







目录
文本生成对于许多NLP任务至关重要,例如开放式文本生成、摘要、翻译等。它还在各种混合模态应用程序中发挥作用,这些应用程序将文本作为输出,如语音到文本和视觉到文本。一些可以生成文本的模型包括GPT2、XLNet、OpenAI GPT、CTRL、TransformerXL、XLM、Bart、T5、GIT、Whisper。
请注意,generate方法的输入依赖于模型的模态。它们由模型的preprocessor类返回,例如AutoTokenizer或AutoProcessor。如果模型的preprocessor创建了不止一种输入,则将所有输入传递给generate()。
选择输出token以生成文本的过程称为解码,您可以定制generate()方法将使用的解码策略。修改解码策略不会改变任何可训练参数的值。但是,它会对生成的输出的质量产生明显的影响。它可以帮助减少文本中的重复,使其更加连贯。
transformers.generation.GenerationMixin
class GenerationMixin:
"""
A class containing all functions for auto-regressive text generation, to be used as a mixin in [`PreTrainedModel`].
The class exposes [`~generation.GenerationMixin.generate`], which can be used for:
- *greedy decoding* by calling [`~generation.GenerationMixin._greedy_search`] if `num_beams=1` and
`do_sample=False`
- *contrastive search* by calling [`~generation.GenerationMixin._contrastive_search`] if `penalty_alpha>0` and
