








最近一个做报告用的slide,比较系统的整理了一下boosting家族的数学推导和优化技巧。其中也参考了很多论文和博客,具体内容在文末参考文献。
委员会方法-集成学习
Boosting
目录
- Ensemble Learning
- AdaBoost
- GBDT & XGBoost
- LightGBM
Ensemble Learning
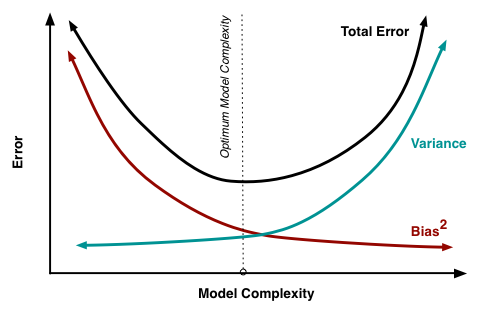
在有监督的机器学习中,衡量模型的“好坏”可以从两个方面评估,即模型预测的偏差–Bias和模型预测的方差–Variance
1.Bias是用训练数据集训练出的模型的输出与真实模型的输出值之间的差异
2.Variance是不同的训练数据集训练出的模型输出值之间的差异
Ensemble Learning
设真实的预测模型为 f f f,则样本满足 Y = f ( X ) + ϵ Y=f(X)+\epsilon Y=f(X)+ϵ,其中 ϵ \epsilon ϵ为随机误差
设我们训练得到的模型为 f ^ \hat{f} f^,则训练得到的模型 f ^ \hat{f} f^的偏差为:
B i a s 2 ( f ^ ) = ( f ^ ( X ) − Y ) 2 Bias^2(\hat{f})=(\hat{f}(X)-Y)^2 Bias2(f^)=(f^(X)−Y)2
X X X为训练集的样本
模型 f ^ \hat{f} f^的方差为:
V a r i a n c e ( f ^ ) = E [ ( Y − f ^ ( X ) ) 2 ] Variance(\hat{f})=E[(Y-\hat{f}(X))^2] Variance(f^)=E[(Y−f^(X))2]
求期望是对整个样本空间
Ensemble Learning
Bagging:对n个独立不相关的模型的预测结果取平均,方差是原来单个模型的 1 n \frac{1}{n} n1,从而在单个模型的Bias都较低(单个模型复杂度较高)的前提下,降低模型的Variance
Boosting:单个模型的Bias都不算很低(单个模型复杂度较低)的前提下,通过增添新的简单的模型有权重的修正整个模型的Bias
AdaBoost—Adaptive Boosting
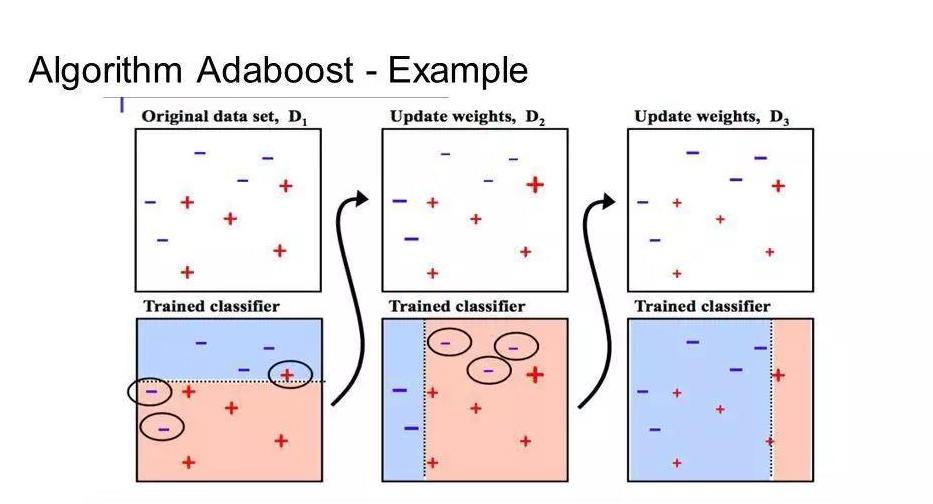
AdaBoost全称为"Adaptive Boosting"(自适应增强),由Yoav Freund和Robert Schapire在1995年提出。它是最早提出的Boosting算法,核心即使将多个分类器组合成一个强分类器。"自适应"的核心即使,在前几个弱分类器分错的样本的在下一个弱分类器的训练中会加强,一直迭代到指定数量的弱分类器或者指定的错误率。
AdaBoost数学推导
假设:
· 第 m + 1 m+1 m+1步得到的完整分类器为 f m + 1 ( x ) = f m ( x ) + a m + 1 C m + 1 ( x ; θ m + 1 ) f_{m+1}(x)=f_{m}(x)+a_{m+1}C_{m+1}(x;\theta_{m+1}) fm+1(x)=fm(x)+am+1Cm+1(x;θm+1)
其中 C m + 1 C_{m+1} Cm+1为第 m + 1 m+1 m+1个弱分类器, θ \theta θ为第 m + 1 m+1 m+1个弱分类器的参数, a m + 1 a_{m+1} am+1为第 m + 1 m+1 m+1个分类器的输出权重
· 目标损失函数 L ( a m + 1 , θ m + 1 ) = ∑ i = 1 n e − y i f m + 1 ( x i ) L(a_{m+1}, \theta_{m+1})=\sum\limits_{i=1}^n e^{-y_i f_{m+1}(x_i)} L(am+1,θm+1)=i=1∑ne−yifm+1(xi),其中 y i ∈ { − 1 , + 1 } y_i\in \{-1, +1\} yi∈{
