







 这篇博客详细介绍了VGG网络的结构和设计思路,包括3*3小过滤器的使用、多阶段网络配置以及1*1过滤器的作用。通过对AlexNet的改进,VGG提出了更深层次的网络,证明了深度对于提升图像识别性能的重要性。在ILSVRC上,VGG网络取得了优异的分类和定位结果。
这篇博客详细介绍了VGG网络的结构和设计思路,包括3*3小过滤器的使用、多阶段网络配置以及1*1过滤器的作用。通过对AlexNet的改进,VGG提出了更深层次的网络,证明了深度对于提升图像识别性能的重要性。在ILSVRC上,VGG网络取得了优异的分类和定位结果。
本文是牛津大学 visual geometry group(VGG)Karen Simonyan 和Andrew Zisserman 于14年撰写的论文,主要探讨了深度对于网络的重要性;并建立了一个19层的深度网络获得了很好的结果;在ILSVRC上定位第一,分类第二。
一:摘要
……
从Alex-net发展而来的网络主要修改一下两个方面:
1,在第一个卷基层层使用更小的filter尺寸和间隔;
2,在整个图片和multi-scale上训练和测试图片。
二:网络配置
2.1配置
2.1.1 小的Filter尺寸为3*3
卷积的间隔s=1;3*3的卷基层有1个像素的填充。
1:3*3是最小的能够捕获上下左右和中心概念的尺寸。
2:两个3*3的卷基层的有限感受野是5*5;三个3*3的感受野是7*7,可以替代大的filter尺寸
3:多个3*3的卷基层比一个大尺寸filter卷基层有更多的非线性,使得判决函数更加具有判决性。
4:多个3*3的卷积层比一个大尺寸的filter有更少的参数,假设卷基层的输入和输出的特征图大小相同为C,那么三个3*3的卷积层参数个数3*(3*3*C*C)=27CC;一个7*7的卷积层参数为49CC;所以可以把三个3*3的filter看成是一个7*7filter的分解(中间层有非线性的分解)。
2.1.2 1*1 filter:
作用是在不影响输入输出维数的情况下,对输入线进行线性形变,然后通过Relu进行非线性处理,增加网络的非线性表达能力。
Pooling:2*2,间隔s=2;
2.2 结构
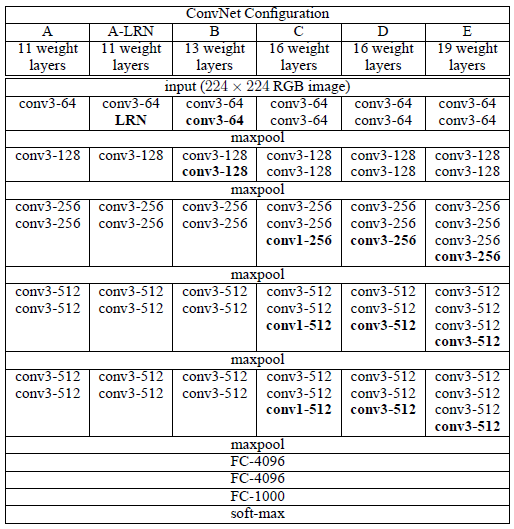
和之前流行的三阶段网络不通的是,本文是有5个max-pooling层,所以是5阶段卷积特征提取。每层的卷积个数从首阶段的64个开始,每个阶段增长一倍,直到达到最高的512个,然后保持。
基本结构A:
Input(224,224,3)→64F(3,3,3,1)→max-p(2,2)→128F(3,3,64,1)→max-p(2,2) →256F(3,3,128,1)→256F(3,3,256,1)→max-p(2,2)→512F(3,3,256,1)→512F(3,3,512,1)→max-p(2,2)→512F(3,3,256,1)→512F(3,3,512,1)→max-p(2,2)→4096fc→4096fc→10
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