`top_k>1`
- *multinomial sampling* by calling [`~generation.GenerationMixin._sample`] if `num_beams=1` and
`do_sample=True`
- *beam-search decoding* by calling [`~generation.GenerationMixin._beam_search`] if `num_beams>1` and
`do_sample=False`
- *beam-search multinomial sampling* by calling [`~generation.GenerationMixin._beam_sample`] if `num_beams>1`
and `do_sample=True`
- *diverse beam-search decoding* by calling [`~generation.GenerationMixin._group_beam_search`], if `num_beams>1`
and `num_beam_groups>1`
- *constrained beam-search decoding* by calling [`~generation.GenerationMixin._constrained_beam_search`], if
`constraints!=None` or `force_words_ids!=None`
- *assisted decoding* by calling [`~generation.GenerationMixin._assisted_decoding`], if
`assistant_model` or `prompt_lookup_num_tokens` is passed to `.generate()`
You do not need to call any of the above methods directly. Pass custom parameter values to 'generate' instead. To
learn more about decoding strategies refer to the [text generation strategies guide](../generation_strategies).
"""
参数
有一些模型参数会影响模型生成输出的可预测性。这些参数包括temperature、top-p、top-k、frequency_penalty和presence_penalty。
Temperature
从生成模型中抽样包含随机性,因此每次点击“generate”时,相同的提示可能会产生不同的输出。温度是一个用来调整随机性程度的数字。
更低的温度值意味着更少的随机性;温度值为0将始终产生相同的输出。较低的温度值(小于1)更适合执行具有“正确”答案的任务,如问答或摘要。如果模型开始自我重复,这是温度值可能太低的迹象。
高温度值意味着更多的随机性。这可以帮助模型提供更多创造性的输出,但如果您使用检索增强生成(RAG),也可能意味着它没有正确使用您提供的上下文。如果模型开始偏离主题,给出无意义的输出,这是温度值过高的迹象。
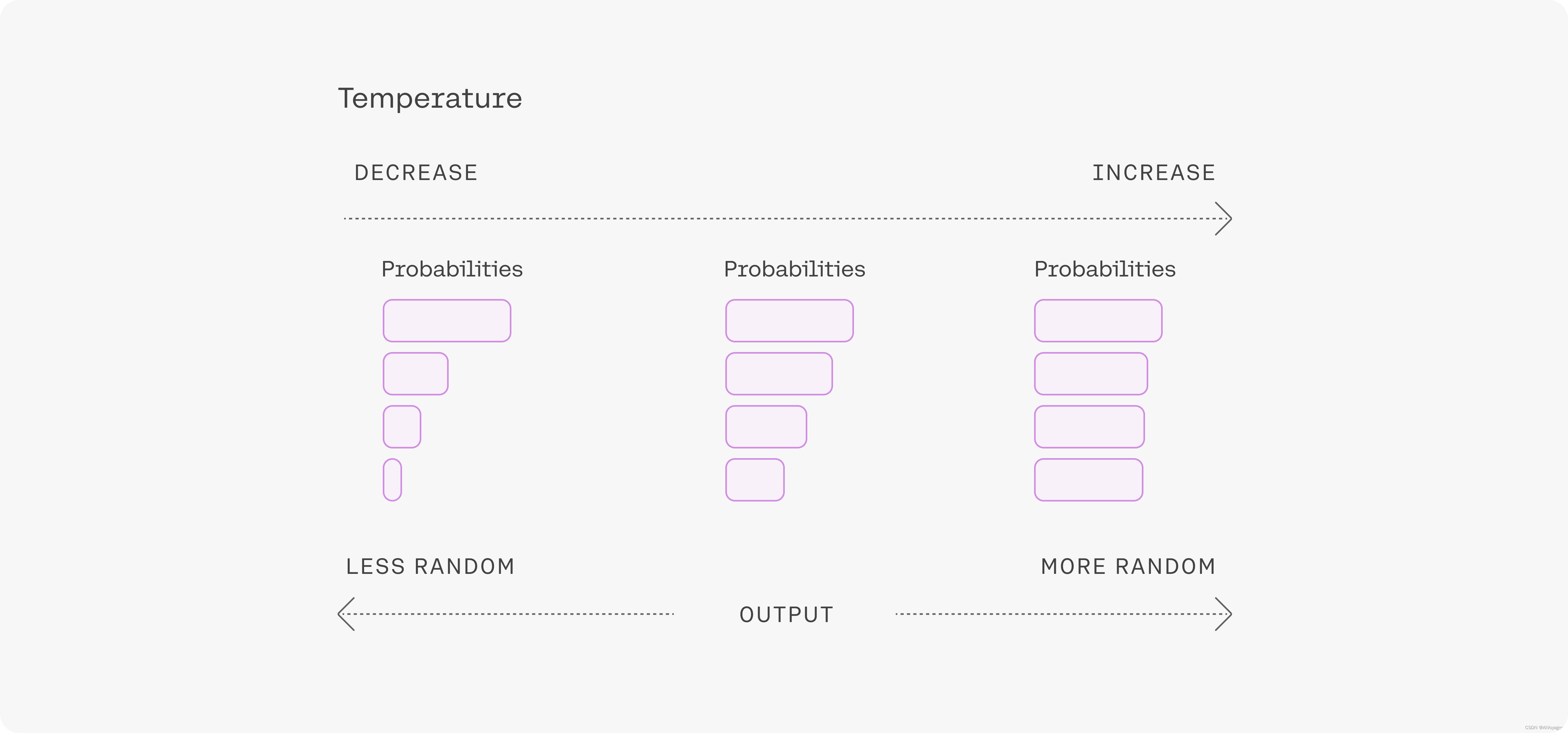
温度值可以针对不同的问题进行调整,但大多数人会发现温度值为1是一个很好的起点。
随着序列变长,模型对其预测自然会变得更有信心,因此您可以对较长的提示提高温度值而不会跑题。相比之下,在简短的提示中使用高温度值可能会导致输出非常不稳定。
Top-p and Top-k
用于选择输出标记的方法是使用语言模型成功生成文本的重要组成部分。有几种方法(也称为解码策略)用于选择输出token,其中最主要的两种是top-k采样和top-p采样。
让我们看一下这个例子,其中模型的输入prompt 是The name of that country is the
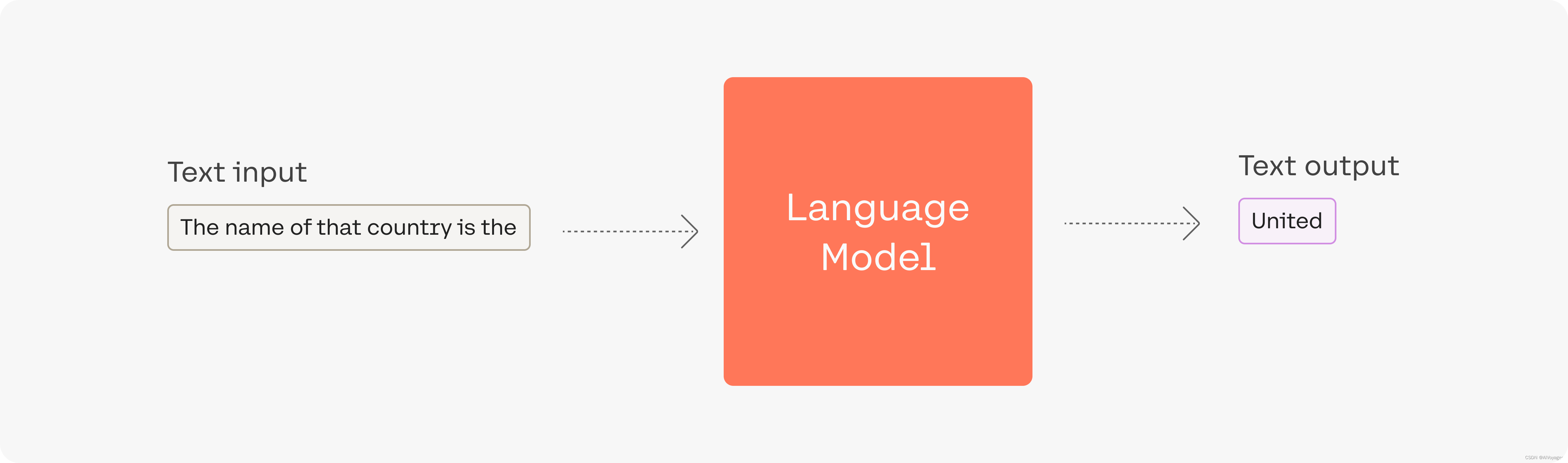
