







比赛介绍
工业缺陷检测是当前深度学习落地的热门项目,其中瓷砖生产过程中的“质量检测环节”需要检测出瓷砖表面的瑕疵,目前比较依赖于人工,效果和效率都层次不齐。
最近天池上线的广东工业赛事针对瓷砖表面瑕疵进行智能检测,要求选手们相应的算法,尽可能快与准确的给出瓷砖疵点具体的位置和类别,主要考察疵点的定位和分类能力。

在本篇文章中,主要为大家介绍选择yolov5作为基线的方案,供大家参考。
基于yolov5的方案
线上结果:
-
切成 640x640 滑动窗口预测,耗时<1.5 h, 平均一张图<3s! 线上50.
-
长边resize到6400预测,平均一张图耗时:0.6 s. 线上55+
大家们都在疯狂卷mmdet,毕竟two-stage为王,但是如果没有算力可以考虑下yolov5。而且考虑到速度和精度的均衡(复赛要求<3s),如果使用two-stage的单图大尺度预测,个人感觉上限有限,而且比赛最后都是拼细节。所以肯定会朝着切图(特别是测试时切图)的方向发展。如果two-stage妄图切图到小块然后预测,时间限制肯定会劝退大部分two-stage模型,这也是选择yolov作为基线的原因!
原始图片尺度很大,目标相对原图尺度很小,这不利于模型学习,所以无论是在线随机crop还是离线crop制作训练集,都避免不了处理切图的问题。在线切图可以参考mmdetection的官方实现RandomCrop
离线切图:和在线切图一致,参考yolt切图方式,只是要将切好的图片和新标注都保存起来。本文中训练yolov5使用的是离线切图制作的voc格式数据集
-
假设需要切图的大小为:640x640
-
overlap比例:0.2
-
则步长为512
-
从原图左上角开始切图,切出来图像的左上角记为x,y,
-
那么可以容易想到y依次为:0,512,1024,....,5120.但接下来却并非是5632,因为5632+640>6000,所以这里要对切图的overlop做一个调整,最后一步的y=6000-640.(这是最关键的一点!!!)
-
标签变化:切图对应的标签变化就是一个简单的加减(左上角坐标)几何变化
-
对于所有的原始数据集,切成640x640,再剔除纯背景,大约会生成1.9w+的训练图像
-
预测的时候也是将图片切成640x640.这样一张图片大约会变成150~200张小图,而yolov5l的FPS在v100上大约为256. 所以可以保证在3s内可以完成一张图的预测。
切图后训练数据可视化:

