
x
S_{min},S_{max}
Smin,Smax]训练的模型在更大的尺寸范围Q = {
S
m
i
n
S_{min}
Smin, 0.5(
S
m
i
n
S_{min}
Smin +
S
m
a
x
S_{max}
Smax),
S
m
a
x
S_{max}
Smax}上进行评估。
下图是模型在多尺度测试集上的结果。

我们可以看出与单一尺度上的相同模型相比测试集的尺度变换使得结果更好。在验证集上得到了最好的性能为24.8%/7.5%的top-1/top-5的错误率;在测试集上实现了7.3%的top-5。
3.3 多裁剪图像评估
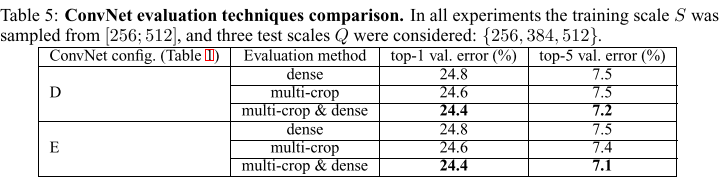
在下表中将使用Dense ConvNet评估与多裁剪图像进行评估,同时文章害通过平均soft-max的输出来评价了两种评估技术的互补性。可以看出使用多裁剪图像表现比使用密集评估要好一点,并且两种方法具有互补性,文章中假设这种差异是由于卷积边界条件的不同处理造成的。
3.4 ConvNet Fusion
将模型进行组合达到了更好的结果,其中采用表现最好的D、E模型组合使得密集评估将测试误差降到7.0%,使用多裁剪核密集组合将测试误差降到6.8%,如下表所示。

3.5 与最新技术进行比较

从表中可以看出,VGG网络明显的由于前几代的方法,在ILSVRC-2013竞赛中取得了很好的结果,并且VGG仅使用两个模型的组合明显少于其他的网络结构,虽然结果相对于分类任务的获胜者GoogleNet稍逊一些,但是在但网络性能上VGG取得了更好的成果(7.0%的测试误差),超过单个GoogleNet0.9%。VGG网络并没有篇理LeCun等人的静待你ConvNet架构,但是通过大幅度的增加深度改善了它。
4. 总结
图片参考博文(https://www.jianshu.com/p/9f77a4a4f294)

VGG拥有较小的卷积核这可以使得参数更少网络更深;
VGG使用了卷积层的堆叠,比如三个3
×
\times
× 3的卷积核相当于一个7
×
\times
× 7,使得特征提取能力更强。
VGG在训练时先训练简单的网络模型,比如A,再用A去训练后面复杂的模型,加快训练速度。
VGG去掉了LRN,验证了LRN并没有提高性能。
VGG虽然较深但是收敛速度快于AlexNet。
VGG提到的6个模型,深度逐渐增加,但是参数并没有显著增大。
VGG需要占用大量内存。
GoogleNet性能虽然优于VGG一些但是其结构太过复杂,因此VGG应用的更多一些。
















 680
680











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









