






官方说明:vLLM V1: A Major Upgrade to vLLM’s Core Architecture
GitHub: https://github.com/vllm-project
本文基于官方说明和v0.8.2源码学习v1架构和说明
1. 优化的执行循环和 API 服务器
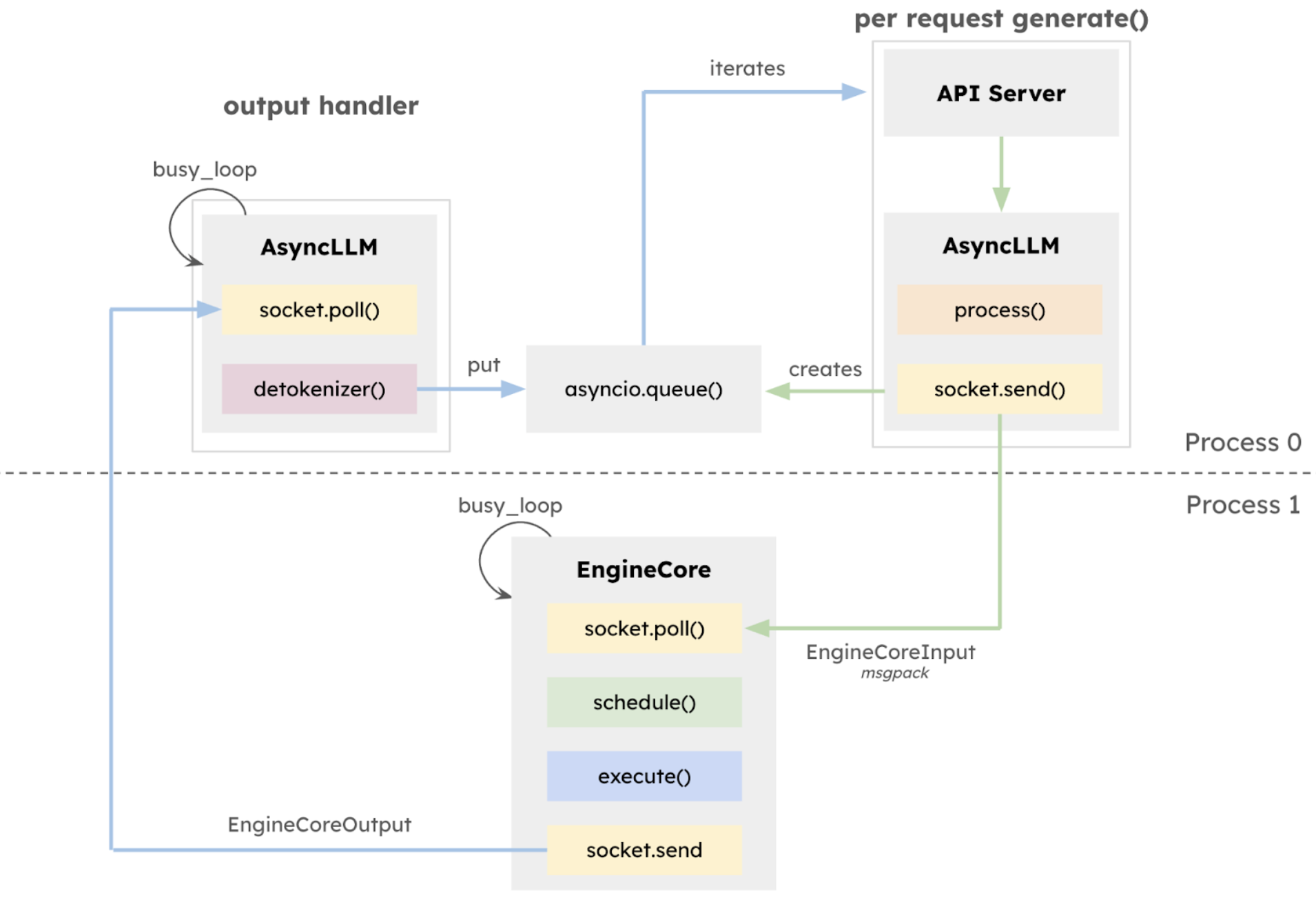
对于一次用户请求,完整的流程包括:接受用户请求、对请求进行预处理、分词、多模态输入处理、对请求调度、在GPU上执行推理、对结果进行de-tokenize、向用户流式传输响应
这整个过程都是在同一个进程中执行的,且除了中间的在GPU上推理,其余的步骤都是在CPU上执行的,并且它们之间还是串行的,因此对于GPU推理很快的任务来说,CPU 开销变得越来越明显。因此最好做一些重叠,减少整体时间。
v1 创建了一个隔离的EngineCore 执行循环,该循环专门专注于调度器和模型执行器。 这种设计允许 CPU 密集型任务(如 token 化、多模态输入处理、反token化和请求流式传输)与核心执行循环之间更大的重叠,从而最大化模型吞吐量。
EngineCore代码

这是 vLLM 引擎的核心类,负责管理和执行大语言模型的推理过程。
主要功能:
def add_request(self, request: EngineCoreRequest)
- 添加新的推理请求到调度器
- 处理多模态输入的缓存
- 初始化结构化输出的语法编译
def step(self) -> EngineCoreOutputs
- 执行单步推理
- 调度请求、执行模型、生成输出
def step_with_batch_queue(self) -> Optional[EngineCoreOutputs]
- 使用批处理队列执行推理
- 支持异步调度和执行
- 实现流水线并行处理
def add_lora(self, lora_request: LoRARequest) -> bool
def remove_lora(self, lora_id: int) -> bool
def list_loras(self) -> set[int]