在本例中,输出的token为United 。这是在语言模型处理了输入并为其词汇表中的每个token计算了可能性得分之后输出的。这个分数表明它是句子中下一个token的可能性(基于模型所训练的所有文本)。
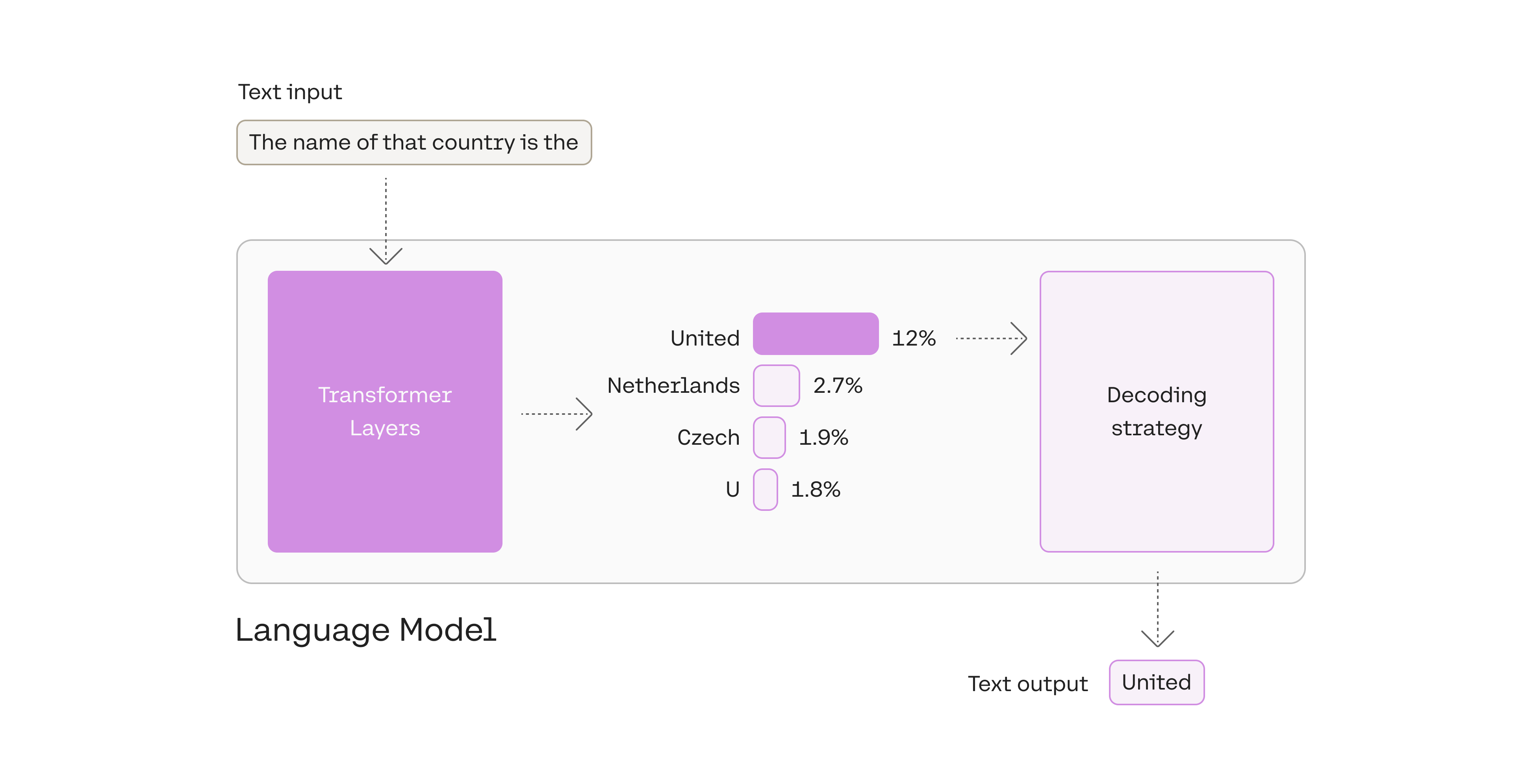
该模型计算其词汇表中每个token的可能性。使用解码策略选择一个作为输出。
1. 选择最上面的token:贪婪解码

总是选择得分最高的token被称为“贪婪解码”。它很有用,但也有一些缺点。
贪婪解码是一种合理的策略,但存在一些缺陷;例如,输出可能会陷入重复的循环中。想想你的智能手机输入法的自动建议。当你不断地选择最高的建议词时,它可能会演变成重复的句子。
2. 从最上面的tokens中选择:top-k
另一个常用的策略是3个top tokens的候选列表中取样。这种方法允许其他高分toekn有机会被选中。这种抽样引入的随机性有助于在许多场景中提高生成的质量。
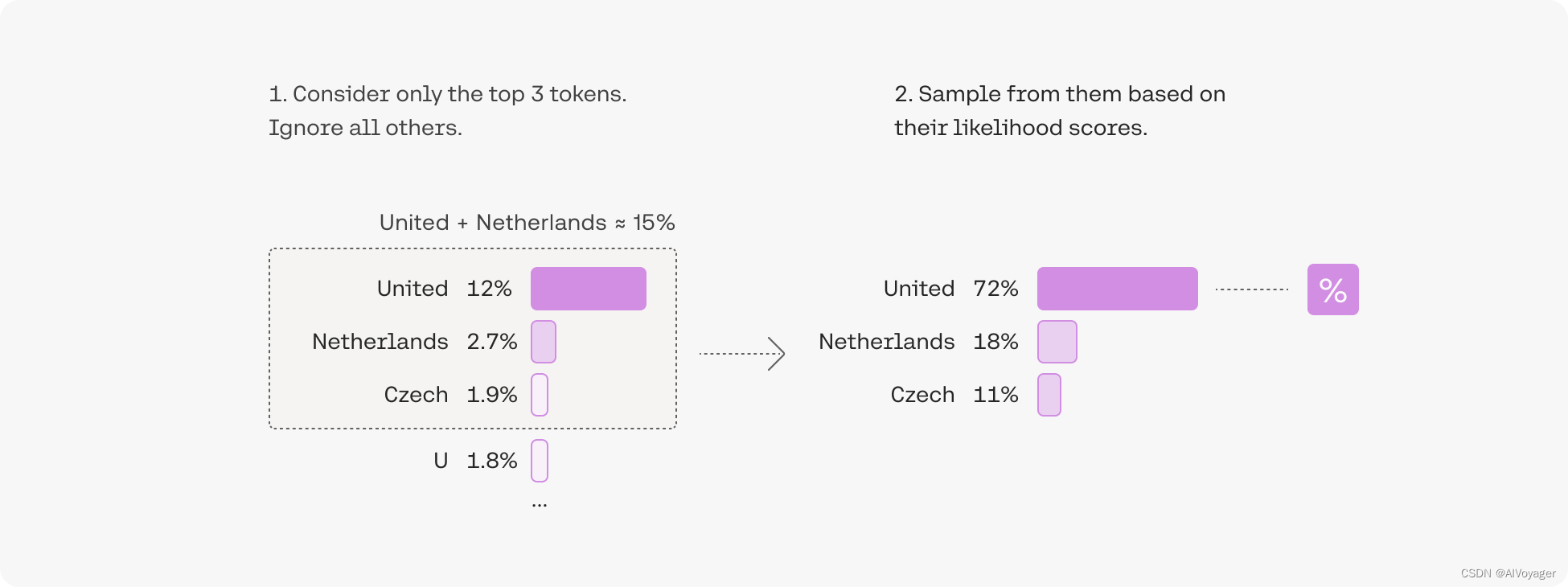
添加一些随机性有助于使输出文本更自然。在top-3解码中,我们首先列出三个token,然后通过考虑它们的似然分数(likelihood)对其中一个进行采样。
更广泛地说,选择前三个标记意味着将top-k参数设置为3。更改top-k参数将设置模型在输出每个token时从中采样的候选列表的大小。将top-k设置为1时得到的是贪婪解码。

注意,当k被设置为0时,模型禁用k采样并使用p。
3. 从概率加起来为15%的top token中选择:top-p
由于选择最佳top-k值的难度很大,因此另一种流行的解码策略诞生了,该策略可以动态设置token短列表的大小。这种方法称为“核心抽样(Nucleus Sampling)”,通过选择可能性总和不超过某一特定值的top tokens来创建候选名单。top-p值为0.15的简单示例如下:
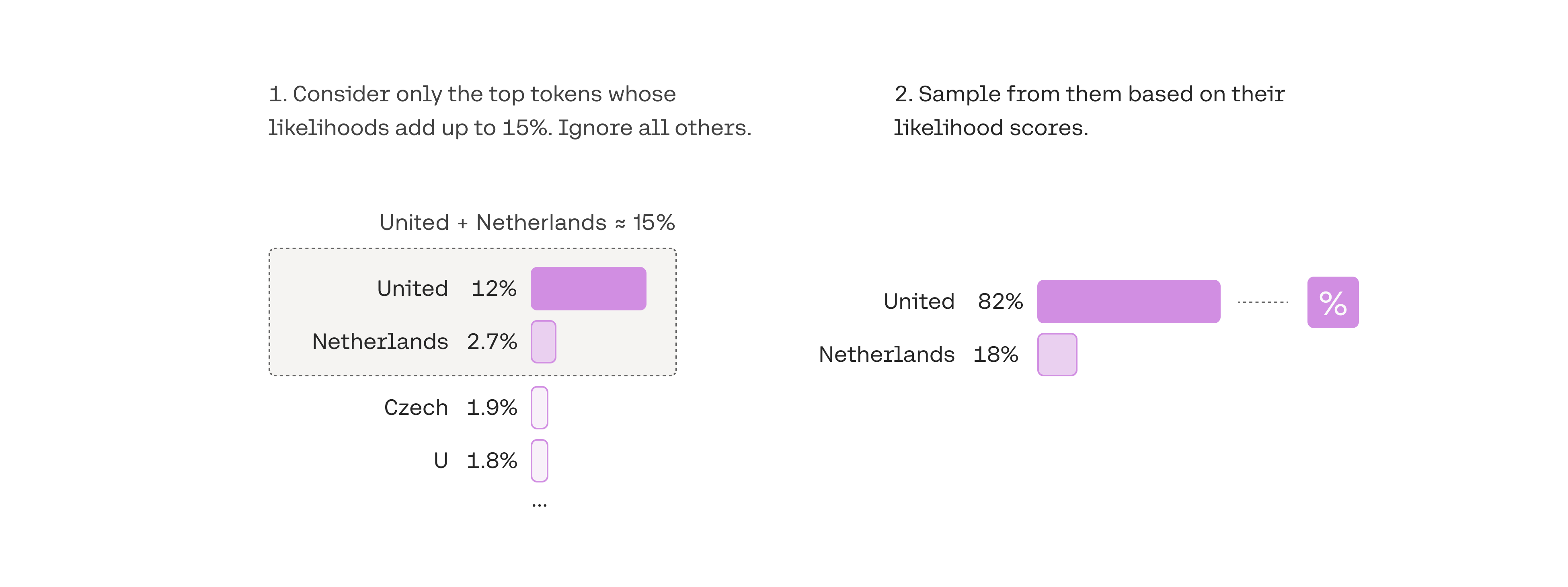
在top-p中,候选名单的大小是根据达到某个阈值的似然得分的总和动态选择的。
