






之前本地部署LLM一直用的都是伯克利开源的VLLM,具体优点就是推理速度快,并发支持极高,不在这里具体阐述了,能看见这篇文章的肯定都是一直用这个服务的。
之前一直在ubuntu22.0系统,4090卡上部署,上上周花了3个W多买到了一张5090D,但是发现这玩意儿没法用之前的镜像开机都开不开,然后安装纯净ubuntu24之后重新部署发现CUDA版本竟然高达12.8,而且多次降级到12.4都不好使。
(这特喵的不会卡买回来用不上吧!于是开始逛issues,各种查发现也有一些反馈但是没有看到具体有用的信息。)
清明假期前提了个issue,然后邮箱里收到了回复关于50系cuda12.8的步骤,于是兴致满满的点开链接开始搭环境。话不多说,言归正传!
1.将你的50系的卡驱动正常安装,cuda版本正常安装到12.8。
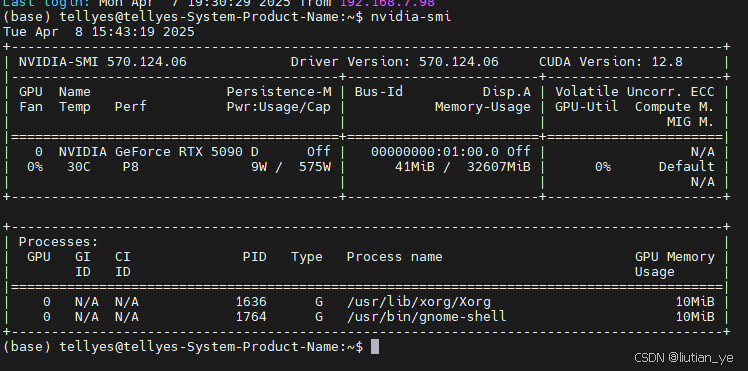
运行代码nvidia-smi后能看见如下界面表示兄弟你可以的!
2.安装anaconda3
这个就不多说了吧,从官网下载Anaconda3-2024.10-1-Linux-x86_64.sh然后直接执行sudo bash Anaconda3-2024.10-1-Linux-x86_64.sh就OK了,细节不多说了,这个教材极多,翻车几率极低…
3.重点开始了啊,创建虚拟环境!
在你的数据存储路径下,执行命令sudo touch environment_linux.yml先创建一个环境的配置文件。
然后执行sudo nano environment_linux.yml编辑这个文件(有工具的话也可以直接点开),输入以下内容:
channels:
- conda-forge
- pytorch
- nvidia
- defaults
dependencies:
- python=3.12
- anaconda
- pip
然后正常保存,紧接着就可以执行创建环境的命令了conda env create -f environment_linux.yml
4.切换到环境并安装pytorch!
执行命令conda activate vllm成功切换到vllm的环境内,此时命令行最前端有(vllm)表示切换成功。这里需要注意,在这一步耽误我好长时间,cuda12.8版本的pytorch发行版里最高只到12.6,我当时也是没注意装了个12.6就各种出问题。执行命令pip install --pre torch==2.7.0.dev20250312+cu128 --index-url https://download.pytorch.org/whl/nightly/cu128安装torch。
5.测试环境有没有问题
执行python后进入到python编辑窗口,依次输入以下命令并查看输出结果是否一致:
In [1]: import torch
In [2]: torch.__version__
Out[2]: '2.7.0.dev20250312+cu128'
In [3]: print(torch.cuda.is_available())
True
In [4]: device = "cuda"
In [5]: x = torch.ones(5, 5).to(device)
In [6]: y = torch.randn(5, 5).to(device)
In [7]: z = x + y
In [8]: print(z)
tensor([[ 2.7746, 0.7957, 2.3443, 0.8475, 0.4464],
[ 0.3883, -0.2033, 3.1749, 1.0566, 1.6964],
[ 0.6829, 0.0952, 1.3061, 1.4194, 1.6353],
[ 1.4389, 0.7820, -0.0463, 2.0666, 1.4440],
[ 2.5913, 0.6384, 2.3288, 1.3102, 2.2450]], device='cuda:0')
如果一致可以看到下一步了!
6.克隆项目到本地
执行命令
git clone https://github.com/vllm-project/vllm.git
cd vllm
git checkout v0.8.3
python use_existing_torch.py
pip install -r requirements/build.txt
pip install setuptools_scm
7.修改参与构建项目的线程数
这里翻了两回车,构建就死机构建就死机,开始没留意后来发现死机前32G的内存直接拉满最后一秒开始失联…我是14代i9-14900KF的处理器,我放了8个构建还是挺快的。
export MAX_JOBS=8
python setup.py install
然后就可以等着console一直build了…
一会儿构建完了可以试试whereis vllm看看有没有找到
8.运行本地路径下的模型
python -m vllm.entrypoints.openai.api_server --model /home/tellyes/ai_tools/models/Qwen2.5-32B-Instruct-AWQ --served-model-name qwen --max-model-len=4096 --gpu-memory-utilization=0.8 --max-num-seqs=4 --port 8003
9.常规情况下,此时你已经能成功在50系列的新卡上运行模型了
但是…总有不按套路出牌的环节,我这一套操作下来直接报错了,而且还看不懂…ModuleNotFoundError: No module named 'vllm._C'
然后更换另一种启动方式后又换成另一个错:ValueError: Model architectures ['Qwen2ForCausalLM'] failed to be inspected. Please check the logs for more details.
在issues里查了好半天他们给的什么反馈都是过了还是没用,然后最终升级transformers版本到最最新的版本,执行pip install transformers==4.51.0,再次运行模型,推理成功!
本次操作流程和你在github上看见的步骤有出入,但是我按github上的那套是成功不了,这一套是能成功的,其中两个地方,vllm版本选了最新的0.8.3而不是0.8.2,第二个是直接通过源码构建而不是直接install vllm,需要注意这两个地方。
下一个还得赶紧去部GPTSoVits到5090上,希望不要再踩什么坑了。

















 2764
2764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