def pin_lora(self, lora_id: int) -> bool
LoRA 相关功能:
- 管理 LoRA 适配器
- 支持添加、删除、列出和固定 LoRA
vLLM 引入了一个利用 ZeroMQ for IPC 的多进程 API 服务器,实现了 API 服务器和 AsyncLLM 之间的重叠。

EngineCoreProc
EngineCoreProc 类继承自 EngineCore,主要用于在后台进程中运行 EngineCore,它通过 ZMQ 实现了高效的进程间通信,使得模型推理能够在后台进程中异步执行,同时保持与主进程的高效通信。
异步 IO 处理:
使用独立线程处理输入输出
通过 ZMQ 实现进程间通信
使用队列实现线程间通信
性能优化:
使用 ZMQ 套接字 IO 与 GPU 操作重叠
序列化/反序列化与模型前向传播重叠
复用发送缓冲区
def __init__(self, input_path: str, output_path: str, ready_pipe: Connection,
vllm_config: VllmConfig, executor_class: type[Executor], log_stats: bool)
- 调用父类 EngineCore 的初始化
- 创建输入输出队列用于 IO 处理
- 启动输入输出处理线程
- 发送就绪信号给 EngineClient
@staticmethod
def run_engine_core(*args, **kwargs)
- 设置信号处理(处理 SIGTERM 和 SIGINT)
- 启动引擎核心
- 处理异常和优雅退出
- 确保资源正确清理
def run_busy_loop(self)
核心循环:
- 轮询输入队列等待工作
- 处理新的客户端请求
- 执行引擎核心步骤
- 将输出放入输出队列
def _handle_client_request(self, request_type: EngineCoreRequestType, request: Any)
客户端请求处理:(三种类型)
- ADD:添加新请求
- ABORT:中止请求
- UTILITY:执行工具方法
@staticmethod
