







 本文详细介绍了Transformer模型在文本生成中的几种核心解码策略,如贪心搜索、beamsearch、top-k和top-p采样,以及它们在实际应用中的代码实现,旨在帮助读者理解和实践这些技术。
本文详细介绍了Transformer模型在文本生成中的几种核心解码策略,如贪心搜索、beamsearch、top-k和top-p采样,以及它们在实际应用中的代码实现,旨在帮助读者理解和实践这些技术。
Transformer基础可参考我撰写的博文:Transformer原理纯享版
GPT-2基础可参考我撰写的博文:Re62:读论文 GPT-2 Language Models are Unsupervised Multitask Learners
在自然语言处理领域,文本生成是一个重要且具有挑战性的任务,它涉及到如何让机器自动生成连贯、有意义的文本。随着Transformer模型的出现,文本生成的能力有了质的飞跃。本文将探讨几种核心的解码策略,以及它们在Transformers库中的代码实现。我们不仅会介绍这些方法的理论基础,还会通过实际代码示例展示如何应用这些策略来生成文本,主要使用transformers中的generate()函数。
重点介绍贪心、beam search、sampling(top-k / top-p)及其代码实现。
解码的过程就是说,我们已经训练好了一个模型(有些模型训练过程不是tearch forcing而是直接带解码过程的,比如强化学习,这种情况本文会介绍到,但不是重点),在测试的时候是auto-regressive生成序列的,所以每个timestep都会得到token概率,从中选择一个token,然后下一个timestep得到新的token概率。解码就是每次从token概率中敲定最终选择哪个token的过程。这段如果有人没看懂可以具体问,我看这个要从RNN开始解释……以后再研究怎么把这事讲清楚吧,总之现在默认大家都理解解码是要干什么了,下面就介绍如何解码。
(NAR是另一回事,本文暂不考虑)
贪心搜索和beam search常见文本重复问题(可参考 (2018 AAAI) Diverse Beam Search: Decoding Diverse Solutions from Neural Sequence Models 和 (2017 EMNLP) Generating High-Quality and Informative Conversation Responses with Sequence-to-Sequence Models)
开放式文本生成会偏好采样方法。
采样:
w
t
∼
P
(
w
∣
w
1
:
t
−
1
)
w _t ∼P(w∣w_{1:t−1} )
wt∼P(w∣w1:t−1)

top-k/p/temperature的目标都是舍弃长尾词并重缩放头部词概率分布。
在机器翻译或摘要等任务中,因为所需生成的长度或多或少都是可预测的,所以beam search效果比较好。((2018 WMT) Correcting Length Bias in Neural Machine Translation 和 (2018 EMNLP) Breaking the Beam Search Curse: A Study of (Re-)Scoring Methods and Stopping Criteria for Neural Machine Translation)
文章目录
1. 贪心搜索
贪心搜索在每个时间步 t t t 都简单地选择概率最高的词作为当前输出词: w t = arg max w P ( w ∣ w 1 : t − 1 ) w_t = \argmax_{w}P(w | w_{1:t-1}) wt=argmaxwP(w∣w1:t−1)

2. beam search
波束搜索通过在每个时间步保留最可能的 num_beams 个词,并从中最终选择出概率最高的序列来降低丢失潜在的高概率序列的风险。
以 num_beams=2 为例:

波束搜索一般都会找到比贪心搜索概率更高的输出序列,但仍不保证找到全局最优解。
3. top-k sampling
(2018) Hierarchical Neural Story Generation
提升随机性、减少重复。
概率最大的 K 个词会被选出,然后这 K 个词的概率会被重新归一化,最后就在这重新被归一化概率后的 K 个词中采样。
(GPT2 采用了这种采样方案)

