







常见图像处理的任务
- 分类(核心基础)
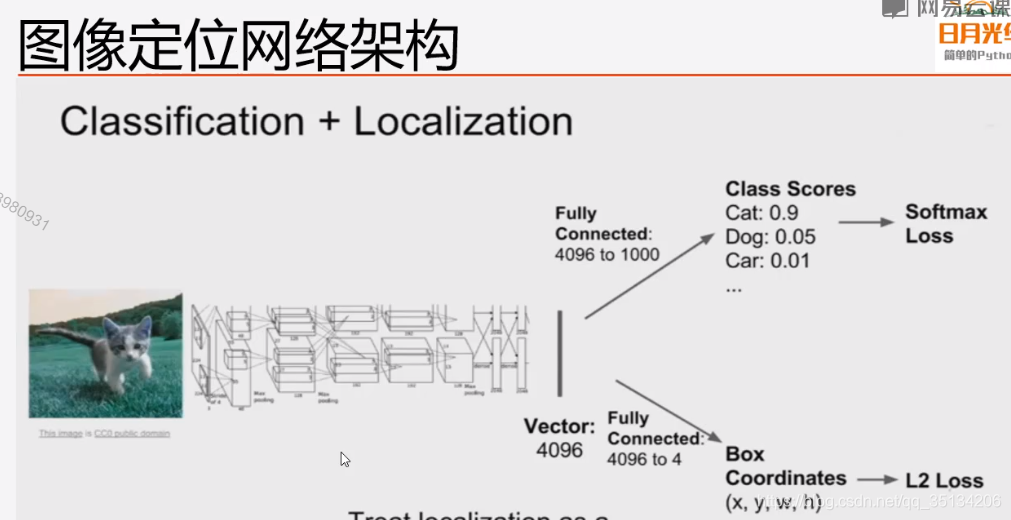
- 分类+定位
知道对象是什么,还要确定对象所处的位置。在对象附近画一个边框。 - 语义分割
对图像中的像素点进行分类,区分图像中每一个像素点。 - 目标检测
回答图片中有什么,在什么位置。用矩形框框住。 - 实例分割
目标检测与语义分割的结合。需要精确到物体的边缘。
图像定位
输出四个数字(x,y,w,h),图像中某一个点的坐标(x,y),以及图像的宽度和高度。
Oxford-IIIT数据集


图像定位示例
图片文件和对应文件信息如下

# 获取一张图片
img = tf.io.read_file('D:/Desktop/数据集/图片定位与分割数据集/images/images/Abyssinian_1.jpg')
# 对图片解码
img = tf.image.decode_jpeg(img)
# 显示图片
plt.imshow(img)

# 读取xml文件中的内容
xml = open('D:/Desktop/数据集/图片定位与分割数据集/annotations/annotations/xmls/Abyssinian_1.xml').read()
# 创建选择器
sel = etree.HTML(xml)
# 解析文件中的图片数据
width = int(sel.xpath('//size/width/text()')[0])
height = int(sel.xpath('//size/height/text()')[0])
xmin = int(sel.xpath('//bndbox/xmin/text()')[0])
xmax = int(sel.xpath('//bndbox/xmax/text()')[0])
ymin = int(sel.xpath('//bndbox/ymin/text()')[0])
ymax = int(sel.xpath('//bndbox/ymax/text()')[0])
plt.imshow(img)
# 绘制矩形框,((x,y),h,w) fill指定是否填充矩形框
rect = Rectangle((xmin,ymin),(xmax-xmin),(ymax-ymin),fill=False,color='red')
# 获取当前图像
ax = plt.gca()
# 添加矩形框
ax.axes.add_patch(rect)