def _convert_msgspec_args(method, args)
- 将输入参数转换为正确的类型
- 处理 msgspec 结构体的转换
def process_input_socket(self, input_path: str)
输入处理:
- 使用 ZMQ PULL 套接字接收请求
- 解码请求数据(使用 Msgpack)
- 将请求放入输入队列
def process_output_socket(self, output_path: str)
输出处理:
- 使用 ZMQ PUSH 套接字发送响应
- 编码输出数据(使用 Msgpack)
- 从输出队列获取并发送结果
EngineCoreClient

这个类作为 vLLM 系统的核心接口层,提供了统一的抽象接口,使得不同的实现可以无缝切换,同时支持同步和异步操作,为系统提供了极大的灵活性和可扩展性。
@staticmethod
def make_client(multiprocess_mode: bool, asyncio_mode: bool,
vllm_config: VllmConfig, executor_class: type[Executor],
log_stats: bool) -> "EngineCoreClient"
根据配置创建适当的客户端实例:
如果 asyncio_mode=True 且 multiprocess_mode=True:返回 AsyncMPClient(使用 ZMQ + 后台进程的 EngineCore,用于异步 LLM)
如果 multiprocess_mode=True 且 asyncio_mode=False:返回 SyncMPClient(使用 ZMQ + 后台进程的 EngineCore,用于同步 LLM)
如果 multiprocess_mode=False:返回 InprocClient进程内 EngineCore(用于 V0 风格的 LLMEngine)
整体流程可以参考:知乎
2. 简单且灵活的调度器
分块预填充调度
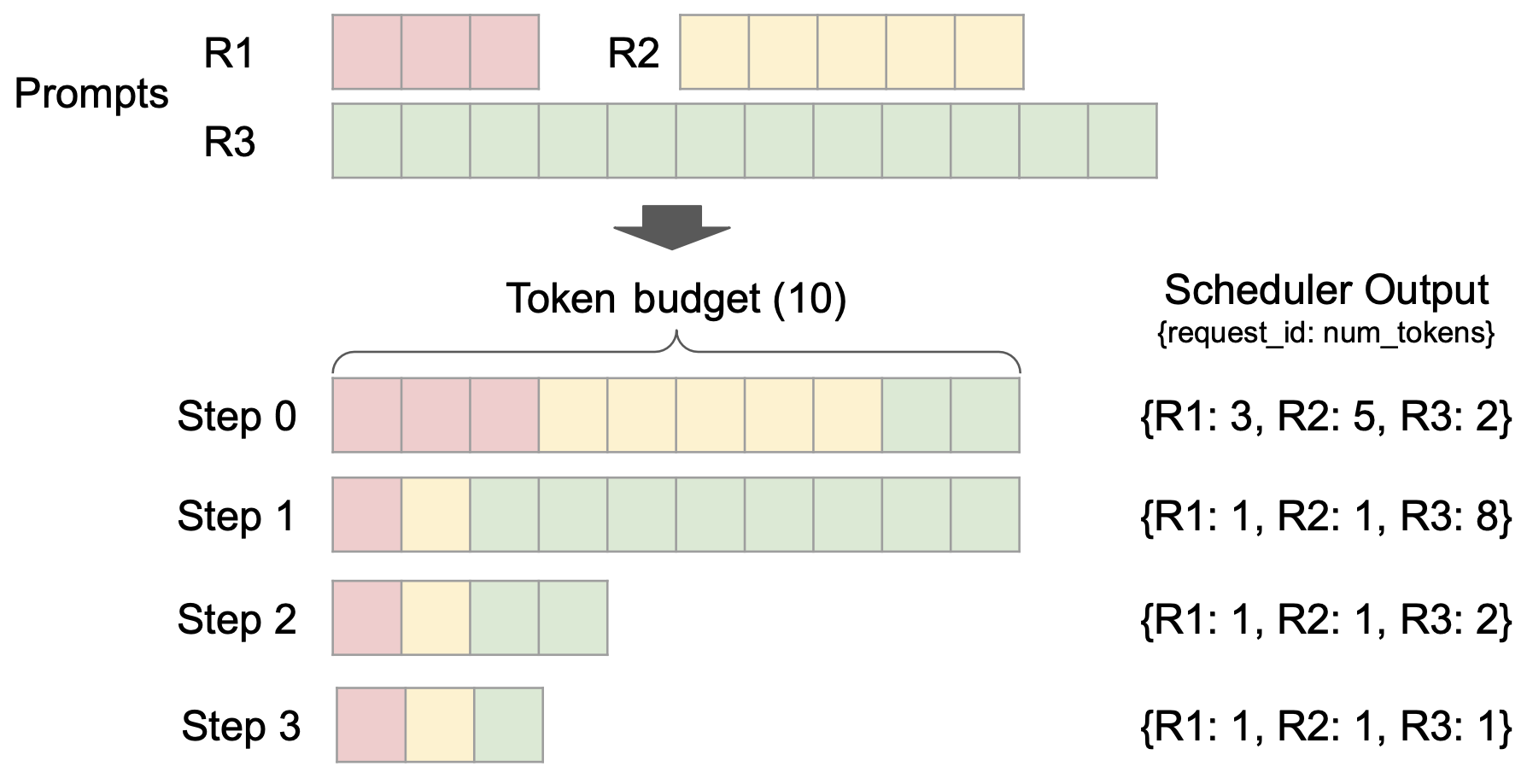