设
K
=
6
K = 6
K=6,即我们将在两个采样步的采样池大小限制为 6 个单词。我们定义 6 个最有可能的词的集合为
V
top-K
V_{\text{top-K}}
Vtop-K。在第一步中,
V
top-K
V_{\text{top-K}}
Vtop-K 仅占总概率的大约三分之二,但在第二步,它几乎占了全部的概率。同时,我们可以看到在第二步该方法成功地消除了那些奇怪的候选词
(
“not”
,
“the”
,
“small”
,
“told”
)
(\text{“not”}, \text{“the”}, \text{“small”}, \text{“told”})
(“not”,“the”,“small”,“told”)。
Top-K 采样不会动态调整从需要概率分布
P
(
w
∣
w
1
:
t
−
1
)
P(w|w_{1:t-1})
P(w∣w1:t−1) 中选出的单词数。这可能会有问题,因为某些分布可能非常尖锐 (上图中右侧的分布),而另一些可能更平坦 (上图中左侧的分布),所以对不同的分布使用同一个绝对数 K 可能并不普适。
在
t
=
1
t=1
t=1 时,Top-K 将
(
“people”
,
“big”
,
“house”
,
“cat”
)
(\text{“people”}, \text{“big”}, \text{“house”}, \text{“cat”})
(“people”,“big”,“house”,“cat”) 排出了采样池,而这些词似乎是合理的候选词。另一方面,在
t
=
2
t=2
t=2 时,该方法却又把不太合适的
(
“down”
,
“a”
)
(\text{“down”}, \text{“a”})
(“down”,“a”) 纳入了采样池。因此,将采样池限制为固定大小 K 可能会在分布比较尖锐的时候产生胡言乱语,而在分布比较平坦的时候限制模型的创造力。解决方案就是top-p sampling:
4. top-p sampling
也叫Nucleus sampling
(2020 ICLR) The Curious Case of Neural Text Degeneration

人类选择的token会具有更高的方差
top-k 采样的一个缺点是预定义的数字没有考虑概率分布的倾斜程度。top-p 抽样选择累积概率超过阈值(例如 0.95)的最小顶级候选集,然后在所选候选者之间重新调整分布。
这样,词集的大小 (又名 集合中的词数) 可以根据下一个词的概率分布动态增加和减少。

假设
p
=
0.92
p=0.92
p=0.92,Top-p 采样对单词概率进行降序排列并累加,然后选择概率和首次超过
p
=
92
p=92%
p=92 的单词集作为采样池,定义为
V
top-p
V_{\text{top-p}}
Vtop-p。在
t
=
1
t=1
t=1 时
V
top-p
V_{\text{top-p}}
Vtop-p 有 9 个词,而在
t
=
2
t=2
t=2 时它只需要选择前 3 个词就超过了 92%。
在单词比较不可预测时,它保留了更多的候选词,如
P
(
w
∣
“The”
)
P(w | \text{“The”})
P(w∣“The”),而当单词似乎更容易预测时,只保留了几个候选词,如
P
(
w
∣
“The”
,
“car”
)
P(w | \text{“The”}, \text{“car”})
P(w∣“The”,“car”)。
Top-p 也可以与 Top-K 结合使用,这样可以避免排名非常低的词,同时允许进行一些动态选择。
5. temperature sampling
降低temperature极化概率分布,:
p
i
∝
exp
(
o
i
/
T
)
∑
j
exp
(
o
j
/
T
)
p_i \propto \frac{\exp(o_i / T)}{\sum_j \exp(o_j/T)}
pi∝∑jexp(oj/T)exp(oi/T)
(
o
o
o是极化前的概率)

