







目录
Regular Stream:传统的CNN网络,如VGG,ResNet
概述:
问题:

当前的神经网络将颜色,形状,纹理信息都一起处理,而这些信息全部包含在分割中或许会导致分割效果不理想
解决方法:
两个并行的CNN网络来解决,作者将他们分别称为regular stream和shape stream。Regular steam的结构与传统的语义分割模型相似。而Shape stream的主要作用是获取图像中的边界信息,最终将两者信息进行融合,从而得到最终的分割结果。
原文:https://arxiv.org/pdf/1907.05740.pdf
代码:https://nv-tlabs.github.io/GSCNN/
细节:

Regular Stream:
传统的CNN网络,如VGG,ResNet
输入为3*H*W的图像,输出为C*H/m*W/m的feature图像,其中m为regulat stream设置的stride值
Shape Stream:
Regular Stream中第一层的Conv的输出和图像的二阶导数图作为input,输出为语义边界(semantic boundary)

Fusion Module:
将Regular Stream和Shape Stream产生的feature map进行融合,融合采用的是Atrous Spatial Pyramid Pooling方法,具体可参考(https://blog.csdn.net/qq_21997625/article/details/87080576)

Gated Convolutional Layer:
we devise a novel GCL layer that facilitates flow of information from the regular stream to the shape stream
用CGL来帮助shape stream过滤其他信息从而只处理边界相关信息,且要注意的一点就是shape stream并不会整合来自regular steam的信息,相反,它使用GCL来停用其自身的激活,这些激活被regular steam中包含的更高级别信息认为不相关。
第一步:获取attention map
t ∈ 0,1,··· ,m( m denote the number of locations,),rt和st代表着regular streams和shape streams所产生的输入
C1x1为1x1的卷积,||代表着concatenation
第二步:通过GCL层将attention map应用在st上
就是针对上一层得到的shape分布将其与得到的注意力分布进行点乘,在加上之前的shape分布(这个就是残差计算部分)最后转置后与通道的权重核进行计算。整个过程可以认为是注意力机制的过程。
Joint Multi-Task Learning:
整体的损失函数如下:
λ1 ,λ2为超参数, standard binary cross-entropy (BCE),standard crossentropy (CE) loss
ˆ s为 GT boundaries,ˆ y为GT semantic labels
Dual Task Regularizer:
其中的G为高斯滤波器,p(y|r,s) ∈ R K×H×W denotes a categorical distribution output of the fusion module
输出代表某个像素是否属于某张图片的某个semantic boundary
作者通过预测值与真实值之间的差的绝对值作为regular steam的正则项去,其公式如下:
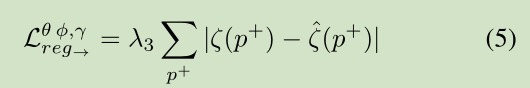
p + contains the set of all non-zero pixel coordinates in both ζ and ζˆ
作者希望确保当与GT边界不匹配时边界像素受到惩罚,并且避免非边界像素支配损失函数。所以在下面的正则项中利用的是边界预测和在边界区域的语义分割的二元性。其公式:
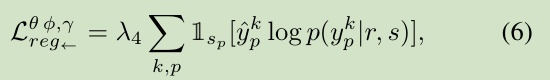
![]() thrs本文设置为0.8
thrs本文设置为0.8
最终将两个子任务的正则项进行融合得到最终双任务的正则项:
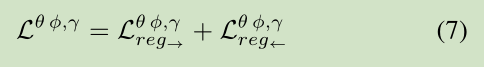















 2390
2390











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