调度决策表示为一个简单的字典,例如,{request_id: num_tokens},它指定了在每个步骤中要为每个请求处理的 tokens 数量。分块预填充调度可以无缝实现:在固定的 tokens 预算下,调度器动态决定为每个请求分配多少 tokens(如上图所示)。
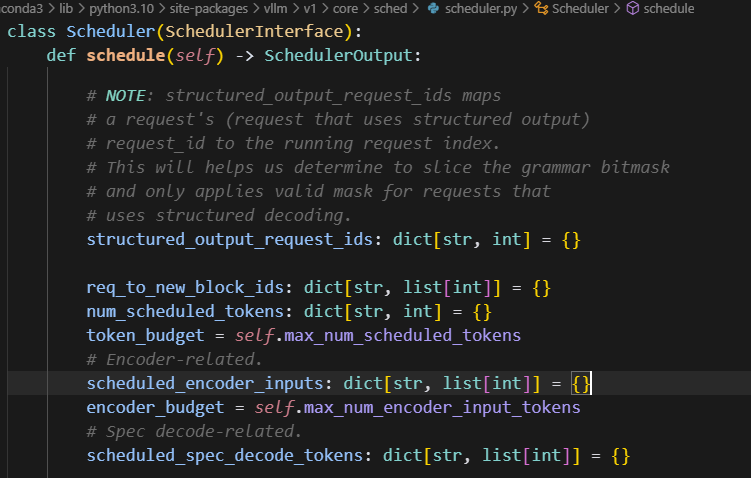
num_scheduled_tokens这个是在计算给每个req_id分配的token数量
req_index = 0
while req_index < len(self.running) and token_budget > 0:
确保还有可用的token预算时,遍历所有运行中的请求
num_new_tokens = (request.num_tokens_with_spec - request.num_computed_tokens)
num_new_tokens = min(num_new_tokens, token_budget)
计算还需要的token数量并根据预算限制调整token数量
encoder_inputs_to_schedule, num_new_tokens, new_encoder_budget = (
self._try_schedule_encoder_inputs(request,
request.num_computed_tokens,
num_new_tokens,
encoder_budget))
尝试调度编码器,如果满足以下条件,将安排编码器输入:
- 其输出 Tokens 与正在计算的 Tokens 范围重叠。
- 它尚未计算并存储在编码器缓存中。
- 有足够的编码器 token 预算来处理它。
- 编码器缓存有空间来存储它。
如果无法调度,跳过当前请求。后续步骤就不需要了
如果可以调度,则更新token数量和编码器预算。
while True:
new_blocks = self.kv_cache_manager.allocate_slots(request, num_new_tokens)
if new_blocks is None:
# 抢占逻辑
preempted_req = self.running.pop()
self.kv_cache_manager.free(preempted_req)
