







前言
这应该是一篇正在投稿ECCV2020的实例分割论文。就我的眼光来看,应该是可以中的。从point-based 特征出发,解决实例分割问题。其中的一些idea,和另一篇基于点的实例分割:AdaptIS有异曲同工之妙。关于AdaptIS,可以去看我的另一篇博客
另外,代码将会开源
摘要
基于点特征的idea已经开始在目标检测流行起来了,但是却很难应用在实例分割上。这有两方面的原因。
- 基于点特征的特征表示能力有限
- 容易出现misalignment。目标检测借助anchor可以解决一个特征单元属于多个目标重叠区域内的问题。但分割问题怎么办
PointINS提出了一个instance-aware convolution模块解决上面两个问题。
Method

PointINS的结构不复杂,作者明确提出,这新设计的模块不依赖于Anchor-based或者anchor-free,也就是说这个模块可以插入任何检测模型中。其中大致思路是:这个模块有两个输入,instance-aware weight 和 instance-agnostic feature。前者用于过滤掉其他目标在feature上的特征值,后者提供用于预测mask的特征图。前者从box预测中变换得到。后者通过几个卷积层得到。同时需要注意,PointINS没有Mask分支,这两个输出都来自于Box regression 分支,仅仅是因为作者认为mask也是描述目标的位置信息。这一点区别于其他IS的网络。


Instance-agnostic Feature Generation
box reg分支的到的特征图是HxWx256,然后先看下面那条路。
- channel up-scaling:单纯是一个3x3的卷积核,同时升通道,升至9x256
- depth-to-space: 目测是一个全连接层加reshape的操作。作者论文只说了reshape操作,并非直接插值。
Instance-aware Convolution
再看上面的那一条路,A是anchor数目,如果是anchor-free的框架,A为1.
经过Transforming操作,得到
I
M
I_M
IM,然后经过FC层得到
W
I
W_I
WI,圆圈里面的叉号是孪生网络常常用到的cross correlation操作。关于这个操作可以去看我另一篇关于SiamMask的论文解读。
作者提出 Instance-aware Convolution的意图是:
- chanel explosion: 如果非要基于点特征 来实现对目标的分割,该怎么做? 可以用FC层,预测一个28x28的向量,然后reshape为分辨率为28*28的特征图,作为预测结果。可是这样导致了通道数太大了。
- 另一个问题是misalignment。如果一个点特征编码了多个目标,由这个点特征预测的mask,该属于哪个目标?
接下来看看Transforming操作。
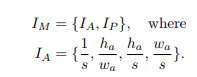
I
M
I_M
IM是由
I
A
,
I
P
I_A, I_P
IA,IP组成的。而
I
A
I_A
IA的编码是由anchor信息得到的,s是stride。如果该模块用于anchor-free的检测网络,则
I
M
I_M
IM仅仅由
I
P
I_P
IP组成。h和w是anchor的高和宽。

I
P
I_P
IP是6个值。p只的是prediction。就是预测结果和anchor之间的offset。
r
x
c
r_x^c
rxc是anchor的中心和预测框中心在x轴的偏移值。最后经过FC层得到
W
I
W_I
WI
然后将
W
I
W_I
WI作为卷积核,得到用于预测mask的特征
F
I
F_I
FI
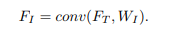
如何训练
大家一定好奇如何训练吧。毕竟一个目标身上的点这么多,该选择哪些位置的点特征作为训练样本呢。
既然是基于点特征的。那么就要像训练anchor-based 检测网络类似,目标检测需要选出正负anchor,那么PointINS就要选择正负点特征了。而事实上,这些点特征只是为了训练mask预测的,所以我们不需要负样本。如何定义positive point feature? 如果某个位置的点向量,对应的anchor和预测结果的IOU都大于0.5,那么这个位置的点特征就是正样本,用于训练mask。训练阶段,每张图随机选择满足条件的125个这样的点。而实际上,满足这样的点,在所有的FPN层上,加起来有2W个。
所以,个人认为,PointINS的精度依赖于检测网络,训练应该是分步训练的,先训练检测,后训练这个模块、
Experiments


和AdaptIS的区别和联系
作为都是point-based的IS网络,他们的联系有一下几点:
- dynamic weight:PointINS使用instance-aware weight 加权 feature map,进而得到mask;ApdatIS使用AdaIN获得每个目标的特征向量,凭借该向量重新改变特征图的均值和方差,来获得mask
- 都是一种范式:backbone输出整张图的特征图,寻找某个目标的特征向量,过滤掉特征图其他目标的特征。PointINS使用的过滤方法是加权,且特征向量来自于box预测。AdaptIS使用的adaIN。
区别:
- AdaptIS使用额外输出,需要用户提供一个点,指明哪个目标需要分割; PointINS不需要额外输出,依赖于目标检测,可以获知有哪些目标需要分割。有几个box预测出来了,根据box获得instance-aware weight即可获得目标的mask














 2425
2425











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









