






寒假在家使用自己电脑时,浏览器出现意外关闭,一次以为没什么,这两天出现好几次,时不时地来一下,太搞心态了,必须给他解决了。
一番检查后,是浏览器自动安装了一款截屏的扩展,浏览器识别到该插件是包含病毒信息的,启动防御机制,关闭浏览器了。
自己也没有设置什么东西呀,为什么会自动安装扩展呢,手动删除了,一段时间后还是会安装回来,只要自动安装了,还是会自动关闭浏览器,就离谱。
点到浏览器的设置里面发现最下面有一个“由你的组织管理”,这好像在系统更新前是没有的。
点进这个组织管理,可以看到某些策略是由组织管理的,看到自己的列表里有一个好像名叫“ExtensionInstallAllow…”的策略,只能查看,不能修改,并强制执行的。从名字上看感觉这个和自己的插件自动安装有关,逐渐接近问题答案了。
在Microsoft交流论坛上找到相关的解决方案,但是并不适用自己的问题。
参考其他方案, “此电脑”–“属性”–“系统保护”–“计算机名”–“网络ID”–选择“这是一台家庭计算机,不是办公网络是一部分”–应用–重启计算机;
重置浏览器;
修复浏览器;
卸载浏览器并重装;
均无济于事。
最后还是回到自己遇到的问题上来:
1. edge://policy 或者 chrome://policy 查看浏览器的策略名

2. win + r ,输入regedit 打开注册表编辑器,选择“计算机”

3. 选择“编辑”,“查找”,输入策略名进行查找
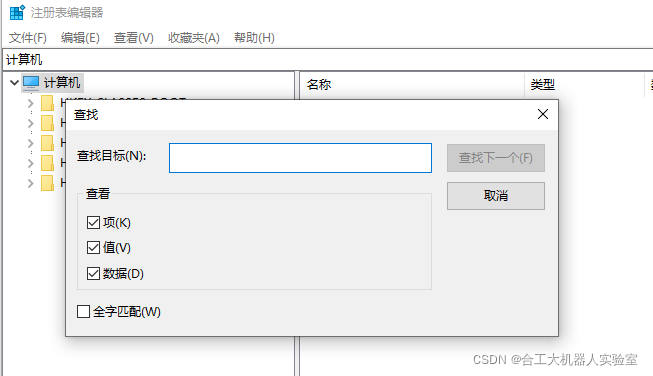
4. 查找到相应的策略名,删除。
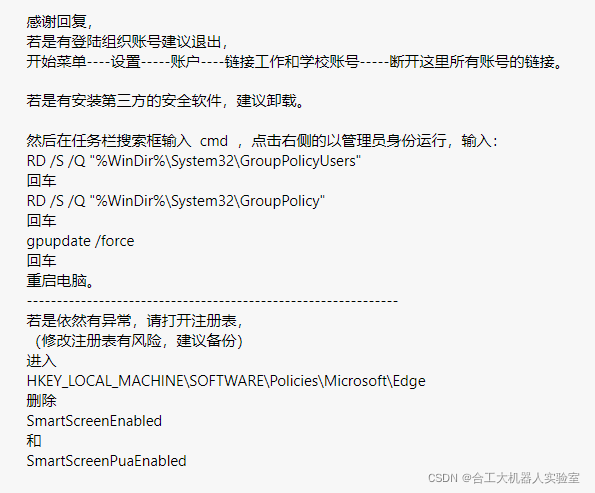
1.在这里提一下,跟Microsoft论坛上的解决方案差不多,但是不同电脑的策略存放目录稍有不同,直接按照提供的目录去删除,大概率出现找不到的情况,此处选择查找的方法,查找到该位置。
2.删除相应策略名下的内容,基本就可以了,当然也要根据自己的情况,谨慎删除
5. 重启计算机,摆脱组织的管理了。
用了几天浏览器,没再遇到这样的情况了,应该算是解决了,特来记录,Nice!
2022.2.9更新
用过一段时间后,发现edge浏览器还是会出现“由你的组织管理”,这个问题没能彻底解决。
这是由于升级后的windows系统添加并配置了 extensioninstallallowlist 这一策略,每次开机都会检查注册表的完整性,删除了也会自动添加上。浏览器防火墙会有对于扩展的安全检测,一旦被认定有包含病毒信息,就会自动关闭浏览器,其中 screenshot pro即是一个认定为不安全的扩展。
浏览网上其他的解决方案,有建议
- 关掉windows的自动更新策略
- 关闭自动检测注册表完整性的策略
- 也有修改 extensioninstallallowlist 这一策略值的。
本人对修改注册表中的策略值持保守建议,目前解决方法是:关闭Windows浏览器防火墙,浏览器虽然还是由组织管理,但使用起来还算稳定,没有再出现意外关闭的情况了,但是不建议这样操作

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