preempted_req.status = RequestStatus.PREEMPTED
# ... 抢占处理 ...
preempted_req.num_computed_tokens = 0
if self.log_stats:
preempted_req.record_event(
EngineCoreEventType.PREEMPTED, scheduled_timestamp)
self.waiting.appendleft(preempted_req)
preempted_reqs.append(preempted_req)
if preempted_req == request:
# No more request to preempt.
can_schedule = False
break
else:
can_schedule = True
break
尝试为请求分配KV缓存槽。
如果分配失败,执行抢占策略,直到资源可以满足调度:
- 从运行请求中移除优先级最低的请求
- 释放该请求的KV缓存
- 将该请求移回等待队列
如果当前请求优先级最低无法抢占,则不能调度,跳过当前请求。
# Schedule the request.
scheduled_running_reqs.append(request)
self.scheduled_req_ids.add(request.request_id)
将请求添加到已调度列表并记录请求ID
if request.use_structured_output:
structured_output_request_ids[request.request_id] = req_index
处理需要结构化输出的请求
num_scheduled_tokens[request.request_id] = num_new_tokens
token_budget -= num_new_tokens
req_index += 1
对于正常的running的req来说,num_new_tokens通常是1,因为一次step新增一个token;对于上一次从waiting队列调度的,并且prompt被截断的req来说,这个数字才会大于1
if request.spec_token_ids:
num_scheduled_spec_tokens = (num_new_tokens +
request.num_computed_tokens -
request.num_tokens)
if num_scheduled_spec_tokens > 0:
del request.spec_token_ids[num_scheduled_spec_tokens:]
scheduled_spec_decode_tokens[request.request_id] = request.spec_token_ids
计算推理解码的token数量并调整解码token列表
if encoder_inputs_to_schedule:
scheduled_encoder_inputs[request.request_id] = encoder_inputs_to_schedule
for i in encoder_inputs_to_schedule:
self.encoder_cache_manager.allocate(request, i)
encoder_budget = new_encoder_budget
分配编码器缓存并更新编码器预算:
3. 零开销前缀缓存
与 V0 一样,vLLM V1 使用基于哈希的前缀缓存和基于 LRU 的缓存驱逐。
@dataclass
class PrefixCacheStats:
"""Stores prefix cache hit statistics."""
# Whether reset_prefix_cache was invoked.
reset: bool = False
# The number of requests in this update.
requests: int = 0
# The number of queries in these requests. Note that "queries" here
# means the number of blocks that were queried from the cache.
queries: int = 0
# The number of hits in these requests.
hits: int = 0
统计指标
请求级别统计requests: 记录处理了多少个请求,这个数字反映了系统的总体负载
查询级别统计queries: 记录尝试从缓存中查询的块数量,每个请求可能会查询多个块
命中级别统计hits: 记录成功从缓存中找到的块数量,可以用来计算命中率
hit_rate = hits / queries if queries > 0 else 0

def get_computed_blocks(self, request: Request) -> tuple[list[KVCacheBlock], int]:
- 哈希计算:
- 用于识别可重用的缓存块: 如果调度器之前尝试过调度请求,请求的区块哈希值可能已经计算出来。
- 计算请求的块哈希
- 缓存命中检查,如果命中则添加到computed_blocks中
- 块结构:
| < computed > | < new computed > | < new > | < pre-allocated > |
computed: 已计算的块
new computed: 新计算的块
new: 新分配的块
pre-allocated: 预分配的块
- 统计更新:
-
更新缓存命中率统计:
self.prefix_cache_stats.queries += len(block_hashes)