图像定位与分类实例
对猫狗图像的头部进行定位并显示,并且将图像中的猫和狗进行分类,数据集同上。
保存了训练好的模型、可视化结果、打印了训练过程的log
实例代码:
导入需要使用到的库文件
import tensorflow as tf
import matplotlib.pyplot as plt
from lxml import etree # 解析xml文件
import numpy as np
import glob
from matplotlib.patches import Rectangle # 绘制矩形框
from tensorflow.keras.callbacks import CSVLogger
处理输入数据
def process_data():
'''
创建输入管道
:return: 训练数据集和验证数据集
'''
# 读取所有的图像
images = glob.glob(
"F:\\dataset\\图片定位与分割\\images\\*.jpg") # images[0] ===> F:\dataset\图片定位与分割\images\Abyssinian_1.jpg
# 获取图像对应的目标xml文件
xmls = glob.glob(
"F:\\dataset\\图片定位与分割\\annotations\\xmls\\*.xml") # xmls[0] ===> F:\dataset\图片定位与分割\annotations\xmls\Abyssinian_1.xml
# 获取所有解析文件的名称
names = [x.split('xmls\\')[1].split('.')[0] for x in xmls]
# 取出有对应xml文件的图片作为训练集
imgs_train = [img for img in images if img.split('images\\')[1].split('.')[0] in names]
# 取出没有对应xml文件的图片作为测试集
imgs_test = [img for img in images if img.split('images\\')[1].split('.')[0] not in names]
# 根据文件名称进行排序
imgs_train.sort(key=lambda x: x.split('images\\')[1].split('.')[0])
xmls.sort(key=lambda x: x.split('xmls\\')[1].split('.')[0])
# 获取所有xml文件的中的头部位置信息,位置信息作为图片信息的标签 ===> [xmin, ymin, xmax, ymax]
site_labels = [xml_to_sitelabels(path) for path in xmls]
# 将获取到的标签分为四个单独的列表 ===> zip(*)是zip的逆操作
xmins, ymins, xmaxs, ymaxs = list(zip(*site_labels))
# 将xmins等转为array
xmins = np.array(xmins)
ymins = np.array(ymins)
xmaxs = np.array(xmaxs)
ymaxs = np.array(ymaxs)
# 获取所有的分类标签cat ===> 1,dog ===> 0
class_labels = [xml_to_classlabels(path) for path in xmls]
# 创建标签数据集,包括定位标签和分类标签
label_dataset = tf.data.Dataset.from_tensor_slices(((xmins, ymins, xmaxs, ymaxs), class_labels))
# 创建图片数据集
image_dataset = tf.data.Dataset.from_tensor_slices(imgs_train)
image_dataset = image_dataset.map(load_image)
# 将图片和标签合并
dataset = tf.data.Dataset.zip((image_dataset, label_dataset))
dataset = dataset.shuffle(len(dataset))
# 将dataset数据集中20%拿出来做验证集,80%做训练集
train_size = int(len(dataset) * 0.8)
val_size = len(dataset) - train_size
train_dataset = dataset.skip(val_size)
val_dataset = dataset.take(val_size)
# 对train_dataset和val_dataset做预处理
train_dataset = train_dataset.repeat().shuffle(len(train_dataset)).batch(32)
val_dataset = val_dataset.batch(32)
return train_dataset, val_dataset, train_size
从xml文件中解析定位信息,生成定位信息标签
def xml_to_sitelabels(path):
'''
解析xml文件中的信息,将xml中标记的头部位置的信息处理后返回
:param path: xml文件存储的路径
:return: xmin,ymin,xmax,ymax与图像尺寸的比值
'''
# 读取xml文件
xml = open(path).read()
# 创建一个选择器
sel = etree.HTML(xml)
# 解析xml文件中的图片数据
width = int(sel.xpath('//size/width/text()')[0])
height = int(sel.xpath('//size/height/text()')[0])
xmin = int(sel.xpath('//bndbox/xmin/text()')[0])
xmax = int(sel.xpath('//bndbox/xmax/text()')[0])
ymin = int(sel.xpath('//bndbox/ymin/text()')[0])
ymax = int(sel.xpath('//bndbox/ymax/text()')[0])
return [xmin / width, ymin / height, xmax / width, ymax / height]
从xml文件中解析类别信息,生成分类信息标签
def xml_to_classlabels(path):
'''
解析xml文件获取所有的分类标签
:param path: xml文件存储的路径
:return: 分类标签编码 cat ===> 1,dog ===> 0
'''
# 读取xml文件
xml = open(path).read()
# 创建一个选择器
sel = etree.HTML(xml)
# 解析xml文件中的图片分类数据
class_label = sel.xpath('//object/name/text()')[0]
# 对分类标签进行编码 cat ===> 1,dog ===> 0
return int(class_label == 'cat')
图片解码及预处理
def load_image(path):
'''
加载图片数据
:param path: 图片存储的路径
:return: 处理过的图片
'''
img = tf.io.read_file(path)
img = tf.image.decode_jpeg(img, channels=3)
img = tf.image.resize(img, (224, 224))
# 归一化到-1到1之间
img = img / 127.5 - 1
return img
显示图像以及定位信息
def show(dataset, num):
'''
显示图片以及定位效果
:param dataset: 数据集
:param num: 需要显示的图片数量
'''
for imgs, labels in dataset.take(num):
for i in range(num):
# 显示图片 ===> 需要将tensor array对象转换为image
plt.imshow(tf.keras.preprocessing.image.array_to_img(imgs[i]))
xmin, ymin, xmax, ymax = np.array(labels[0][0])[i], np.array(labels[0][1])[i], np.array(labels[0][2])[i], \
