






1.Dropout出现的原因
在机器学习的模型中,如果模型的参数太多,而训练样本又太少,训练出来的模型很容易产生过拟合的现象。在训练神经网络的时候经常会遇到过拟合的问题,过拟合具体表现在:模型在训练数据上损失函数较小,预测准确率较高;但是在测试数据上损失函数比较大,预测准确率较低。
Dropout可以比较有效的缓解过拟合的发生,在一定程度上达到正则化的效果。
2.Dropout工作流程
1)首先随机(临时)删掉网络中一半的隐藏神经元,输入输出神经元保持不变
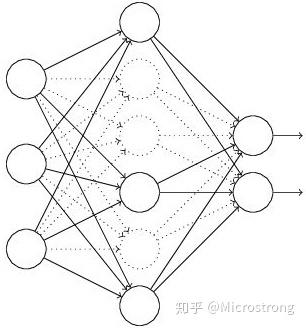
2) 然后把输入x通过修改后的网络前向传播,然后把得到的损失结果通过修改的网络反向传播。一小批训练样本执行完这个过程后,在没有被删除的神经元上按照随机梯度下降法更新对应的参数(w,b)。
(3)然后继续重复这一过程:
恢复被删掉的神经元(此时被删除的神经元保持原样,而没有被删除的神经元已经有所更新)
从隐藏层神经元中随机选择一个一半大小的子集临时删除掉(备份被删除神经元的参数)。
对一小批训练样本,先前向传播然后反向传播损失并根据随机梯度下降法更新参数(w,b) (没有被删除的那一部分参数得到更新,删除的神经元参数保持被删除前的结果)。
Dropout(0.5) 如果设置的dropout的值为0.5,则表示每个神经元有50%的概率被留下来,50%的概率被”抹去“















05-19
 520
520
520
01-19
290
290
12-27
8万+
8万+
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