self.prefix_cache_stats.hits += len(computed_blocks) -
已计算的token数量:
num_computed_tokens = len(computed_blocks) *
self.block_size
def allocate_slots(self, request: Request, num_tokens: int,
new_computed_blocks: Optional[list[KVCacheBlock]] = None):
槽位分配主要步骤:
- 计算需求,使用“天花板除法”(ceiling division)
num_computed_tokens = (request.num_computed_tokens +
len(new_computed_blocks) * self.block_size)
num_required_blocks = cdiv(num_computed_tokens + num_tokens, self.block_size)
- 块分配
if num_new_blocks > 0:
new_blocks = self.block_pool.get_new_blocks(num_new_blocks)
req_blocks.extend(new_blocks)
- 缓存管理
self.block_pool.cache_full_blocks(
request=request,
blocks=req_blocks,
block_hashes=self.req_to_block_hashes[request.request_id],
num_cached_blocks=num_cached_blocks,
num_full_blocks=num_full_blocks_after_append,
block_size=self.block_size,
)
block_pool中相关优化:
恒定时间的缓存驱逐:

class FreeKVCacheBlockQueue:
"""
使用双向链表组织 KVCacheBlock 对象。
不使用 Python 内置的 deque,而是直接操作块的指针,以实现 O(1) 时间复杂度的操作。
"""
def __init__(self, blocks: list[KVCacheBlock]):
self.num_free_blocks = len(blocks)
self.free_list_head = blocks[0]
self.free_list_tail = blocks[-1]
# 初始化双向链表
for i in range(self.num_free_blocks):
if i > 0:
blocks[i].prev_free_block = blocks[i - 1]
if i < self.num_free_blocks - 1:
blocks[i].next_free_block = blocks[i + 1]
队列在开始时按区块 ID 排序。当一个区块被分配然后被释放时,它将被附加回驱逐顺序:
- 最近使用最少的块位于前面 (LRU)。
- 如果两个区块的上次访问时间相同(由相同的序列分配),则具有更多哈希tokens的区块(区块链的尾部)位于最前面。
最小化 Python 对象创建
@dataclass
class KVCacheBlock:
block_id: int
ref_cnt: int = 0
_block_hash: Optional[BlockHashType] = None
prev_free_block: Optional["KVCacheBlock"] = None
next_free_block: Optional["KVCacheBlock"] = None
通过在 KVCacheBlock 类中直接存储前后指针,避免创建额外的 Python 对象。
所有关键操作(添加、删除、驱逐)都是 O(1) 时间复杂度
def remove(self, block: KVCacheBlock) -> None:
"""O(1) 时间复杂度的块移除"""
if block.prev_free_block is not None:
block.prev_free_block.next_free_block = block.next_free_block
if block.next_free_block is not None:
block.next_free_block.prev_free_block = block.prev_free_block
# ... 更新头尾指针 ...
block.prev_free_block = block.next_free_block = None
self.num_free_blocks -= 1
def append(self, block: KVCacheBlock) -> None:
"""O(1) 时间复杂度的块添加"""
if self.free_list_tail is not None:
self.free_list_tail.next_free_block = block
block.prev_free_block = self.free_list_tail
self.free_list_tail = block
else:
self.free_list_head = self.free_list_tail = block
def popleft(self) -> KVCacheBlock:
"""Pop the first free block and reduce num_free_blocks by 1.
Returns:
The first free block.
