







1.ID3算法
输入:训练数据集D={(x1,y1),.....(xn,yn)}
过程:
(1)将数据集D喂给一个Node;
(2)若D中的所有样本同属于类别Ck,则该Node不再继续生成,并将其类别标记为Ck类;
(3)若Xi已经是0维向量,亦即已没有可选特征,则将此时D样本个数最多的类别Ck作为该Node的类别
(4)否则,按照互信息定义的信息增益

来计算第j维特征的信息增益,然后选择使得信息增益最大的特征作为划分标准,亦即:

(5)若满足停止条件,则不再继续生成并则将此时D中样本个数最多的类别Ck作为类别标记;
(6)否则,依的所有可能取值{a1,...,am}将数据集D划分为{D1,...,,Dm},使:
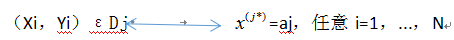
同时,将x1,...,xN的第j*维去掉,使它们成为n-1维的特征向量。
(7)对每个Dj从(1)开始调用算法
输出:原始数据对应的Node(亦即根节点)
2.C4.5算法
输入:训练数据集D={(x1,y1),.....(xn,yn)}
过程:
(1)将数据集D喂给一个Node;
(2)若D中的所有样本同属于类别Ck,则该Node不再继续生成,并将其类别标记为Ck类;
(3)若Xi已经是0维向量,亦即已没有可选特征,则将此时D样本个数最多的类别Ck作为该Node的类别;
(4)否则,按照信息增益比定义的信息增益:
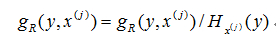
来计算第j维特征的信息增益,然后选择使得信息增益最大的特征作为划分标准,亦即:

(5)若满足停止条件,则不再继续生成并则将此时D中样本个数最多的类别Ck作为类别标记;
(6)否则,依的所有可能取值{a1,...,am}将数据集D划分为{D1,...,,Dm},使:
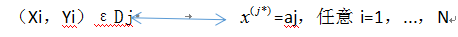
同时,将x1,...,xN的第j*维去掉,使它们成为n-1维的特征向量。
(7)对每个Dj从(1)开始调用算法
输出:原始数据对应的Node(亦即根节点)
3.CART算法
输入:训练数据集D={(x1,y1),.....(xn,yn)}
过程:
(1)将数据集D喂给一个Node;
(2)若D中的所有样本同属于类别Ck,则该Node不再继续生成,并将其类别标记为Ck类;
(3)若Xi已经是0维向量,亦即已没有可选特征,则将此时D样本个数最多的类别Ck作为该Node的类别;
(4)否则,不妨设在当前数据集中有Sj个取值 ,....,,那么:
(a)若是离散型的,则依次选取 ,....,作为二分标准aq,此时:

(b)若是连续型的,则依次选取 ,...,作为二分标准ap,此时:

按照基尼系数定义的信息增益:
gGini(y,Ajp) = Gini(y)-Gini(y|Ajp)
来计算第j维特征在这些二分标准下的信息增益,然后选择使得信息增益最大的特征和相应的二分标准作为划分标准,亦即:
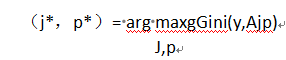
(5)若满足停止条件,则不再继续生成并则将此时D中样本个数最多的类别Ck作为类别标记;
(6)否则,依的所有可能取值{a1,...,am}将数据集D划分为{D1,...,,Dm},使:
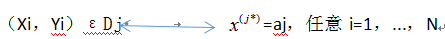
同时,将x1,...,xN的第j*维去掉,使它们成为n-1维的特征向量。
(7)对每个Dj从(1)开始调用算法
输出:原始数据对应的Node(亦即根节点















 7451
7451











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