当“温度T”设置为
0
0
0 时,温度缩放采样就退化成贪心解码了
T越高,越平滑(更可能随机到更多样的token):
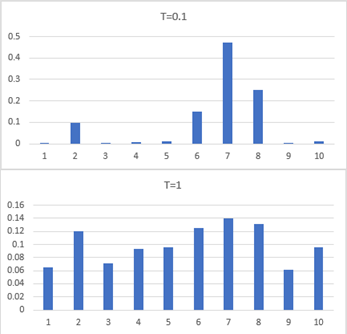
6. Penalized sampling
(2019) CTRL: A Conditional Transformer Language Model for Controllable Generation
避免生成重复子字符串的常见失败情况
p
i
=
exp
(
o
i
/
(
T
⋅
1
(
i
∈
g
)
)
)
∑
j
exp
(
o
j
/
(
T
⋅
1
(
j
∈
g
)
)
)
1
(
c
)
=
θ
if the condition
c
is True else
1
p_i = \frac{\exp(o_i / (T \cdot \mathbb{1}(i \in g)))}{\sum_j \exp(o_j / (T \cdot \mathbb{1}(j \in g)))} \quad \mathbb{1}(c) = \theta \text{ if the condition }c\text{ is True else }1
pi=∑jexp(oj/(T⋅1(j∈g)))exp(oi/(T⋅1(i∈g)))1(c)=θ if the condition c is True else 1
θ
=
1.2
\theta=1.2
θ=1.2
7. Guided Decoding
纳入对主题或情绪的偏好
每个解码步骤中token选择的排名分数可以设置为 LM 对数似然和一组所需特征鉴别器的组合,量化人类偏好。
启发式:(2017 ACL) Hafez: an Interactive Poetry Generation System
在解码步骤调整beam search中的采样权重来生成所需风格的诗歌
score
(
x
t
+
1
,
b
t
)
=
score
(
b
t
)
+
log
p
(
x
t
+
1
)
+
∑
i
α
i
f
i
(
x
t
+
1
)
\text{score}(x_{t+1}, b_t) = \text{score}(b_t) + \log p(x_{t+1}) + \color{green}{\sum_i \alpha_i f_i(x_{t+1})}
score(xt+1,bt)=score(bt)+logp(xt+1)+i∑αifi(xt+1)
log
p
(
x
t
+
1
)
\log p(x_{t+1})
logp(xt+1)是 LM 预测的对数似然值;
score
(
b
t
)
\text{score}(b_t)
score(bt)是当前beam
b
t
b_t
bt已生成词语的累积得分。绿色部分可以结合多种不同的特征来引导输出的风格。一组特征函数
f
i
(
.
)
f_i(.)
fi(.)定义了偏好,相关权重
a
l
p
h
a
i
alpha_i
alphai就像 “控制旋钮”,可以在解码时轻松定制。特征可以测量各种属性,并可以轻松组合,例如:
x
t
+
1
x_{t+1}
xt+1是否存在于一袋想要的或禁止的主题词中
x
t
+
1
x_{t+1}
xt+1是否表示某种情绪
x
t
+
1
x_{t+1}
xt+1是否是重复的标记(因此也需要将历史记录输入
f
i
f_i
fi)
x
t
+
1
x_{t+1}
xt+1长度偏好
启发式:(2018) Generating More Interesting Responses in Neural Conversation Models with Distributional Constraints
手动设计了用于排名的特征,并通过在主题分布或上下文嵌入和完成之间附加相似性分数来改变采样分布
有监督学习:(2018 ACL) Learning to Write with Cooperative Discriminators
采用了一组学习判别器,每个判别器专门研究以Cooperative principle为指导的不同沟通原则:质量、数量、关系和方式。鉴别器通过分别测量重复性、蕴含性、相关性和词汇多样性来学习编码这些所需的原则。给定一些基本事实完成,所有判别器模型都经过训练以最小化排名对数似然
log
σ
(
f
i
(
y
g
)
−
f
i
(
y
)
)
\log\sigma(f_i(y_g) - f_i(y))
logσ(fi(yg)−fi(y)),因为黄金延续
y
g
y_g
yg预计会获得比生成的
y
y
y更高的分数 。这里还学习了权重系数
α
i
\alpha_i
αi,以最小化黄金标准和生成的完成度之间的分数差异。判别性对抗搜索(DAS;(2020 ICML) Discriminative Adversarial Search for Abstractive Summarization)受到 GAN 的启发,训练判别器区分人类创建的文本和机器生成的文本。鉴别器预测每个标记的标签,而不是整个序列。判别器 logprob 被添加到分数中,以指导采样朝着人类书写的风格发展。
有监督学习:(2020 EMNLP) If beam search is the answer, what was the question?
研究了正则化解码框架中的beam search:
y
∗
=
arg
max
y
∈
Y
(
log
p
θ
(
y
∣
x
)
⏟
MAP
−
λ
R
(
y
)
⏟
regularizer
)
\mathbf{y}^* = \arg\max_{\mathbf{y}\in\mathcal{Y}} \big( \underbrace{\log p_\theta(\mathbf{y}\vert\mathbf{x})}_\text{MAP} - \underbrace{\lambda\mathcal{R}(\mathbf{y})}_\text{regularizer} \big)
y∗=argy∈Ymax(MAP
logpθ(y∣x)−regularizer
λR(y))
由于我们期望最大概率具有最小的意外,LM 在时间步上的意外可以定义如下:
u
0
(
BOS
)
=
0
; BOS is a placeholder token for the beginning of a sentence.
u
t
(
y
)
=
−
log
P
θ
(
y
∣
x
,
y
<
t
)
for
t
≥
1
\begin{aligned} u_0(\texttt{BOS}) &= 0 \text{ ; BOS is a placeholder token for the beginning of a sentence.}\\ u_t(y) &= -\log P_\theta(y \vert \mathbf{x}, \mathbf{y}_{<{t}}) \text{ for }t \geq 1 \end{aligned}