"""
if not self.free_list_head:
raise ValueError("No free blocks available")
block = self.free_list_head
self.remove(block)
return block
4. 用于张量并行推理的清晰架构
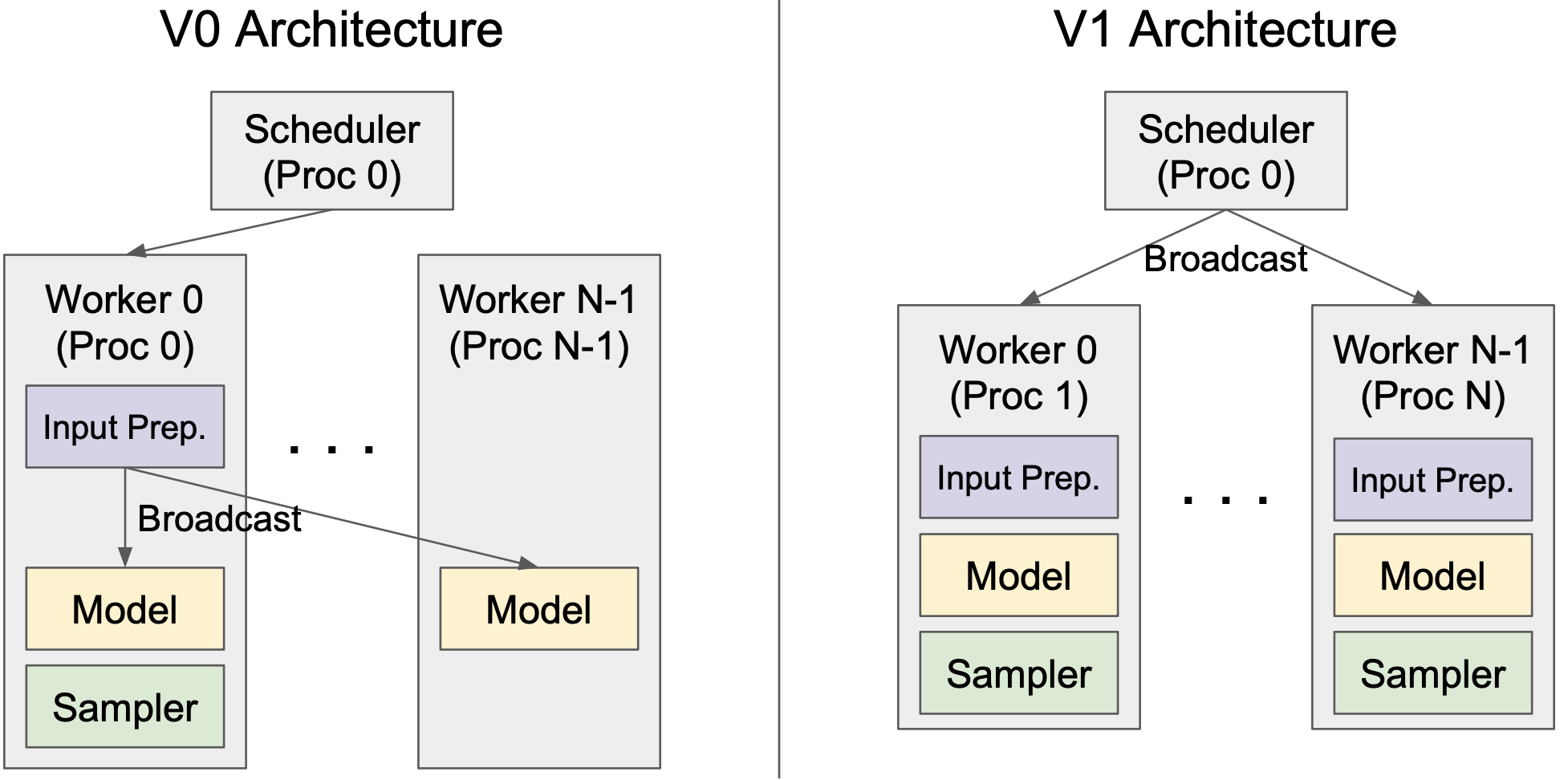
vLLM V1 引入了一个用于张量并行推理的清晰高效的架构,有效地解决了 V0 的局限性。在 V0 中,调度器和 Worker 0 位于同一进程中,以减少将输入数据广播到 workers 时的进程间通信开销。然而,这种设计引入了不对称架构,增加了复杂性。V1 通过在 worker 端缓存请求状态并在每个步骤仅传输增量更新(差异)来克服这一点。这种优化最大限度地减少了进程间通信,允许调度器和 Worker 0 在单独的进程中运行,从而产生清晰的对称架构。此外,V1 抽象出了大部分分布式逻辑,使 workers 在单 GPU 和多 GPU 设置中都以相同的方式运行。

















 2597
2597

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