−1,+1}
求解过程:
· 计算 m + 1 m+1 m+1步的权重 w i , m + 1 = e − y i f m ( x i ) w_{i,m+1}=e^{-y_i f_m(x_i)} wi,m+1=e−yifm(xi),则 L ( a m + 1 , θ m + 1 ) = ∑ i = 1 n w i , m + 1 × e − y i × a m + 1 C m + 1 ( x i ; θ m + 1 ) L(a_{m+1}, \theta_{m+1})=\sum\limits_{i=1}^n w_{i,m+1}\times e^{-y_i \times a_{m+1}C_{m+1}(x_i;\theta_{m+1})} L(am+1,θm+1)=i=1∑nwi,m+1×e−yi×am+1Cm+1(xi;θm+1)
· 计算 m + 1 m+1 m+1个弱分类器的参数 θ ^ m + 1 = arg min θ m + 1 ∑ i = 1 n w i , m + 1 × I { y i ≠ C m + 1 ( x i , θ m + 1 ) } \hat{\theta}_{m+1}=\mathop{\arg\min}\limits_{\theta_{m+1}}\sum\limits_{i=1}^n w_{i,m+1}\times I\{y_i \neq C_{m+1}(x_i, \theta_{m+1})\} θ^m+1=θm+1argmini=1∑nwi,m+1×I{
yi=Cm+1(xi,θm+1)}
这个目标损失函数即为第 m + 1 m+1 m+1个弱分类器的目标损失函数
· 计算加权误判率 E r r m + 1 = ∑ i = 1 n w i , m + 1 ∑ i = 1 n w i , m + 1 × I { y i ≠ C m + 1 ( x i ) } Err_{m+1} = \sum\limits_{i=1}^n\frac{w_{i, m+1}}{\sum\limits_{i=1}^n w_{i, m+1}} \times I\{y_i \neq C_{m+1}(x_i)\} Errm+1=i=1∑ni=1∑nwi,m+1wi,m+1×I{
yi=Cm+1(xi)}
· 计算 m + 1 m+1 m+1个弱分类器最终输出的权重 a ^ m + 1 = 1 2 l o g ( 1 − E r r m + 1 E r r m + 1 ) \hat{a}_{m+1}=\frac{1}{2}log(\frac{1-Err_{m+1}}{Err_{m+1}}) a^m+1=21log(Errm+11−Errm+1)
· 更新 f m + 1 f_{m+1} fm+1
AdaBoost数学推导
a ^ m + 1 \hat{a}_{m+1} a^m+1的计算原理:
当第 m + 1 m+1 m+1个弱分类器已经训练完成后, L ( a m + 1 , θ m + 1 ) = ∑ i = 1 n w i , m + 1 × e − y i × a m + 1 C m + 1 ( x i ; θ ^ m + 1 ) L(a_{m+1}, \theta_{m+1})=\sum\limits_{i=1}^n w_{i,m+1}\times e^{-y_i \times a_{m+1}C_{m+1}(x_i;\hat{\theta}_{m+1})} L(am+1,θm+1)=i=1∑nwi,m+1×e−yi×am+1
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 471
471











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