u0(BOS)ut(y)=0 ; BOS is a placeholder token for the beginning of a sentence.=−logPθ(y∣x,y<t) for t≥1
MAP(最大后验)部分要求序列在给定上下文的情况下具有最大概率,而正则化器引入了其他约束。全局最优策略可能偶尔需要有一个高意外步骤,以便它可以缩短输出长度或随后产生更多低意外步骤。
集束搜索在 NLP 领域已经经历了时间的考验。问题是:如果我们想在正则化解码框架中将波束搜索建模为精确搜索,应该如何建模?该论文提出了集束搜索和均匀信息密度(UID)假设之间的联系。
“统一信息密度假说(UID;Levy 和 Jaeger,2007)指出,受语法的限制,人类更喜欢在语言信号中均匀分布信息(信息论意义上的)的句子,例如,一个句子”。
换句话说,它假设人类更喜欢带有均匀分布的惊喜的文本。流行的解码方法(例如 top-k 采样或核采样)实际上会过滤掉高度意外的选项,从而隐式地鼓励输出序列中的 UID 属性。
强化学习:(2017) Learning to Decode for Future Success
8. Trainable Decoding
(2017) Trainable Greedy Decoding for Neural Machine Translation
最大化采样序列的任意目标。该想法基于噪声并行近似解码 (NPAD (2016) Noisy Parallel Approximate Decoding for Conditional Recurrent Language Model)。 NPAD 将非结构化噪声注入模型隐藏状态,并并行运行多次噪声解码以避免潜在的性能退化。更进一步,可训练的贪婪解码用可学习的随机变量替换非结构化噪声,由 RL 代理进行预测,该代理将先前的隐藏状态、先前解码的令牌和上下文作为输入。换句话说,解码算法学习 RL actor 来操纵模型隐藏状态以获得更好的结果。
(2019 NeurIPS) Bias Correction of Learned Generative Models using Likelihood-Free Importance Weighting
(2020 ICLR) Residual Energy-Based Models for Text Generation
9. 代码实践:transformers的generate()函数
我用GPT-2写了一篇代码示例,介绍了不同解码策略的实现方案。可参考:https://github.com/PolarisRisingWar/all-notes-in-one/blob/main/decode_examples_in_GPT2.ipynb
(注意pad_token_id那个只有GPT-2需要,别的模型大多不需要)
generate()生成的结果经decode()即可得到原始文本(output_text = tokenizer.decode(outputs[0], skip_special_tokens=True))
贪心搜索:greedy_output = model.generate(input_ids, max_length=50)
入参:
- max_length:包括context的总长度
- max_new_tokens
- num_beams:beam search的beam数
- early_stopping:设置num_beams时可用
在所有beam达到 EOS 时直接结束生成 - no_repeat_ngram_size:设置禁止ngram重复出现
原始论文:(2017) A Deep Reinforced Model for Abstractive Summarization
(2017) OpenNMT: Open-Source Toolkit for Neural Machine Translation - num_return_sequences:返回多少个独立采样的输出序列
- do_sample:根据概率采样
- top_k:对概率前k的token的概率重新归一化
- top_p:对大于p的token的概率重新归一化
- temperature:降低temperature会极化token概率,导致抽样随机性减小(当temperature→0时,抽样策略趋近于贪心搜索)
- min_length 用于强制模型在达到 min_length 之前不生成 EOS。这在摘要场景中使用得比较多,但如果用户想要更长的文本输出,也会很有用。
- repetition_penalty 可用于对生成重复的单词这一行为进行惩罚。它首先由 (2019) CTRL: A Conditional Transformer Language Model for Controllable Generation 引入,在 (2019) Neural Text Generation with Unlikelihood Training 的工作中,它是训练目标的一部分。它可以非常有效地防止重复,但似乎对模型和用户场景非常敏感,其中一个例子见 Github 上的 讨论。
- attention_mask 可用于屏蔽填充符。
- pad_token_id、bos_token_id、eos_token_id: 如果模型默认没有这些 token,用户可以手动选择其他 token id 来表示它们。
10. 其他注意事项
- (2019) Neural Text Generation with Unlikelihood Training
贪心和beam search容易生成重复的单词序列 - 是由模型 (特别是模型的训练方式) 引起的,而不是解码方法。
作者表明,根据人类评估,在调整训练目标后,beam search相比 Top-p 采样能产生更流畅的文本。 - top-K 和 top-p 采样也会产生重复的单词序列:(2020 EMNLP) Consistency of a Recurrent Language Model With Respect to Incomplete Decoding
11. 参考资料
- 如何生成文本:通过 Transformers 用不同的解码方法生成文本:我感觉这篇非常浅显易懂,内容也很全面
- Controllable Neural Text Generation | Lil’Log:guided decoding、trainable decoding论文分析没看完;在prompt后的内容与文本生成解码关系较弱,所以没有放在本文中阐释
- 图说文本生成解码策略 | Finisky Garden


















 236
236

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