训练
-
yolov5l
-
训练尺度:640x640
-
30 epoch ; 0.1比例验证(训练未见过的图片的切片) ,严格的验证还需要算上切出来的背景块。
-
线下:mAP@0.5: 60
-
2卡2070s训练,训练时间<6hour。
测试
单卡:RTX 2070s
-
1 切成 640x640 滑动窗口预测,耗时<1.5 h, 平均一张图<3s! 线上50.(低于原图预测的结果我是没想到的,没有NMS后处理?或者代码写错了?或者滑窗就是不行?还是一些后处理细节没考虑清楚?)
-
2 长边resize到6400预测,平均一张图耗时:0.6 s. 线上55+
代码运行说明:
python convert_to_voc.py #先将原始数据转为VOC格式的标注
python make_slice_voc.py #将上述图片切为小图,重新制作为voc.
python convert_voc_to_v5txt.py #将voc标注转换为yolov5的官方格式.
python make_yolov5_train_val.py #制作yolov5的train/val.
总结
-
虽然检测比赛都是mmdet的天下,但是我相信在复赛有时间限制的情况下,加上这个赛题的特殊性,yolov5还是有比较强的竞争力的,特别是比赛后期。
-
V5提升空间很大:(1)本baseline使用两卡2070s小尺度单图训练,本身具有局限性;(2)除了yolov5l还有更强的v5x可选; (3)预测部分很粗糙,没有充分发挥yolov5速度快的特点;(4)结果后处理可以进一步探索
-
关于切图滑窗预测, 如果处理好细节,切图预测理论上应该是会好于原图预测。特别是针对那些背景块,需要特殊处理,不然会引入极多的FP,必然导致mAP降低。关于overlap的问题,可以借鉴模型融合的方式,使用NMS或者WBF来对最后的重叠进行一个再处理。
-
关于单图预测:考虑推理速度尺度,中心裁剪推理,因为所有图都有灰边背景,统计下这些背景的边框范围,进行centerCrop预测结果应该会更好。当然有更简单的方式,以直接在推理结果上面进行后处理。
训练/验证可视化
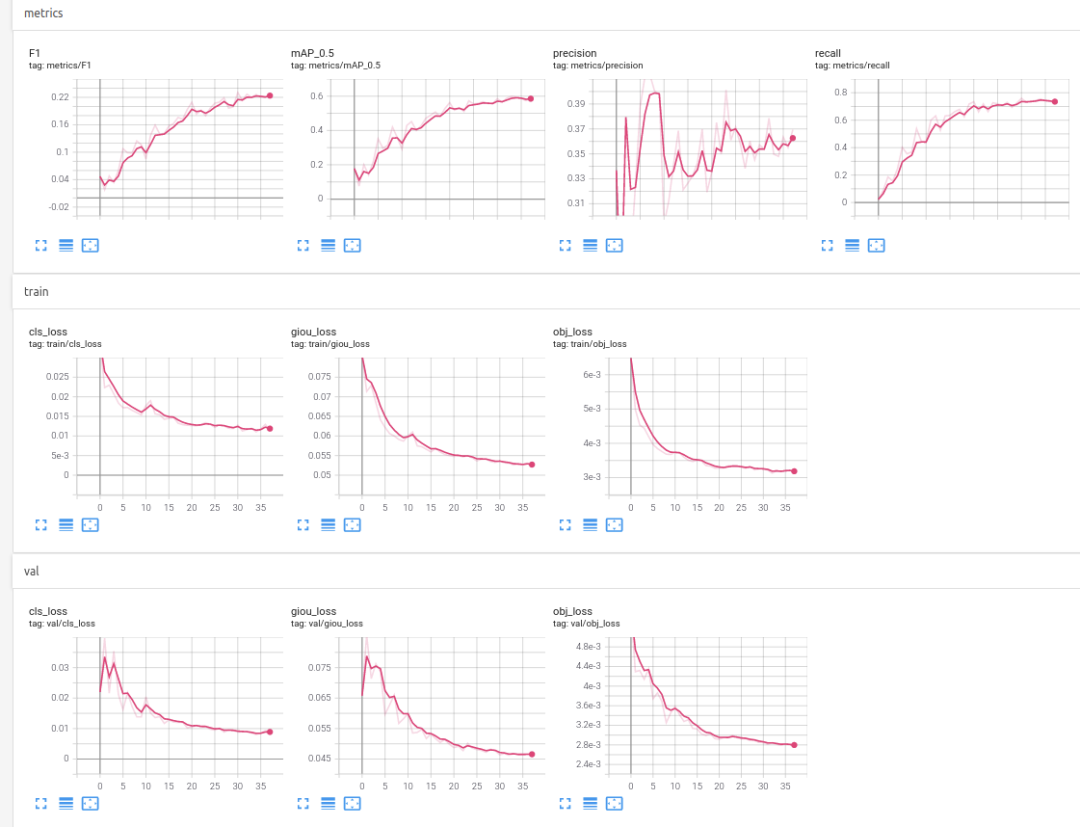
tensorboard
比赛地址:
https://tianchi.aliyun.com/s/bc97f977ae47dcfa4b07c027cd28d907(复制粘贴或阅读原文)

















 2622
2622

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