np.array(labels[0][3])[i]
# 按照图片尺寸获取对应比例的xmin, ymin, xmax, ymax
xmin, ymin, xmax, ymax = xmin * 224, ymin * 224, xmax * 224, ymax * 224
# 绘制矩形框((x,y),h,w) fill ===> 指定是否填充矩形框
rect = Rectangle((xmin, ymin), (xmax - xmin), (ymax - ymin), fill=False, color='red')
# 获取当前图像
ax = plt.gca()
# 给当前图像添加矩形框
ax.axes.add_patch(rect)
plt.show()
创建图像定位与分类模型
def createModel():
'''
创建图像定位模型
:return: 创建好的模型
'''
# 使用预训练网络
xception = tf.keras.applications.Xception(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
# 将预训练网络设置为不可训练
xception.trainable = False
# 添加自定义网络层
inputs = tf.keras.layers.Input(shape=(224, 224, 3))
x = xception(inputs)
x = tf.keras.layers.GlobalAveragePooling2D()(x)
x = tf.keras.layers.Dense(2048, activation='relu')(x)
x1 = tf.keras.layers.Dense(256, activation='relu')(x)
# 回归
xmins = tf.keras.layers.Dense(1)(x1)
ymins = tf.keras.layers.Dense(1)(x1)
xmaxs = tf.keras.layers.Dense(1)(x1)
ymaxs = tf.keras.layers.Dense(1)(x1)
prediction_sites = [xmins, ymins, xmaxs, ymaxs]
x2 = tf.keras.layers.Dense(256, activation='relu')(x)
prediction_classes = tf.keras.layers.Dense(1, activation='sigmoid', name='class')(x2)
model = tf.keras.models.Model(inputs=inputs, outputs=[prediction_sites, prediction_classes])
model.summary()
return model
对模型进行配置和编译
def train(model, train_dataset, train_size, val_dataset, epochs, BATCH_SIZE):
'''
配置、编译模型
:param model: 模型
:param train_dataset: 训练数据集
:param val_dataset: 验证数据集
:param epochs: 训练次数
:return: 训练结果
'''
# mse ===> 回归问题常用损失函数 mae ===> 绝对损失计算
model.compile(tf.keras.optimizers.Adam(learning_rate=0.0001),
loss={'dense_2': 'mse', 'dense_3': 'mse', 'dense_4': 'mse', 'dense_5': 'mse',
'class': 'binary_crossentropy'},
metrics=['mae', 'acc'])
# 保存训练结果
loggger = CSVLogger('training.log', append=False)
train_steps = train_size // BATCH_SIZE
val_steps = len(val_dataset) // BATCH_SIZE
history = model.fit(train_dataset, epochs=epochs, steps_per_epoch=train_steps, validation_data=val_dataset,
validation_steps=val_steps, callbacks=loggger)
# 保存模型
model.save('site_and_class_model.h5')
return history
可视化模型训练结果
def showHistory(history):
'''
绘图显示模型训练结果
:param history: 模型训练结果
'''
loss = history.history['loss']
print(history.history.keys())
class_acc = history.history['class_acc']
epochs = range(EPOCHS)
plt.figure()
plt.plot(epochs, loss, 'r', label='Training loss')
plt.plot(epochs, class_acc, 'b', label='Training class_acc')
plt.title('Training and validation Loss and Class_acc')
plt.xlabel('Epoch')
plt.ylabel('Loss and Class_acc Value')
plt.legend()
plt.savefig('loss_and_acc.png')
plt.show()
使用训练好保存的模型进行预测
def modelPredict(dataset, num):
'''
使用保存的模型进行预测
:param dataset: 需要预测的数据集
:param num: 预测的数量
'''
'''
使用保存的模型进行预测
:param dataset: 需要预测的数据集
'''
# 加载保存好的模型
model = tf.keras.models.load_model('site_and_class_model.h5')
# 创建一张画布
for img, _ in dataset.take(1):
pre = model.predict(img)
for i in range(num):
plt.imshow(tf.keras.preprocessing.image.array_to_img(img[i]))
xmin, ymin, xmax, ymax = pre[0][0][i] * 224, pre[0][1][i] * 224, pre[0][2][i] * 224, pre[0][3][i] * 224
# 绘制矩形框((x,y),h,w) fill ===> 指定是否填充矩形框
rect = Rectangle((xmin, ymin), (xmax - xmin), (ymax - ymin), fill=False, color='red')
# 获取当前图像
ax = plt.gca()
# 给当前图像添加矩形框
ax.axes.add_patch(rect)
if pre[1][i] > 0.5:
# 给当前图像添加title
plt.title('cat')
else:
plt.title('dog')
plt.show()
主方法
if __name__ == '__main__':
# 获取训练数据集和验证数据集
train_dataset, val_dataset, train_size = process_data()
EPOCHS = 100
BATCH_SIZE = 32
# 显示指定数量的图片
show(train_dataset, 3)
# 创建图像定位模型
model = createModel()
# 模型配置和训练
history = train(model, train_dataset, train_size, val_dataset, EPOCHS, BATCH_SIZE)
# 绘制模型训练结果
showHistory(history)
# 使用保存好的模型进行预测
modelPredict(train_dataset, 32)
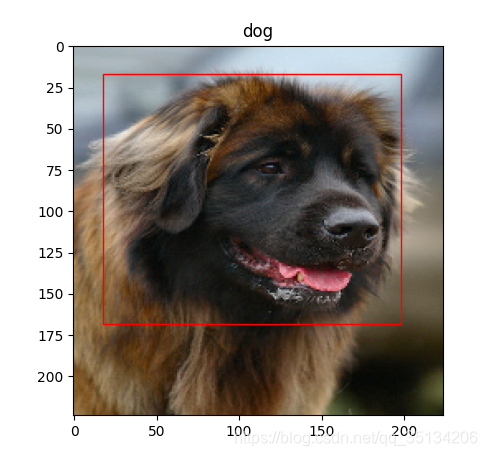
实例预测效果:

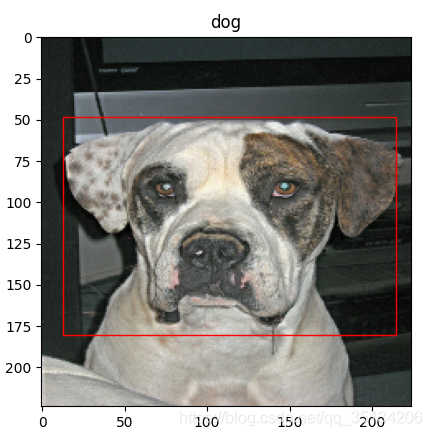
图像定位的优化
预测图像位置本质上是一个回归问题,直接回归出位置,有两个缺点:
- 回归位置不精确
- 泛化能力不好
- 目前算法只能预测单个实例
优化
- 先大后小:
先在整张图片预测出关键点,然后再再预测出的关键点周边,进行二次预测。 - 滑动窗口的方式:
用一个小的窗口在图片上滑动,每一次做两个预测:(1)是否有关键点(2)关键点位置。 - 针对不定个数的预测问题:
可以先检测多个对象,再在多个对象上分别回归出位置 - 尝试使用全卷积网络,去掉全链接层,变回归为分类问题
- 自己去探索别的网络
图像定位的评价
使用IOU来评价图像定位的精度IOU的全称为交并比(Intersection over Union)。
IOU计算的是“预测的边框”和“真实的边框”的交集和并集的比值。
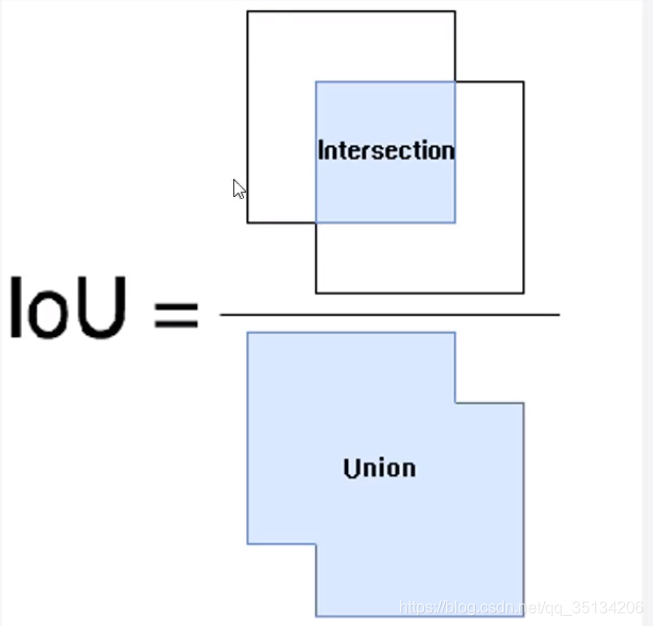
IOU的取值范围为[0,1]
图形定位的应用


该实例代码和用到的数据集已全部上传至GitHub 代码和数据集.存放在pycharm projects文件夹中。















 336
336











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