Top-p通常设置为一个高值(如0.75),目的是限制可能采样的低概率token的长尾。我们可以同时使用top-k和top-p。
如果k和p都启用,则p在k之后起作用。
Frequency and Presence Penalties
最后一组参数是frequency_penalty和presence_penalty,它们都对token的对数(log)概率(即“logits”)起作用,以影响给定token在输出中出现的频率。
频率惩罚–惩罚之前文本中已经出现的token(包括提示),并根据该token出现的次数进行缩放。因此,已经出现10次的令牌比只出现一次的令牌得到更高的惩罚(这降低了它出现的概率)。
出现惩罚–不管出现的频率如何,只要这个token之前出现过一次,就会被惩罚。
transformers库中的解码策略
默认文本生成配置模型的解码策略在其生成配置中定义。当在pipeline()中使用预训练模型进行推理时,模型会调用PreTrainedModel.generate()方法,该方法在后台应用默认的生成配置。当模型中没有保存自定义配置时,也使用默认配置。
- 查看生成配置:
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("distilbert/distilgpt2")
print(model.generation_config)
# GenerationConfig {
# "bos_token_id": 50256,
# "eos_token_id": 50256
# }
# <BLANKLINE>
Generation_config只显示与默认生成配置不同的值,而没有列出任何默认值。默认的生成配置将输出和输入token的大小限制为最多20个token,以避免
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3075
3075











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









